딥러닝 기반 이미지 분할 기술 이해
초록
본 논문은 전통적인 이미지 분할 방법에서 시작해, 최근 10년간 제안된 주요 딥러닝 기반 분할 알고리즘을 체계적으로 정리하고, 각 기법의 구조적 특징과 적용 분야를 직관적으로 설명한다. 또한, 대표적인 데이터셋과 성능 지표를 정리함으로써 연구자들이 현재 기술 수준을 한눈에 파악하고, 향후 연구 방향을 모색할 수 있도록 돕는다.
**
상세 분석
이 논문은 이미지 분할 분야를 크게 전통적 방법, 딥러닝 기반 방법, 그리고 응용 분야로 구분하고, 각 구간을 상세히 서술한다. 전통적 방법 섹션에서는 히스토그램 임계값, 영역 기반, 에지 검출, 클러스터링 등 고전적인 기법들을 언급하면서, 특징 추출이 인간 전문가에 의존한다는 한계를 지적한다. 이러한 한계는 딥러닝이 자동으로 추상적 특징을 학습함으로써 극복될 수 있음을 강조한다.
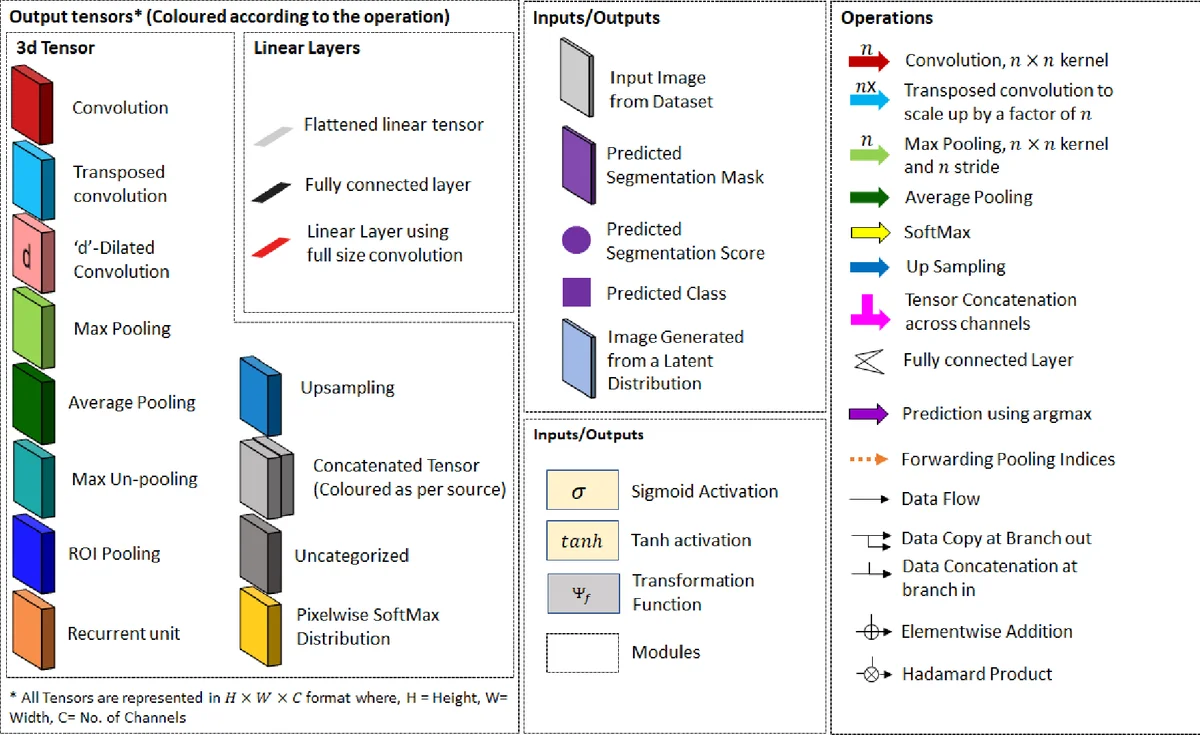
딥러닝 파트에서는 컨볼루션 신경망(CNN)의 기본 원리와, 레이어별 특징 추출 과정(초기 레이어는 로컬 컨투어, 깊은 레이어는 전역 객체) 을 시각화된 예시와 함께 설명한다. 특히 Fully Convolutional Network(FCN)를 시작으로, Encoder‑Decoder 구조(U‑Net, SegNet, ENet 등), 멀티스케일 피처 결합(PSPNet, DeepLab), 어트랙션 메커니즘(Attention‑to‑Scale, Mask RCNN), 그리고 최근의 캡슐 네트워크(SegCaps)와 대립 학습(Conditional GAN)까지 다양한 아키텍처를 연대기적으로 정리한다. 각 모델마다 supervision 형태(전통적 지도, 약지도, 무지도), 학습 목표(단일 목적, 다중 목적), 그리고 추가 모듈(CRF‑RNN, Spatial Propagation Network 등)을 표 형태로 제시해, 연구자가 설계 선택지를 빠르게 파악하도록 돕는다.
데이터셋 섹션은 자연 이미지(PASCAL VOC, COCO, Cityscapes 등), 의료 영상(DRIVE, LITS 등), 항공·위성 이미지(Mapillary Vistas, ISPRS 등) 등 도메인별 대표 데이터를 광범위하게 나열한다. 이는 딥러닝 기반 분할 모델이 데이터 규모와 다양성에 크게 의존한다는 점을 강조한다.
비판적으로 보면, 논문은 각 알고리즘의 정량적 성능 비교나 실험 재현성을 제공하지 않는다. 표에 제시된 성능 수치는 대부분 기존 논문에서 인용한 것이며, 동일한 평가 프로토콜 하에서의 직접 비교가 부족하다. 또한, 최신 트랜스포머 기반 분할 모델(ViT‑Seg, Segmenter 등)에 대한 언급이 없으며, 2020년 이후 급격히 성장한 경량화·실시간 모델(DeepLab v3+, HRNet 등)도 누락돼 있다. 이러한 점은 독자가 최신 흐름을 완전히 파악하는 데 제한이 될 수 있다.
마지막으로, 논문은 “왜 설계되었는가”라는 질문에 대한 메커니즘적 설명을 시도하지만, 수학적 공식이나 상세한 ablation study 없이 직관적 설명에 머무른다. 따라서 연구자가 새로운 모델을 설계할 때 구체적인 설계 원칙을 도출하기엔 다소 부족한 감이 있다. 전체적으로는 딥러닝 기반 이미지 분할 기술을 처음 접하는 독자에게 좋은 입문서가 되지만, 심층 연구를 위해서는 최신 문헌과 실험적 검증이 추가로 필요하다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기