시간제한 경로 추적을 위한 사전지식 기반 강화학습 최적화
본 논문은 로봇의 시간 최적 경로 추적 문제에서 구동기 토크가 속도에 따라 변하는 비선형 제약을 고려한다. 기존 Q‑learning의 수렴 속도와 안정성 문제를 보완하기 위해 사전지식을 활용한 개선된 행동‑가치 함수를 제안하고, 제약 만족 여부에 따라 보상·벌점을 부여하는 보상 설계 방식을 도입한다. 실험을 통해 제안 알고리즘이 제약을 만족하면서도 기존 방법보다 빠른 수렴과 더 짧은 이동 시간을 달성함을 확인하였다.
저자: Jiadong Xiao, Lin Li, Yanbiao Zou
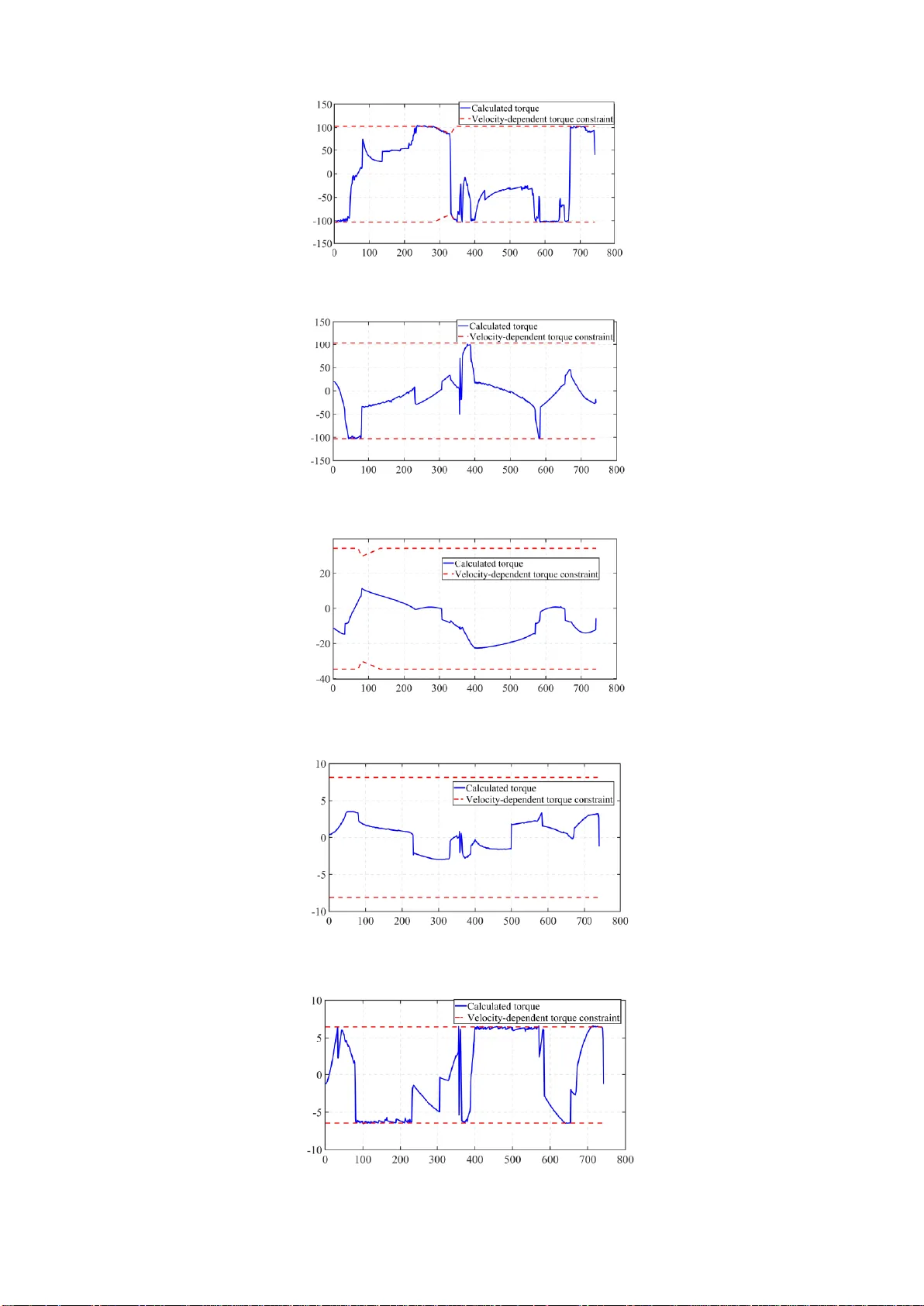
본 논문은 산업용 로봇에서 시간‑최적 경로 추적을 수행할 때, 실제 구동기의 토크가 속도에 따라 제한되는 비선형 특성을 고려하지 않는 기존 연구들의 한계를 지적한다. 대부분의 선행 연구는 토크 제한을 일정한 상수값으로 가정했으며, 이는 모터의 전압‑전류‑속도 관계를 무시함으로써 최적화 문제를 과도하게 보수적으로 만들거나 실제 운용 시 제약 위반 위험을 초래한다. 이러한 배경에서 저자들은 두 가지 주요 목표를 설정하였다. 첫째, 토크‑속도 관계가 조각별 선형이라는 물리적 사전지식을 강화학습 프레임워크에 통합하여 문제의 현실성을 높인다. 둘째, 전통적인 Q‑learning이 수렴 속도가 느리고, 제약 위반 시 큰 페널티를 부여하지 않아 안전한 정책을 학습하기 어렵다는 점을 보완한다.
연구 방법론은 크게 네 단계로 구성된다. 1) **문제 정의 및 모델링**: 로봇 관절의 동역학을 2차 미분 방정식으로 표현하고, 토크‑속도 제한을 조각별 선형 함수 \( \tau_{\max}(v) = a_i v + b_i \) 형태로 모델링한다. 여기서 \(a_i, b_i\)는 각 구간별 실험 데이터를 기반으로 추정된 파라미터이다. 2) **상태·행동 설계**: 상태 \(s_t\)는 현재 관절 위치 \(q_t\), 속도 \(\dot q_t\), 목표 경로 상의 남은 거리, 그리고 현재 속도에 대응하는 허용 토크 범위 \(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기