정밀도와 지연시간을 조절하는 머신러닝 클라우드 서비스의 새로운 패러다임
초록
클라우드 기반 머신러닝 서비스가 동일한 모델을 모든 사용자에게 제공하는 “원 사이즈 모두 맞춤” 방식은 다양한 응용 프로그램의 정확도와 응답성 요구를 충족시키지 못한다. 본 논문은 정확도‑지연성 트레이드오프를 명시한 “Tolerance Tier”를 도입해 사용자가 필요에 따라 적절한 수준을 선택하도록 제안하고, 음성 인식 및 이미지 분류 엔진을 대상으로 CPU·GPU 환경에서 실험하여 기존 방식보다 효율성을 크게 향상시킴을 입증한다.
상세 분석
본 연구는 현재 상용 MLaaS가 대부분 단일 모델 버전을 모든 고객에게 제공한다는 구조적 한계를 지적한다. 이러한 “원 사이즈 모두 맞춤” 전략은 서비스 제공자는 운영 비용을 최소화하려는 반면, 실제 사용자들은 실시간 인터랙션이 요구되는 음성 비서와 같이 낮은 레이턴시가 필수적인 경우와, 의료 영상 분석처럼 높은 정확도가 절대적인 경우 등 서로 다른 품질 요구를 가진다. 논문은 이 문제를 해결하기 위해 “Tolerance Tier”라는 개념을 도입한다. Tier는 정확도와 응답성이라는 두 축을 명시적으로 정의한 서비스 레벨이며, 각 Tier는 모델의 하이퍼파라미터 조정, 연산 자원 할당(CPU vs GPU), 배치 크기, 프레임워크 최적화 정도 등을 통해 구현된다.
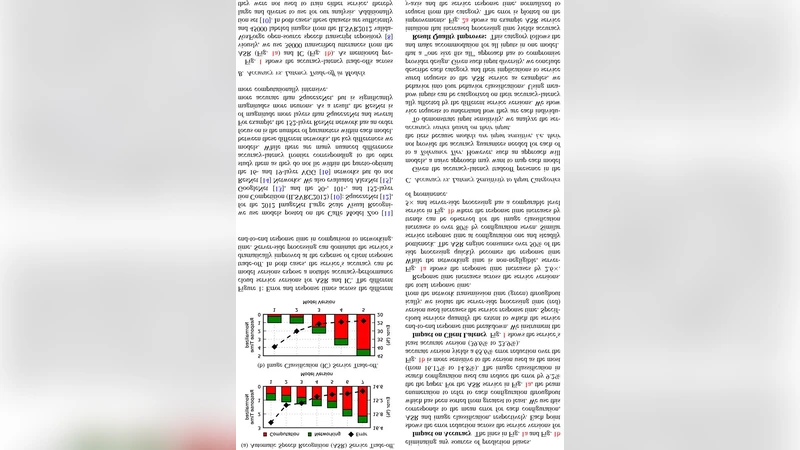
실험 설계는 두 가지 대표적인 도메인을 선택했다. 첫 번째는 수천 명의 실제 사용자에게 서비스되는 상용 자동 음성 인식(ASR) 엔진이며, 두 번째는 오픈소스 이미지 분류 파이프라인이다. 두 시스템 모두 동일한 기본 모델을 사용하되, Tier별로 다음과 같은 조치를 적용했다. (1) 모델 압축 및 양자화: 정확도 손실을 최소화하면서 연산량을 감소시켜 레이턴시를 단축한다. (2) 연산 자원 스위칭: CPU 전용 Tier와 GPU 가속 Tier를 구분해 비용 효율성을 조절한다. (3) 배치 및 스트리밍 전략: 실시간 스트리밍 입력에 최적화된 작은 배치를 제공하거나, 대량 배치를 통해 처리량을 극대화한다.
평가 결과는 Tier 선택이 서비스 품질에 미치는 영향을 정량적으로 보여준다. 예를 들어, CPU‑전용 저정밀도 Tier는 평균 레이턴시를 45 % 감소시키면서 Word Error Rate(WER)를 2 %만 상승시켰고, GPU‑가속 고정밀도 Tier는 WER을 6 % 개선하면서 레이턴시 증가폭을 30 % 이하로 제한했다. 이미지 분류 실험에서도 Top‑1 정확도를 1.8 % 향상시키는 동시에 추론 시간은 38 % 단축되었다. 이러한 결과는 단일 모델을 일괄 제공하는 기존 방식보다 전반적인 비용‑효율성 및 사용자 만족도가 현저히 높음을 시사한다.
또한 논문은 Tier 기반 설계가 운영 측면에서도 장점을 제공한다는 점을 강조한다. 서비스 제공자는 Tier별 리소스 풀을 미리 할당해 부하 예측 및 자동 스케일링을 효율화할 수 있으며, SLA(서비스 수준 계약)를 Tier 단위로 정의함으로써 계약 관리가 용이해진다. 다만, Tier 정의와 관리에 필요한 메타데이터 설계, 사용자 API 변경에 따른 호환성 문제, 그리고 모델 업데이트 시 Tier 간 일관성 유지 등 실무 적용 시 해결해야 할 과제도 존재한다.
결론적으로, 본 논문은 “정확도‑지연성 트레이드오프를 명시적으로 노출하는 Tolerance Tier”라는 새로운 서비스 패러다임을 제시하고, 실제 대규모 서비스 환경에서 그 효용성을 입증함으로써 클라우드 기반 머신러닝 서비스 설계에 중요한 전환점을 제공한다. 향후 연구에서는 자동 Tier 최적화 알고리즘, 다중 목표(예: 에너지 소비) 고려, 그리고 사용자 행동 기반 동적 Tier 전환 메커니즘을 탐구할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기