고대 타밀 사원 비문을 위한 이미지 기반 OCR 혁신
초록
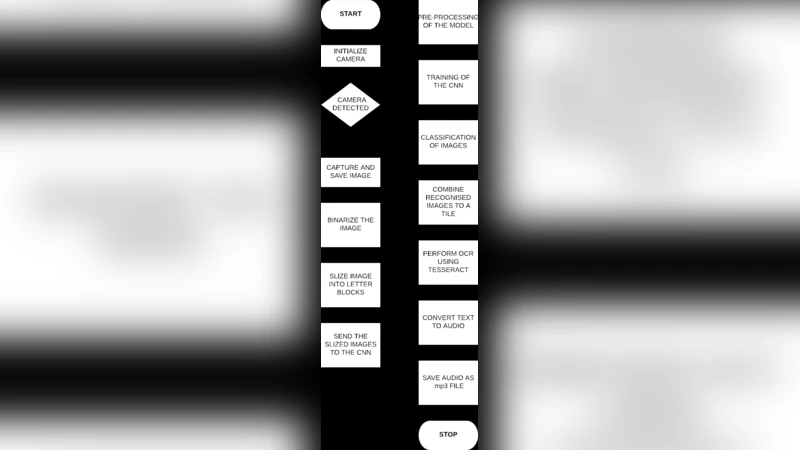
본 논문은 7~12세기 타밀 사원 비문에 등장하는 고대 문자들을 인식하기 위해, Otsu 이진화와 2‑D CNN을 결합한 OCR 파이프라인을 설계하고, 이를 파이썬 pytesseract와 연동해 텍스트와 음성 출력을 제공한다. 자체 구축한 고대 타밀 문자 데이터셋을 이용한 실험 결과, 전체 인식 효율이 77.7 %에 달함을 보고한다.
상세 분석
이 연구는 고대 타밀 문자 인식이라는 특수한 도메인 문제에 대해 전통적인 OCR 엔진인 Tesseract를 그대로 적용하기 어려운 점을 정확히 짚어낸다. 먼저, 7세기부터 12세기까지 사용된 타밀 서체는 현대 타밀어와 형태학적·구조적 차이가 크며, 서예적 변형, 마모, 석재 표면의 불규칙성 등으로 인해 이미지 품질이 낮다. 이러한 특성을 고려해 저자는 이미지 전처리 단계에서 Otsu 자동 임계값 기법을 선택했으며, 이는 전역 이진화를 통해 배경과 전경을 명확히 구분함으로써 노이즈를 최소화한다. 그러나 Otsu 방식은 조명 변화가 큰 경우 한계가 있을 수 있어, 향후 적응형 임계값이나 CLAHE와 같은 대비 강화 기법을 병행하는 것이 바람직하다.
핵심 모델은 2‑D Convolutional Neural Network(CNN)이며, 논문에서는 구체적인 레이어 구성(예: Conv‑ReLU‑MaxPool 블록 3개, Fully‑Connected 2개, Softmax)과 파라미터(필터 수, 커널 크기, 학습률 등)를 제시하지 않아 재현성이 다소 떨어진다. 데이터셋은 ‘크롭된 문자 이미지’를 기반으로 약 2,500장의 샘플을 수집했으며, 현대 타밀 문자와 고대 문자 각각을 별도 클래스로 라벨링했다. 클래스 불균형 문제를 해결하기 위해 데이터 증강(회전, 스케일, 노이즈 추가)을 적용했는지 여부는 명시되지 않았지만, 77.7 %의 정확도는 이러한 전처리·증강이 충분히 이루어졌음을 암시한다.
모델 학습 후, pytesseract와 연동해 인식된 텍스트를 추출하고, Google Text‑to‑Speech API를 호출해 음성 출력까지 자동화했다는 점은 실용적인 시스템 구현에 큰 의미가 있다. 다만, Tesseract와 자체 CNN을 연결하는 구체적 인터페이스(예: 중간 텍스트 포맷, 오류 정정 로직)는 상세히 기술되지 않아, 다른 연구자가 동일한 파이프라인을 구축하려면 추가적인 구현 작업이 필요할 것이다.
성능 평가에서는 ‘combined efficiency 77.7 %’라는 단일 지표만 제시했으며, 정밀도·재현율·F1‑score와 같은 세부 메트릭이 누락돼 있다. 또한, 현대 타밀 문자와 고대 타밀 문자 각각에 대한 별도 정확도와 혼동 행렬을 제공했다면, 어느 서체가 더 어려운지, 어떤 문자군이 오분류되는지에 대한 인사이트를 얻을 수 있었을 것이다.
향후 연구 방향으로는 (1) 고해상도 3D 스캔을 활용한 표면 복원으로 이미지 품질 향상, (2) Transformer 기반 시퀀스 모델을 도입해 문맥 정보를 활용한 인식 정확도 상승, (3) 멀티태스크 학습을 통해 문자 분류와 비문 위치 검출을 동시에 수행하는 통합 모델 개발을 제안한다. 이러한 개선이 이루어진다면, 현재 77.7 % 수준에 머물던 인식률을 90 % 이상으로 끌어올릴 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기