음성 표현 인식을 위한 음향·패럴링귀스틱 임베딩 활용
초록
본 연구는 디지털 어시스턴트 질의에서 텍스트만으로는 파악하기 어려운 ‘표현(감정·톤)’을 음성 신호의 음향 및 패럴링귀스틱 특성을 이용해 자동으로 감지하는 방법을 제안한다. 100시간 규모의 미국 영어 음성 데이터에 인간 채점자가 부여한 표현 여부와 원시 감정(활동성·가치) 라벨을 활용해 MFCC, GCC, NMCC 등 다양한 스펙트럼 특징과 F0‑V 피치·보이스 특성, 그리고 발성기관 수축 변수(TV)를 추출하였다. LSTM 기반 모델로 각각의 임베딩을 학습하고, 감정 임베딩을 결합한 다중 임베딩 융합 네트워크를 구축하였다. 실험 결과, 텍스트 기반 Bag‑of‑Words 모델 대비 EER을 60 % 감소시켰으며, 감정 임베딩을 추가함으로써 추가 30 %의 상대적 EER 감소를 달성하였다.
상세 분석
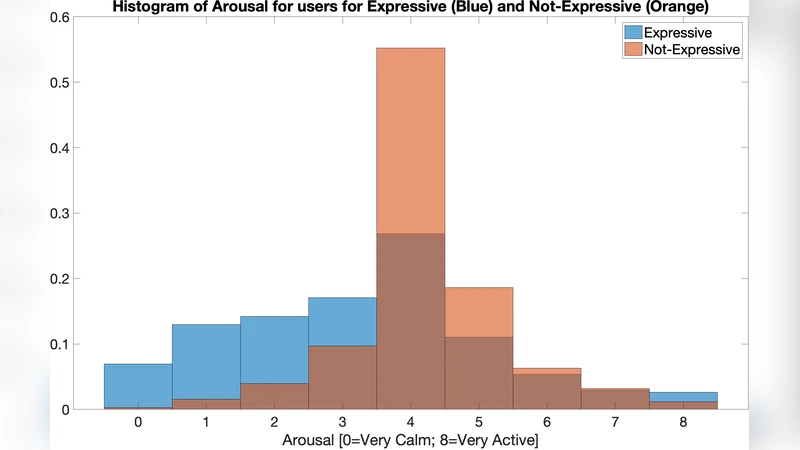
이 논문은 기존 SLU(Spoken Language Understanding) 시스템이 텍스트 전사에만 의존해 사용자의 의도를 파악하는 한계를 지적하고, ‘어떻게 말했는가’라는 패럴링귀스틱 정보를 활용함으로써 표현 기반 의도 구분을 강화하고자 한다. 데이터는 화자·문맥 정보를 배제한 100시간(≈70시간 정제) 음성 샘플에 4명의 채점자가 ‘표현 여부(Yes/No/Not sure)’와 3‑레벨 리커트 척도의 원시 감정(활동성·가치)을 부여한 형태이며, 평균값을 실수형 라벨로 변환해 회귀식 학습에 이용하였다.
특징 추출 단계에서 MFCC(20차원) 외에 GCC, NMCC와 같은 변조 계수, 그리고 F0‑V(피치·피치 변화·보이스) 3차원을 결합해 23차원 특징을 구성하였다. 특히 발성기관 수축 변수(TV) 8차원을 LSTM 기반 음성‑투‑TV 변환 모델을 통해 추정했으며, 이는 원시 감정(특히 가치)과 양의 상관관계를 보였다.
모델링은 단일 레이어 LSTM(128 hidden)으로 음성 표현 검출을 수행하고, 별도로 감정(활동성·가치) 예측을 위한 LSTM(64 hidden) 회귀 모델을 학습하였다. 두 모델에서 추출한 임베딩을 128‑노드 피드포워드 네트워크에 입력해 최종 표현 점수를 예측했으며, 학습 과정에서는 클래스 불균형을 완화하기 위해 전체 데이터와 균형 잡힌 서브셋을 각각 pre‑training·fine‑tuning 단계에 사용하였다.
실험 결과는 네 가지 관점에서 제시된다. 첫째, 텍스트 기반 BoW‑DNN은 EER 47.46 %와 가중 정확도 52.79 %에 그쳐 거의 무작위 수준이었다. 반면 MFCC‑LSTM은 EER 29.05 %와 WA 65.34 %를 기록, 음향 정보가 표현 인식에 핵심임을 증명한다. 둘째, 피치·보이스(F0‑V)를 결합한 MFCC+F0‑V, GCC+F0‑V, NMCC+F0‑V는 각각 EER을 28.23 %~27.11 %까지 낮추고 WA를 72 %~73.5 %까지 끌어올렸다. 셋째, 감정 임베딩을 추가한 AE+EE 융합 모델은 최종 EER 18.84 %를 달성, 단일 음향 임베딩 대비 30 % 이상 개선되었다. 넷째, TV 기반 감정 모델은 가치와 활동성에 대해 각각 CCC 0.40, 0.66을 기록, 발성기관 정보가 감정(특히 가치) 추정에 유의미함을 보여준다.
전체적으로 이 연구는 (1) 음향·피치·보이스 등 저수준 음성 특성이 표현 감지를 가능하게 함, (2) 원시 감정 정보가 표현 라벨과 높은 상관관계를 가지며, (3) 발성기관 수축 변수와 같은 고차원 패럴링귀스틱 특성이 감정·표현 모델을 강화한다는 세 가지 핵심 인사이트를 제공한다. 또한, EER 기준 60 % 이상의 상대적 감소는 실제 디지털 어시스턴트 서비스에 적용 시 의도 분류 정확도를 크게 향상시킬 잠재력을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기