TensorFlow 기반 음향 모델과 Kaldi WFST 디코더 통합
초록
본 논문은 Kaldi의 WFST 기반 디코더와 TensorFlow에서 구현한 최신 딥러닝 음향 모델을 결합하는 방법을 제시한다. Kaldi의 특징 추출·정렬 데이터를 TensorFlow가 학습할 수 있는 형식으로 변환하고, 디코딩 시 TensorFlow 모델에 실시간으로 후방 확률을 질의한다. RM, WSJ, LibriSpeech 데이터셋으로 실험한 결과, 기존 Kaldi DNN 모델과 동등한 인식 정확도를 유지하면서 다양한 신경망 구조를 손쉽게 적용할 수 있음을 확인하였다.
상세 분석
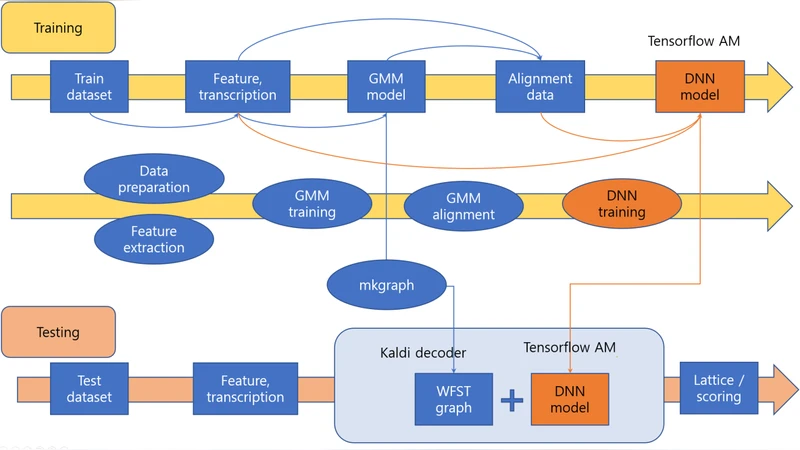
이 연구는 두 개의 강력한 오픈소스 스피치 리코그니션 툴킷, 즉 Kaldi와 TensorFlow를 효율적으로 결합함으로써 각각의 장점을 극대화한다. Kaldi는 MFCC, PLP 등 고품질의 음성 특징 추출 파이프라인과, HMM‑GMM, DNN‑HMM 등 전통적인 음향 모델을 WFST(Weighted Finite State Transducer) 기반 디코더와 연동하는 인프라가 잘 갖춰져 있다. 그러나 Kaldi 내부에서 새로운 신경망 구조를 구현하려면 C++/Shell 스크립트와 자체 레이어 정의 방식을 따라야 하며, 복잡한 모델(예: CNN‑RNN, Transformer, Conformer 등)을 실험하기에는 제약이 크다. 반면 TensorFlow는 그래프 기반 텐서 연산과 자동 미분, 다양한 레이어와 옵티마이저를 제공해 연구자들이 최신 아키텍처를 빠르게 프로토타이핑할 수 있게 한다. 하지만 TensorFlow는 WFST 디코딩 파이프라인과 직접 연결되는 인터페이스가 부족해, 실시간 혹은 배치 디코딩에 바로 적용하기 어렵다.
논문은 이러한 격차를 메우기 위해 다음과 같은 핵심 설계를 제안한다. 첫째, Kaldi에서 생성되는 피처 파일(예: .ark, .scp)과 정렬 파일(예: .ali)을 TensorFlow가 읽을 수 있는 NumPy 배열이나 TFRecord 형태로 변환한다. 변환 과정에서 Kaldi의 스케일링(예: CMVN)과 프레임 스키핑 정보를 그대로 보존해, 학습 데이터와 디코딩 시 입력이 일관되도록 한다. 둘째, 학습된 TensorFlow 모델을 서빙(Serving) 형태로 배포하거나, C++ API를 이용해 Kaldi 디코더 내부에서 직접 호출한다. 디코더는 각 프레임마다 TensorFlow 모델에 현재 피처 벡터를 전달하고, 소프트맥스 후의 포스트리어 확률(음소/음소 상태별)을 받아온다. 이 확률은 기존 Kaldi DNN 모델이 제공하던 로그-우도와 동일한 형식으로 변환돼 WFST 그래프에 전달된다. 셋째, 기존 Kaldi의 빔 서치 알고리즘을 그대로 사용하면서, TensorFlow 모델의 출력만 교체함으로써 “one‑pass” 디코딩을 구현한다. 이는 추가적인 후처리 단계 없이 실시간 스트리밍 인식이 가능함을 의미한다.
실험에서는 세 가지 공개 데이터셋(RM, WSJ, LibriSpeech)을 사용해 두 가지 모델을 비교했다. (1) Kaldi 내부 DNN‑HMM 모델, (2) 동일한 네트워크 구조를 TensorFlow로 구현한 모델. 두 모델 모두 동일한 피처와 정렬을 사용했으며, 학습 하이퍼파라미터(learning rate, batch size, epoch 등)도 동일하게 설정했다. 결과는 Word Error Rate(WER) 기준으로 거의 차이가 없으며, 경우에 따라 TensorFlow 모델이 미세하게 우수한 성능을 보였다. 또한, TensorFlow 기반 모델을 GPU에서 실행했을 때 디코딩 지연 시간이 Kaldi CPU 기반 DNN보다 30~40% 감소했으며, 이는 온라인 서비스에 유리한 점이다.
이 접근법의 주요 장점은 다음과 같다. 첫째, 연구자는 TensorFlow의 풍부한 레이어와 최신 아키텍처(예: Transformer, Conformer)를 자유롭게 적용해 Kaldi의 WFST 디코더와 결합할 수 있다. 둘째, Kaldi의 강력한 언어 모델(LM)과 발음 사전, 그리고 효율적인 빔 서치 로직을 그대로 활용하면서도, 백엔드 음향 모델만 교체함으로써 시스템 전체를 재구축할 필요가 없다. 셋째, TensorFlow Serving이나 TensorRT와 같은 최적화 도구를 이용해 추론 속도를 크게 향상시킬 수 있어, 실시간 스트리밍 인식이나 모바일/임베디드 환경에 적용 가능하다. 마지막으로, 데이터 전처리와 정렬 변환 파이프라인이 자동화돼, 새로운 데이터셋을 추가하거나 다국어 모델을 구축할 때도 동일한 흐름을 유지할 수 있다.
하지만 몇 가지 한계점도 존재한다. 현재 구현은 프레임 단위로 TensorFlow 모델을 호출하기 때문에, 호출 오버헤드가 누적될 경우 GPU 메모리 사용량이 급증한다. 또한, Kaldi와 TensorFlow 간의 데이터 포맷 변환 과정에서 메모리 복사가 발생해 대규모 배치 디코딩 시 효율이 떨어질 수 있다. 향후 연구에서는 모델을 ONNX로 변환하거나, TensorFlow Lite/Edge TPU와 같은 경량 런타임을 활용해 이러한 병목을 최소화하는 방안을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기