다양한 데이터 서브셋을 이용한 희소 표현 융합 기반 강인 분류
초록
본 논문은 협업 표현(Collaborative Representation)을 기반으로, 훈련 샘플을 무작위로 여러 개의 다양하고 독립적인 서브셋으로 나눈 뒤 각각에 대해 폐쇄형 해를 이용해 재구성 계수를 구하고, 이들 서브셋에서 얻은 잔차를 융합하여 최종 분류 결정을 내리는 SRFDS(Sparse Representation Fusion on Diverse Subsets) 방법을 제안한다. 서브셋 기반의 다중 표현을 통해 샘플 집합의 내재적 불확실성을 감소시키고, 계산 효율성을 유지하면서 기존 SR·CR 기반 방법보다 높은 정확도와 견고성을 달성한다.
상세 분석
SR(희소 표현) 기반 분류는 테스트 샘플을 전체 훈련 샘플의 선형 결합으로 표현하고, 클래스별 재구성 잔차를 최소화하는 방식으로 라벨을 결정한다. 전통적인 SR은 ℓ₁ 규제를 통해 진정한 희소성을 강제하지만, 최적화 과정이 반복적이며 계산 비용이 크게 증가한다. 반면 ℓ₂ 규제를 적용한 협업 표현(CR)은 폐쇄형 해를 제공해 연산 속도를 크게 높이지만, 희소성 제약이 없기 때문에 경우에 따라 분류 성능이 저하될 수 있다.
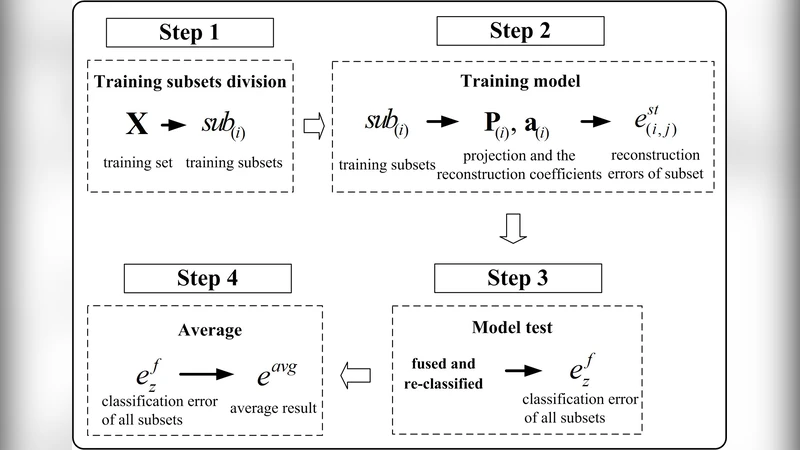
논문은 이러한 두 접근법의 장점을 결합하고, 추가적으로 “샘플 집합의 불확실성”을 고려한다. 불확실성은 (1) 측정 노이즈, (2) 훈련 샘플 자체가 특정 조건에서만 관찰되는 확률적 변동성으로 정의된다. 기존 방법들은 전체 훈련 집합을 하나의 고정된 데이터베이스로 취급해 이 변동성을 무시한다. 저자는 이를 보완하기 위해 훈련 데이터를 무작위로 여러 서브셋으로 분할한다. 각 서브셋은 전체 클래스 비율을 유지하면서도 서로 독립적인 샘플 구성을 갖는다. 구체적으로 기본 설정에서는 4개의 서브셋을 생성하고, 각 클래스당 절반·절반 혹은 1/3·2/3 비율로 샘플을 할당한다.
각 서브셋에 대해 CR의 폐쇄형 해
\
댓글 및 학술 토론
Loading comments...
의견 남기기