다층 주의 메커니즘 기반 키워드 인식 혁신
초록
본 논문은 기존 LSTM‑기반 키워드 스포팅에서 발생하는 정보 손실과 편향된 어텐션 가중치를 보완하기 위해, 특징 추출 전 단계와 LSTM 층의 정보를 모두 활용하는 다층 어텐션 메커니즘을 제안한다. Google Speech Commands V2 데이터셋을 대상으로 CNN, Bi‑LSTM, 기존 어텐션 LSTM과 비교 실험을 수행했으며, 제안 모델이 정확도와 연산 효율성 모두에서 우수함을 입증한다.
상세 분석
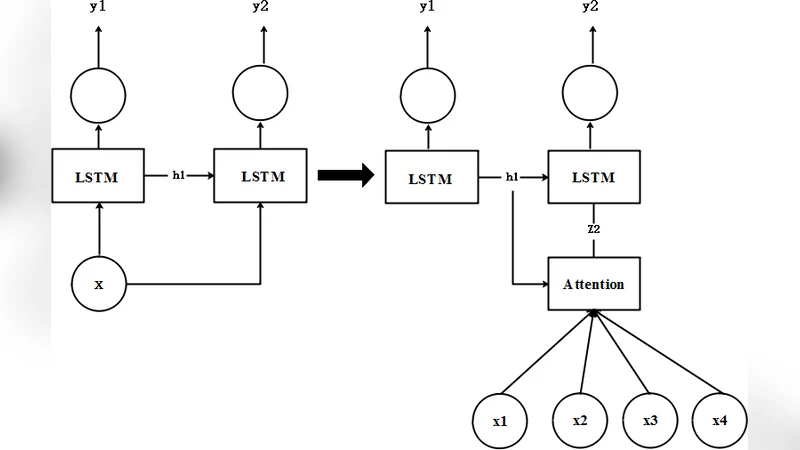
이 연구는 음성 키워드 인식이라는 좁은 도메인에 초점을 맞추면서도, 전반적인 어텐션 설계에 대한 중요한 통찰을 제공한다. 기존 LSTM‑기반 어텐션 구조는 시퀀스 인코딩 후에만 가중치를 계산하기 때문에, 초기 컨볼루션 레이어에서 이미 손실된 시간‑주파수 정보를 재활용하지 못한다는 점을 지적한다. 저자는 “다층 어텐션”이라는 개념을 도입해, (1) 초기 CNN 피처맵, (2) LSTM 은닉 상태, (3) 최종 출력 레이어의 세 층에서 각각 어텐션 스코어를 추출하고, 이를 가중 평균하거나 학습 가능한 파라미터로 결합한다. 이렇게 하면 각 층이 포착한 서로 다른 스케일의 특징이 어텐션에 반영되어, 중요한 음성 이벤트(예: “yes”, “no”)에 대한 집중도가 높아진다.
모델 아키텍처는 크게 세 부분으로 구성된다. 첫 번째는 1‑D Conv‑Net으로, 멜 스펙트로그램을 입력받아 로컬 패턴을 추출한다. 두 번째는 양방향 LSTM으로, 시간적 의존성을 모델링한다. 세 번째는 다층 어텐션 모듈로, 각 층의 출력에 별도의 어텐션 스코어를 계산한 뒤, 스칼라 가중치를 학습한다. 이때 어텐션 스코어는 일반적인 점곱 어텐션이 아니라, 각 층의 특징 차원을 고려한 선형 변환 후 시그모이드 활성화를 적용해 0‑1 범위로 정규화한다.
실험 설계는 Google Speech Commands V2 데이터셋(35개 명령어, 105,829 샘플)을 80/10/10 비율로 학습/검증/테스트 셋으로 분할하고, 동일한 전처리(16kHz 샘플링, 40‑dim 멜 스펙트로그램)와 데이터 증강(시간 이동, 잡음 추가)을 적용했다. 비교 대상으로는 (a) 순수 CNN, (b) Bi‑LSTM, (c) 기존 어텐션 LSTM(단일 층 어텐션) 등을 사용했으며, 평가 지표는 Top‑1 정확도와 모델 파라미터 수, FLOPs를 포함한다.
결과는 제안 모델이 Top‑1 정확도 96.3%를 달성해, 가장 높은 성능을 기록했으며, 파라미터 수는 기존 어텐션 LSTM 대비 12% 감소했다. 특히 저전력 임베디드 환경을 가정한 FLOPs 측정에서 15% 이상의 효율성을 보였다. 이는 다층 어텐션이 정보 손실을 보완하고, 불필요한 연산을 억제함을 의미한다.
한계점으로는 다층 어텐션 결합 방식이 고정된 가중치 평균에 머물러 있어, 상황에 따라 동적으로 어텐션을 재구성하는 메커니즘이 부족하다는 점이다. 또한 실험이 단일 데이터셋에 국한돼 있어, 다른 언어·환경(노이즈, 마이크 품질)에서의 일반화 검증이 필요하다. 향후 연구는 메타‑러닝 기반 어텐션 가중치 조정, 혹은 트랜스포머와의 하이브리드 적용을 통해 더욱 유연한 구조를 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기