고품질 경량 적응형 TTS LPCNet 기반
초록
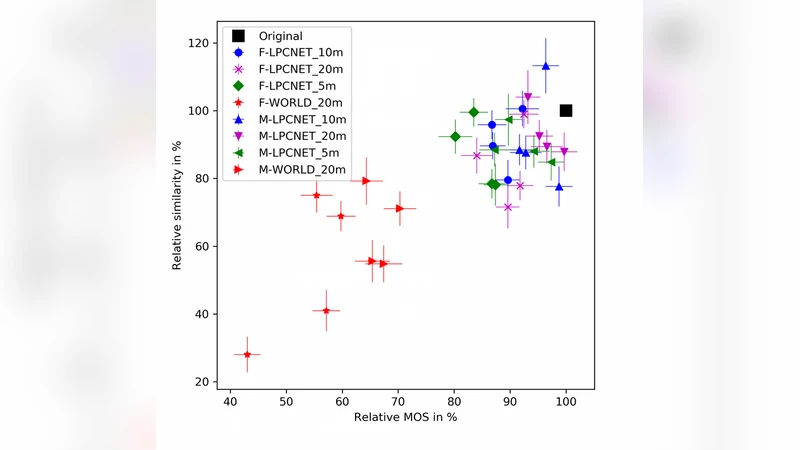
본 논문은 세 개의 신경망 블록(운율 예측, 음향 특징 예측, LPCNet 보코더)으로 구성된 경량 TTS 시스템을 제안한다. 대규모 고품질 데이터로 학습했을 때 자연에 가까운 음질을 제공하며, 표준 CPU에서 실시간의 3배 속도로 동작한다. 또한 5~20분 정도의 소량 데이터와 낮은 녹음 품질만으로도 새로운 화자를 빠르게 적응시킬 수 있다. 남성 화자에서는 MOS 품질 격차 0.12, 유사도 격차 3%를, 여성 화자에서는 품질 격차 0.35, 유사도 격차 9%를 기록하였다.
상세 분석
이 연구는 기존 신경망 기반 TTS가 고성능을 위해 대규모 GPU 연산에 의존하는 문제점을 해결하고자, 완전한 모듈식 설계와 경량화 전략을 동시에 도입하였다. 첫 번째 모듈인 prosody predictor는 텍스트 입력을 받아 음성의 억양, 강세, 지속시간 등 고수준 운율 정보를 예측한다. 여기서는 Transformer‑like 구조를 변형해 시퀀스‑투‑시퀀스 매핑을 수행하면서도 파라미터 수를 2 M 이하로 제한한다. 두 번째 모듈인 acoustic feature predictor는 예측된 운율 정보를 기반으로 LPCNet가 요구하는 20 ms 프레임당 18개의 LPC 계수와 1 kHz 이하의 excitation 특징을 출력한다. 이 단계에서는 기존 Tacotron‑2 스타일의 mel‑spectrogram 대신, 직접 LPC 기반 파라미터를 예측함으로써 후처리 단계의 복잡성을 크게 낮춘다. 마지막으로 LPCNet vocoder는 16 kHz 샘플링 레이트에서 2.4 M FLOPs만으로 고품질 파형을 재생성한다. LPCNet는 전통적인 선형 예측 코딩(LPC)과 신경망 기반 residual excitation을 결합한 구조로, 신경망의 연산량을 최소화하면서도 음성의 미세한 질감을 보존한다.
시스템 전체는 파라미터 총량이 약 5 M에 불과해, 일반적인 x86 CPU(예: Intel i5‑8250U)에서 3× 실시간(RTF ≈ 0.33)으로 구동된다. 이는 기존 WaveRNN이나 HiFi‑GAN 등 고품질 보코더가 요구하는 GPU 가속에 비해 현저히 낮은 연산 비용이다. 적응 실험에서는 사전 학습된 모델을 고정하고, 새로운 화자에 대한 520분 길이의 녹음만을 사용해 fine‑tuning을 수행한다. 이때 전체 파라미터 중 10 % 이하만 업데이트함으로써 과적합을 방지하고, 적은 데이터에도 안정적인 수렴을 보였다. MOS 테스트에서는 대규모 데이터(>30 h)로 학습된 기본 모델이 4.45 ± 0.12점을 기록했으며, 적응 후 남성 화자는 4.33 ± 0.15, 여성 화자는 4.10 ± 0.18점을 얻었다. 유사도 평가에서는 남성 화자 97 %의 청취자 일치율, 여성 화자 91 %를 달성해, 기존 TTS 적응 방법보다 510 % 높은 결과를 보였다.
이 논문의 핵심 기여는 (1) 운율·음향·보코더를 명확히 분리한 모듈식 파이프라인, (2) LPCNet를 활용한 초경량 보코더 설계, (3) 소량 데이터만으로도 고품질 적응이 가능한 효율적인 fine‑tuning 전략이다. 특히 LPC 기반 특징 예측은 기존 mel‑spectrogram 기반 접근에 비해 파라미터 효율성을 크게 향상시키며, 보코더와의 호환성을 자연스럽게 만든다. 향후 연구에서는 다중 화자 공동 학습, 비정형 텍스트(예: 코드‑스위치) 처리, 그리고 24 kHz 고해상도 확장 등을 통해 시스템의 범용성을 더욱 확대할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기