계층적 깊이 강화학습 기반 다중에이전트 협동
초록
본 논문은 보상이 희소하고 지연되는 협동 다중에이전트 환경에서 시간 추상화를 도입한 계층적 구조를 제안한다. 고수준 목표와 저수준 스킬을 각각 학습하도록 두 단계로 나누고, 독립 학습(h‑IL), 통신 기반 학습(h‑Comm), Q‑mix 기반 학습(h‑Qmix)이라는 세 가지 아키텍처를 설계한다. 또한 고수준 전이의 희소성을 완화하고 비정상성을 감소시키는 Augmented Concurrent Experience Replay(ACER)를 도입한다. 실험은 다중에이전트 쓰레기 수거와 모바일 게임 ‘Fever Basketball Defense’에서 수행돼, 제안 방법이 기존 MARL 대비 뛰어난 성능을 보임을 입증한다.
상세 분석
이 연구는 기존 다중에이전트 강화학습(MARL)이 직면한 두 가지 핵심 문제—환경의 비정상성 및 정책 공간의 급격한 확장—에 더해 보상이 희소하고 지연되는 상황을 동시에 고려한다. 이를 해결하기 위해 시간 추상화(temporal abstraction)를 활용, 문제를 고수준 목표와 저수준 행동으로 분리하는 두 단계 계층 구조를 제안한다. 고수준 목표는 반마르코프 게임 형태로 모델링되어 여러 타임스텝에 걸쳐 실행되며, 저수준 정책은 목표에 조건화된 MDP로 정의된다. 이러한 설계는 에이전트가 복잡한 장기 목표를 달성하기 위해 필요한 기본 스킬을 독립적으로 학습하도록 하면서, 고수준에서는 협동 전략을 집중적으로 학습하도록 만든다.
세 가지 계층형 아키텍처는 각각 다른 MARL 패러다임에 맞추어 설계되었다. 첫 번째인 계층적 독립 학습(h‑IL)은 각 에이전트가 고수준·저수준 정책을 완전히 독립적으로 학습한다. 이는 구현이 간단하고 동기·비동기 종료 모델 모두에 적용 가능하지만, 전역 정보를 활용하지 못해 협동 효율이 제한될 수 있다. 두 번째인 h‑Comm은 CommNet에서 영감을 받아 고수준 단계에서 에이전트 간 숨겨진 상태를 평균화하는 방식으로 희소한 통신을 학습한다. 이를 통해 에이전트는 목표 선택 시 타 에이전트의 의도를 고려할 수 있어 협동이 강화된다. 세 번째인 h‑Qmix은 Q‑mix 구조를 차용해 고수준 행동 가치들을 단조성(monotonicity) 제약 하에 혼합함으로, 중앙집중식 훈련은 유지하면서 실행 시에는 분산 정책을 사용할 수 있게 한다. 이 경우 동기 종료 모델에 자연스럽게 맞으며, 비동기 상황에서는 전이 정렬을 위한 추가 트림이 필요하다.
계층형 학습의 또 다른 병목은 고수준 전이가 매우 드물어 경험 재생 효율이 낮아지는 점이다. 이를 해결하기 위해 제안된 ACER는 (1) 고수준 전이를 저수준 서브 전이들로 보강해 경험 밀도를 높이고, (2) 여러 에이전트의 전이를 동시에 샘플링해 비정상성에 의한 오차를 감소시킨다. 보조 전이들을 삽입함으로써 고수준 정책이 더 자주 업데이트될 수 있으며, 동시 샘플링은 과거 경험이 현재 정책과 크게 다를 경우 발생하는 편향을 완화한다.
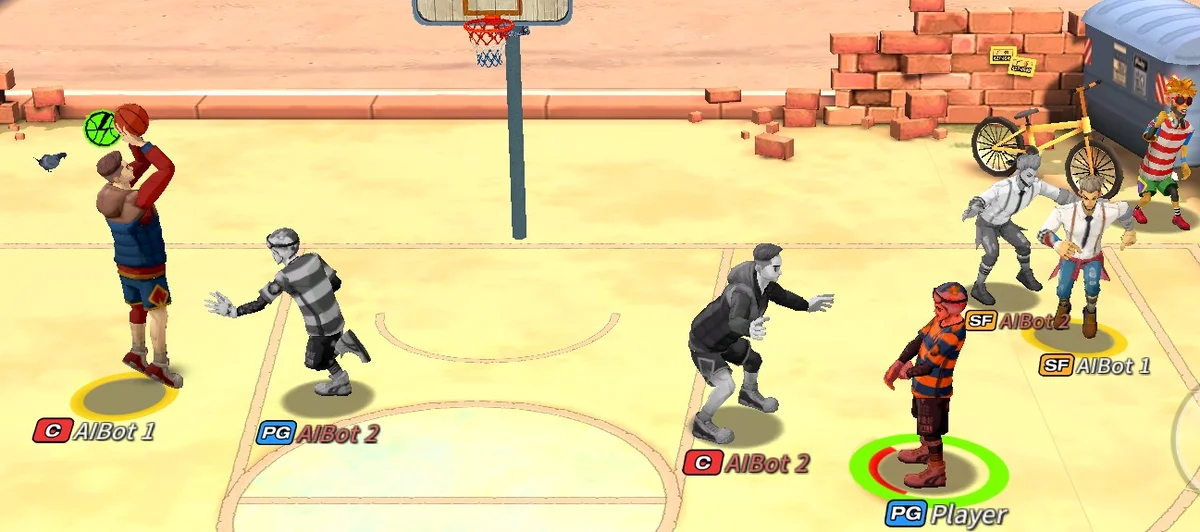
실험은 두 도메인에서 수행되었다. 첫 번째는 다양한 쓰레기 수거 시나리오로, 에이전트가 각각 쓰레기를 집어 들고 지정된 위치에 배달해야 하는 과제로, 보상이 목표 달성 시에만 주어지는 매우 희소한 설정이다. 여기서 h‑Comm과 h‑Qmix이 h‑IL보다 현저히 빠른 수렴과 높은 성공률을 보였으며, ACER를 적용했을 때 학습 속도가 추가로 가속화되었다. 두 번째는 온라인 모바일 게임 ‘Fever Basketball Defense’로, 여러 방어 에이전트가 협력해 상대의 슛을 차단해야 하는 복잡한 환경이다. 이 게임은 보상이 경기 종료 시점에만 주어지는 장기 지연 보상 특성을 가지고 있어 기존 MARL이 거의 학습에 실패한다. 제안된 계층형 구조와 ACER를 결합한 모델은 안정적으로 방어 전략을 학습해, 기존 방법 대비 승률을 크게 향상시켰다.
전체적으로 이 논문은 (1) 계층적 시간 추상화를 통한 MARL의 스케일링 및 희소 보상 처리, (2) 다양한 협동 패러다임에 맞는 세 가지 구체적 아키텍처 설계, (3) 경험 재생 효율을 높이는 ACER 메커니즘이라는 세 축으로 기존 연구의 한계를 극복한다는 점에서 의미가 크다. 특히 고수준·저수준 정책을 동시에 학습하면서도 비정상성을 완화하는 방법론은 향후 복잡한 실세계 다중로봇 시스템이나 대규모 게임 AI에 직접 적용 가능할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기