라디오 방송 아카이브 대규모 화자 다이어리제이션 및 연결 연구
본 논문은 1950‑2016년 사이에 녹음된 네덜란드 라디오 방송 아카이브(3000시간, 6500테이프)를 대상으로 두 단계(테이프 수준 다이어리제이션 → 화자 연결) 방식의 대규모 화자 다이어리제이션 시스템을 구축하고, x‑vector와 PLDA 기반 화자 연결 기법을 평가한다. 82개의 부분적으로 주석된 테이프(총 53시간)를 기준으로 DER 및 화자·클러스터 불순도를 측정했으며, 전체 아카이브(3000시간)에서도 확장성을 검증한다. 실험 …
저자: Emre Y{i}lmaz, Adem Derinel, Zhou Kun
본 논문은 네덜란드의 지역 공영 방송인 Omrop Fryslân이 보유한 방대한 라디오 아카이브를 대상으로, 대규모 화자 다이어리제이션 및 화자 식별 시스템을 구축하고 평가한다. 아카이브는 1950년대부터 2016년까지 녹음된 6500여 개 테이프, 총 3000시간 이상의 프리시안‑네덜란드 이중언어 음성 데이터를 포함한다. 이러한 데이터는 시간적·언어적 다양성(방언, 코드스위칭)과 방대한 규모 때문에 기존의 단일 단계 다이어리제이션 기법을 적용하기 어렵다. 따라서 저자들은 두 단계 접근법을 설계하였다.
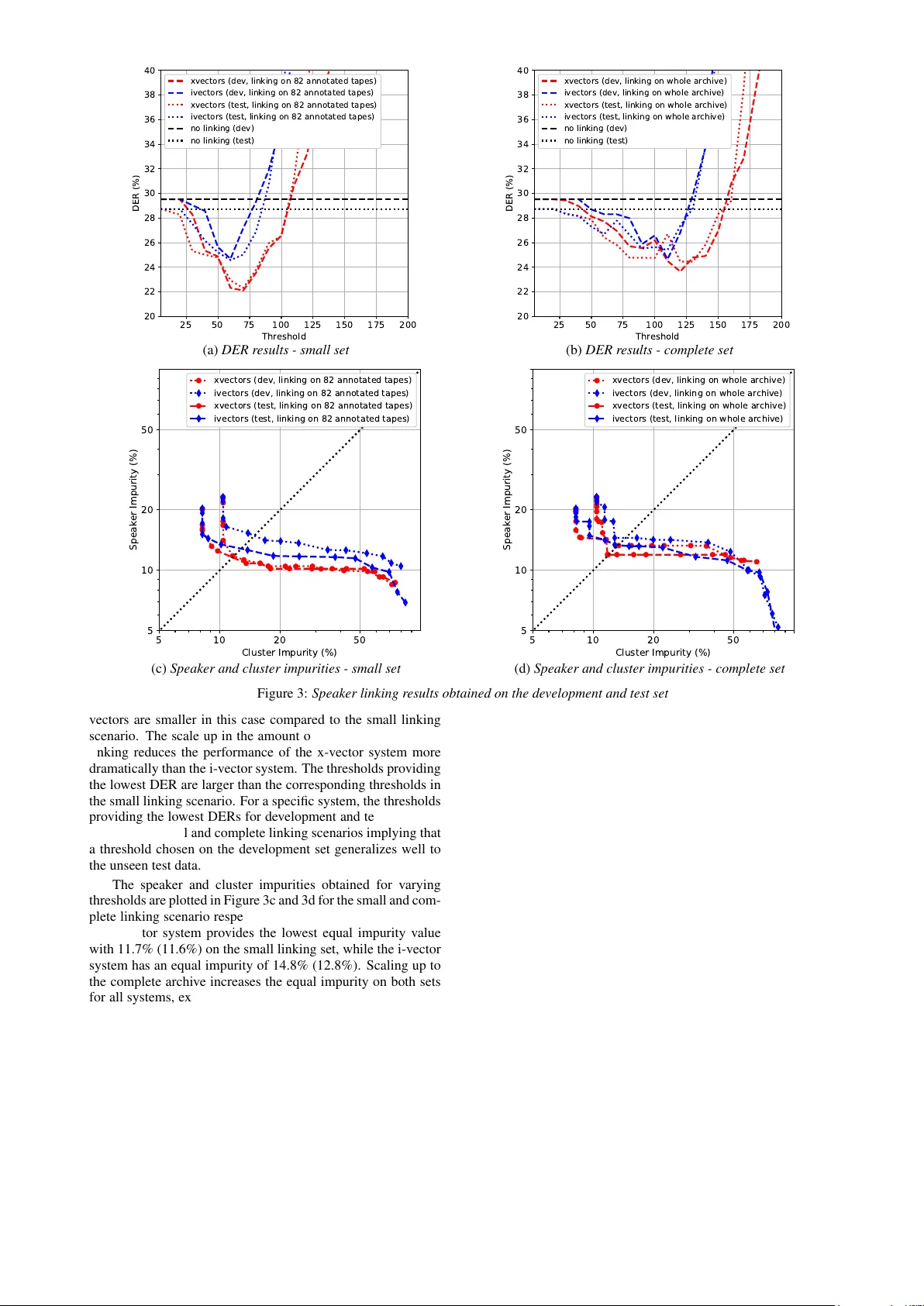
첫 번째 단계는 ‘테이프 수준 다이어리제이션’이다. 공개된 LIUM 툴킷(v8.4.1)을 활용해 각 테이프를 독립적으로 다이어리제이션한다. 이 과정은 BIC 기반 음성 구분과 GMM‑CLR 클러스터링을 결합해 화자 수를 다소 과대 추정하도록 설정한다. 과대 추정은 이후 단계에서 화자를 병합할 때 잘못된 병합을 방지하는 안전장치 역할을 한다. 82개의 부분 주석 테이프(총 53시간)에서는 평균 19.6%의 DER을 달성했으며, 338개의 pseudo‑speaker가 215개의 실제 화자를 대체했다.
두 번째 단계는 ‘화자 연결 및 식별’이다. 첫 단계에서 얻은 pseudo‑speaker 라벨을 기반으로, 동일 라벨에 속하는 모든 발화를 하나의 오디오 파일로 병합한다. 10초 미만의 짧은 클립은 제거해 최소 발화량을 확보한다. 이어서 Kaldi 툴킷을 이용해 i‑vector와 x‑vector를 각각 추출한다. i‑vector는 600차원, x‑vector는 512차원이며, 두 경우 모두 20개의 MFCC(Δ, ΔΔ 포함)를 10 ms 프레임 간격으로 사용한다. PLDA 모델은 NIST SRE 2016 및 기존 SRE 코퍼스(증강 포함)로 학습했으며, 모든 화자 쌍에 대해 유사도 행렬을 계산한다.
유사도 행렬을 바탕으로 SciPy의 완전 연결(complete‑linkage) 계층적 군집화를 적용한다. 클러스터링 임계값을 조정해 다양한 연결 수준을 실험했으며, 최적 임계값은 i‑vector에서 60, x‑vector에서 70으로 확인되었다. 이때 작은 데이터셋(53시간)에서는 i‑vector가 24.7%/24.6% (개발/테스트), x‑vector가 22.1%/22.3%의 DER을 기록했다. 전체 아카이브(3000시간)에서는 각각 24.7%/25.4%와 23.7%/24.5%로 약간 상승했으며, 이는 데이터 규모 확대에 따른 화자 변이와 방언·언어 교체가 PLDA 기반 유사도 측정에 추가적인 불확실성을 야기했기 때문이다.
성능 평가는 DER 외에도 ‘화자 불순도’와 ‘클러스터 불순도’를 사용했다. 화자 불순도는 하나의 클러스터에 포함된 실제 화자 수를, 클러스터 불순도는 하나의 화자가 여러 클러스터에 분산된 정도를 나타낸다. x‑vector 기반 시스템이 두 지표 모두에서 i‑vector보다 낮은 값을 보였으며, 이는 딥러닝 기반 임베딩이 억양·방언 차이를 더 정교하게 포착한다는 점을 시사한다.
본 연구의 주요 기여는 다음과 같다. 첫째, 프리시안‑네덜란드 이중언어와 70년 이상의 시간跨度을 갖는 대규모 방송 아카이브를 위한 다이어리제이션 코퍼스를 구축하고 상세히 기술하였다(비공개이지만 재현 가능하도록 설명). 둘째, 두 단계 파이프라인을 구현해 실제 운영 환경에서의 확장성을 검증하였다. 셋째, x‑vector와 PLDA 기반 화자 연결이 대규모, 다언어, 장기 아카이브에 효과적임을 실증하였다.
향후 연구 방향으로는 (1) 도메인 적응 기법을 도입해 프리시안과 네덜란드 각각에 특화된 PLDA 모델을 학습하고, (2) 코드스위칭 구간을 별도로 처리하는 멀티태스크 학습을 적용해 언어 전환에 따른 임베딩 변동을 감소시키며, (3) 그래프 기반 클러스터링이나 베이지안 비지도 학습을 활용해 현재 관찰된 스케일링 손실을 최소화하는 방안을 모색할 수 있다. 이러한 개선은 방송 아카이브의 검색 가능성을 높이고, 역사적 언어·문화 연구에 중요한 기반 데이터를 제공할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기