핵심 지식 증류를 통한 단일 음성 인식 모델의 성능 혁신
초록
본 논문은 다수의 음성 인식 모델을 앙상블한 교사 모델에서 핵심적인 확률 정보만을 추출해 학생 모델에 전달하는 ‘Essence Knowledge Distillation(EKD)’ 방식을 제안한다. 소프트 라벨과 정답 라벨을 동시에 활용하는 멀티태스크 학습으로, 파라미터가 훨씬 적은 학생 모델이 교사 모델의 성능을 뛰어넘는 결과를 보였다.
상세 분석
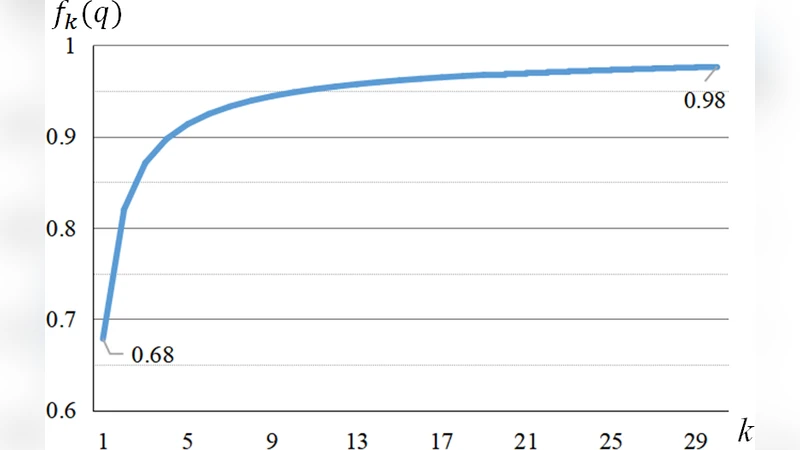
이 연구는 기존 지식 증류(KD) 방식이 교사 모델의 전체 출력 확률을 그대로 학생 모델에 전달한다는 점에서 한계를 지적한다. 음성 인식에서는 출력 차원이 수천에서 수만에 이르기 때문에, 대부분의 확률값은 매우 낮고 잡음에 해당한다. 저자들은 이러한 잡음이 학생 모델의 일반화에 악영향을 미칠 수 있다고 보고, 교사 모델의 출력 중 상위 k 개의 확률만을 남기고 나머지는 0으로 만든 뒤 정규화하는 ‘핵심(essence) 지식’ 추출 방법을 도입하였다. 이 과정은 두 가지 중요한 효과를 만든다. 첫째, 학생 모델이 학습해야 할 정보량이 크게 감소해 학습 효율이 향상된다. 둘째, 잡음이 제거된 확률 분포는 클래스 간 유사성을 보다 명확히 전달하므로, 학생 모델이 더 정교한 판단 경계를 형성할 수 있다.
멀티태스크 학습 프레임워크는 정답 라벨에 대한 교차 엔트로피 손실과, 핵심 소프트 라벨에 대한 KL‑다이버전스 손실을 가중치 λ 로 조절해 동시에 최적화한다. λ=0이면 순수 KD, λ=1이면 전통적인 라벨 기반 학습이며, 본 연구에서는 λ를 0.5~0.7 사이에서 실험적으로 설정해 두 손실이 균형을 이루도록 했다.
실험은 309시간 규모의 Switchboard 데이터셋을 사용했으며, 교사 모델은 서로 다른 구조(TDNN, TDNN‑LSTM)를 가진 두 서브 모델을 0.5:0.5 비율로 평균화해 구성하였다. 학생 모델은 동일한 아키텍처(TDNN‑LSTM)지만 파라미터 수가 교사 모델보다 현저히 적다. 결과적으로, 교사 모델의 WER이 19.3%였던 반면, 핵심 지식 증류를 적용한 학생 모델은 18.9%까지 낮아져 교사를 능가했다. 또한, 단순히 정답 라벨만으로 학습한 동일 구조 모델(20% 데이터)보다도 월등히 좋은 성능을 보였다.
이러한 결과는 ‘핵심 지식’만을 선택해 전달함으로써, 교사 모델이 가진 풍부한 클래스 간 관계 정보를 효율적으로 압축할 수 있음을 증명한다. 또한, 멀티태스크 손실을 통해 소프트 라벨의 부드러운 정보와 하드 라벨의 정확성을 동시에 활용함으로써, 학생 모델이 과적합 없이 일반화 능력을 극대화한다는 점에서 기존 KD 연구와 차별화된다. 향후 다른 음성 인식 태스크나 언어 모델에도 동일한 접근법을 적용하면, 연산 비용을 크게 줄이면서도 높은 정확도를 유지할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기