코드 주석에서 알고리즘 명칭 자동 추출 방법 연구
초록
본 논문은 FLOSS 프로젝트의 코드 주석에 나타나는 “… algorithm” 형태의 N‑gram을 추출하고, 품사 태깅 기반 규칙을 적용해 알고리즘 명칭을 자동으로 식별하는 방법을 제안한다. N‑gram IDF와 포괄·배제 규칙을 결합한 파이프라인을 구축하고, 1,581개의 후보 N‑gram을 대상으로 정밀도 0.76, 재현율 0.70, F‑measure 0.73을 달성하였다. 이후 7개 언어( C, C++, Java, JavaScript, Python, PHP, Ruby)에서 수십만 개의 주석을 분석해 검색, 암호화, 정렬 등 주요 알고리즘의 사용 빈도를 보고한다.
상세 분석
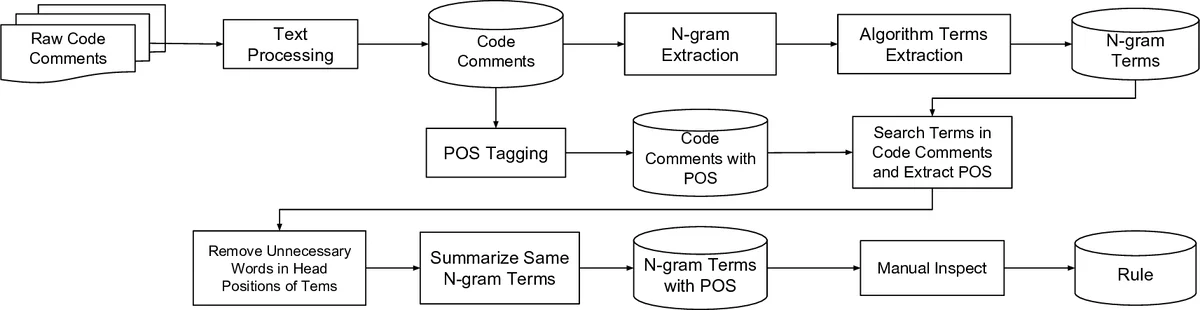
이 연구는 소프트웨어 공학과 자연어 처리(NLP)를 접목한 실용적 데이터 마이닝 사례로, 크게 네 단계의 파이프라인을 설계한다. 첫 번째 단계는 GitHub에 공개된 FLOSS 저장소에서 코드 주석을 수집하고, 특수 문자와 마크업을 제거한 뒤 spaCy 기반 품사 태거를 적용한다. 두 번째 단계에서는 “algorithm”이라는 키워드가 마지막에 위치하는 N‑gram을 추출하기 위해 N‑gram IDF 기법을 활용한다. N‑gram IDF는 전통적인 TF‑IDF를 확장한 개념으로, 문서 전체에서 드물게 등장하지만 특정 N‑gram 내에서 중요한 토큰을 강조한다. 이를 통해 “quick sort algorithm”, “search algorithm” 등 후보 구문을 얻는다.
세 번째 단계는 후보 구문에서 의미 없는 선행어를 제거하는 전처리이다. 논문은 불필요한 선행어를 품사 패턴(동사, 전치사, 숫자, 관사 등)으로 정의하고, 표 1에 제시된 규칙에 따라 재귀적으로 삭제한다. 예를 들어 “quick sort algorithm”에서 “quick”은 형용사이지만 “sort algorithm”이 더 긴 유효 구문이므로 최종 선택된다.
네 번째 단계는 포괄(Inclusive)과 배제(Exclusive) 규칙을 자동 생성하는 과정이다. 후보 구문별 품사 시퀀스를 집계하고, 다수결 원칙에 따라 주요 품사 조합을 결정한다. 이후 수작업으로 유효·무효 라벨링을 수행해, 유효 구문이 더 많을 경우 포괄 규칙에, 반대이면 배제 규칙에 포함시킨다. 알고리즘 1은 이러한 규칙을 코드 수준에서 적용하는 절차를 상세히 제시한다.
평가에서는 1,581개의 N‑gram 중 458개의 중복을 제거한 뒤, 저자들이 만든 오라클과 비교해 정밀도 0.76, 재현율 0.70, F‑measure 0.73을 기록했다. 이는 “algorithm”이라는 고정 어미에 의존하면서도 품사 기반 필터링을 통해 잡음(예: “learning algorithm”, “legacy algorithm”)을 효과적으로 배제했음을 의미한다.
대규모 적용 결과는 각 언어별로 수천 개의 저장소(예: Java 4,995개, JavaScript 7,130개)에서 추출된 주석을 대상으로, 상위 10개 알고리즘을 빈도 순으로 정리하였다. 검색, 암호화, 정렬, 해시 등 보안·데이터 처리 관련 알고리즘이 C와 PHP, JavaScript 등에서 두드러졌으며, 웹 관련 알고리즘은 JavaScript와 PHP에서 많이 등장한다. 표 6은 실제 코드 주석 예시를 제시해, 추출된 알고리즘 명칭이 실제 구현과 직접 연결될 수 있음을 보여준다.
위험도 분석에서는 규칙 생성에 사용된 초기 데이터가 제한적이라는 내부 타당성 위협과, GitHub 기반 FLOSS 저장소만을 대상으로 했다는 외부 타당성 위협을 언급한다. 그러나 대규모 실험에서 얻은 높은 정밀도와 재현율은 규칙의 일반화 가능성을 어느 정도 뒷받침한다.
본 연구의 주요 기여는 (1) 알고리즘 명칭을 자동으로 식별하는 규칙 기반 방법론 제시, (2) N‑gram IDF와 품사 패턴을 결합해 높은 정확도 달성, (3) 7개 언어에 걸친 대규모 FLOSS 주석 분석을 통해 실무에서 자주 사용되는 알고리즘 분포를 제공한다는 점이다. 향후 연구에서는 알고리즘 명칭 사전 구축, 다국어 주석 처리, 그리고 추출된 데이터를 활용한 자동 주석 생성 및 코드 검색 시스템에의 연계가 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기