DenseNet 기반 음악 분류와 데이터 증강 기법
초록
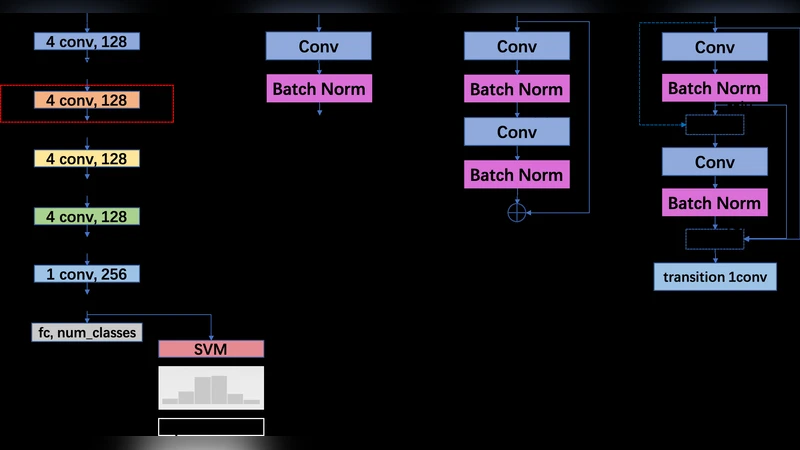
본 논문은 음악 오디오 태깅에 최초로 DenseNet을 적용하고, 시간 중첩과 피치 변환 두 가지 데이터 증강 방식을 제안한다. 1‑D CNN 기반의 기본 모델에 ResNet·DenseNet 블록을 교체하여 성능을 비교하고, 각 오디오 세그먼트의 특징을 평균한 뒤 SVM 스태킹으로 최종 장르를 예측한다. FMA‑small과 GTZAN 데이터셋에서 DenseNet‑ 기반 모델이 기존 최첨단 방법들을 능가함을 실험적으로 입증한다.
상세 분석
이 연구는 음악 정보 검색(MIR) 분야에서 딥러닝 모델의 구조적 혁신과 데이터 증강 전략을 동시에 탐구한다는 점에서 의미가 크다. 먼저, 기존의 2‑D CNN이 주파수 축을 따라 컨볼루션을 수행하는 것이 음악적 의미와 부합하지 않을 수 있다는 비판을 받아들여, 전체 주파수 범위를 한 번에 포괄하는 1‑D 컨볼루션을 기본 블록으로 채택하였다. 이는 시간 축에만 초점을 맞추어 스펙트로그램의 시간‑주파수 상관관계를 보다 효율적으로 학습하게 한다.
다음으로, DenseNet 블록을 도입한 이유는 두 가지 핵심 장점에 있다. 첫째, 각 레이어가 이전 모든 레이어의 출력(feature map)을 직접 연결받음으로써 그래디언트 소실 문제를 완화하고, 깊은 네트워크에서도 안정적인 학습이 가능하다. 둘째, 특징 재사용(feature reuse) 메커니즘을 통해 파라미터 수를 최소화하면서도 표현력을 크게 향상시킨다. 논문에서는 DenseNet 블록을 기존 기본 블록에 삽입하고, 동일한 하이퍼파라미터(커널 크기 4, 배치 정규화, ReLU 등) 하에서 ResNet 블록과 비교 실험을 수행하였다. 결과적으로 DenseNet‑ 기반 모델이 ResNet‑ 기반 모델보다 약 0.6%~1% 정도 높은 정확도를 보였으며, 학습 시간도 상대적으로 짧았다. 이는 음악 스펙트로그램이라는 특수한 도메인에서 DenseNet의 연결 구조가 더 효율적인 특징 추출을 가능하게 함을 시사한다.
데이터 증강 측면에서는 두 가지 음악‑특화 기법을 제안한다. 첫 번째는 50% 오버랩을 적용한 시간 중첩(time overlapping)으로, 동일 곡의 서로 다른 시작점에서 추출된 세그먼트를 겹쳐 새로운 학습 샘플을 만든다. 이는 이미지 분야에서 흔히 쓰이는 슬라이딩 윈도우와 유사하지만, 음악에서는 연속적인 시간 흐름이 라벨에 큰 영향을 주지 않기 때문에 유효하다. 두 번째는 반음(half‑tone) 수준의 피치 변환(pitch shifting)이다. SoX 툴을 이용해 원본 오디오의 피치를 살짝 올리거나 내리면, 멜 스케일 주파수 구조가 변하면서도 장르 라벨은 유지된다. 두 방식을 동시에 적용했을 때 원본 데이터 대비 약 3배의 학습 샘플이 생성되었으며, 실험 결과 데이터 증강이 적용되지 않은 경우에 비해 정확도가 3~4% 상승하였다.
또한, 세그먼트‑레벨 예측을 앙상블하는 방법으로 단순 투표(voting) 대신 SVM 기반 스태킹을 사용하였다. 각 세그먼트에서 추출된 1024‑차원 특징 벡터를 평균화한 뒤, 이를 SVM에 입력해 최종 장르를 결정한다. 이 접근법은 다수결 방식보다 약 1%~2% 높은 정확도를 제공했으며, 특히 클래스 불균형이 존재하는 GTZAN 데이터셋에서 효과가 두드러졌다.
전체 실험에서는 FMA‑small(8 genre, 8 000곡)과 GTZAN(10 genre, 1 000곡) 두 공개 데이터셋을 사용하였다. 기본 1‑D CNN 모델은 약 59%~64%의 정확도를 보였으며, ResNet 블록 적용 시 66% 수준, DenseNet 블록 적용 시 68%~90%(GTZAN)까지 상승하였다. 특히, 기존 연구에서 전이 학습(transfer learning) 기반 CNN이 78%~89% 수준을 기록한 것에 비해, 본 논문의 DenseNet 모델은 전이 학습 없이도 경쟁력 있는 성능을 달성했다. 이는 모델 구조 자체가 음악 스펙트로그램에 적합하도록 설계되었기 때문이며, 데이터 증강과 스태킹 앙상블이 추가적인 성능 향상을 견인한다는 결론을 뒷받침한다.
마지막으로, 논문은 향후 연구 방향으로 DenseNet 내부 레이어별 표현 분석, 더 복잡한 연결 패턴 도입, 그리고 이미지·언어 분야에서 성공한 최신 아키텍처(예: Vision Transformer, ConvNeXt)를 오디오 도메인에 맞게 변형하는 가능성을 제시한다. 이러한 확장은 현재 제한된 라벨링 데이터 문제를 완화하고, 다양한 오디오 처리 작업(예: 음악 자동 태깅, 음성 감정 인식 등)에 DenseNet 기반 접근법을 일반화하는 데 기여할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기