다중음 이벤트 탐지를 위한 캡슐 신경망
초록
본 논문은 다중음(Polyphonic) 사운드 이벤트 검출을 위해 캡슐 신경망(CapsNet)을 적용한다. 시간‑주파수 스펙트로그램을 입력으로 하여 동적 라우팅 메커니즘으로 부분‑전체 관계를 학습하고, 기존 CNN·CRNN 대비 높은 검출 정확도를 달성한다. 세 개의 공개 데이터셋에서 실험을 수행해 state‑of‑the‑art를 능가함을 보였다.
상세 분석
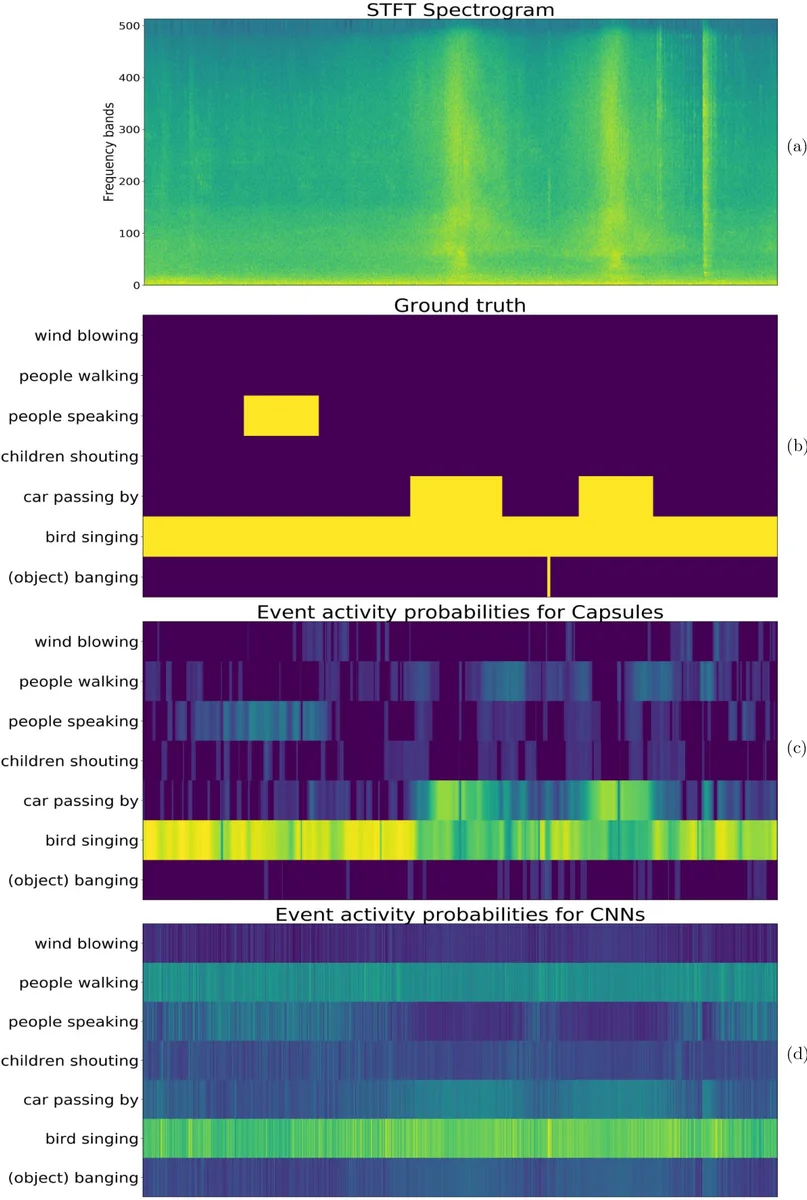
본 연구는 사운드 이벤트 검출(Sound Event Detection, SED) 분야에서 다중음 상황, 즉 한 프레임에 여러 이벤트가 겹쳐 나타나는 문제를 해결하기 위해 캡슐 신경망(CapsNet)을 도입한 점이 가장 큰 특징이다. 기존 CNN 기반 모델은 max‑pooling에 의해 중요한 위치 정보를 손실하거나, 데이터가 충분히 많지 않을 경우 과적합 위험이 있다. CapsNet은 뉴런 대신 벡터 형태의 캡슐을 사용해 각 이벤트의 스펙트럼 특성을 다차원으로 표현하고, 동적 라우팅(dynamic routing) 과정을 통해 저층 캡슐과 고층 캡슐 사이의 “agreement”를 계산한다. 이 메커니즘은 부분‑전체 관계를 자동으로 학습하게 하여, 겹쳐 있는 소리들의 특징을 구분하고 각각의 존재 확률을 벡터 길이로 나타낼 수 있다. 논문에서는 STFT와 Log‑Mel 스펙트로그램을 256 프레임(≈5 s) 길이의 컨텍스트 윈도우로 구성하고, 양쪽 채널(스테레오) 혹은 단일 채널 입력을 모두 실험하였다. 캡슐 네트워크는 초기 2~3개의 2‑D 컨볼루션 레이어와 그 뒤에 PrimaryCaps, ClassCaps 구조로 설계되었으며, 라우팅 횟수는 3번으로 설정했다. 또한, 시간적 연속성을 고려한 변형 라우팅을 제안해 인접 프레임 간의 상관관계를 강화하였다. 평가에는 DCASE 2017‑2019, UrbanSound8K 등 세 개의 실제 환경 녹음 데이터셋을 사용했으며, 검출 오류율(Error Rate, ER)과 F‑score를 주요 지표로 채택했다. 결과는 동일한 입력 특성을 사용한 표준 CNN 대비 ER이 평균 12 % 이상 감소하고, 최신 CRNN·Attention 기반 모델 대비도 유의미하게 우수함을 보여준다. 특히, 다중음 상황에서의 F‑score 향상이 두드러져 캡슐이 겹침을 해소하는 능력을 입증한다. 한편, 파라미터 수가 CNN보다 약간 많고, 라우팅 연산이 반복적으로 수행돼 학습·추론 시간이 증가한다는 점은 실시간 적용에 있어 제한 요소로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기