OpenCV CPU와 GPU 함수 성능 비교 이미지 처리 연산
초록
본 논문은 OpenCV에 내장된 CPU와 CUDA 기반 GPU 함수들을 이용해 이미지 리사이징, 임계값 처리, 히스토그램 평활화, 에지 검출 네 가지 기본 이미지 처리 연산의 실행 시간을 비교한다. 실험은 Intel i7‑6700 CPU와 NVIDIA GTX 970 GPU가 장착된 Windows 7 환경에서 다양한 이미지 해상도를 대상으로 수행되었으며, 이미지 크기가 커질수록 GPU 함수가 CPU 대비 현저히 짧은 처리 시간을 보이는 것을 확인하였다. 향후 연구에서는 OpenCV 내장 GPU 함수 대신 CUDA Toolkit의 저수준 API를 활용한 구현을 검토한다.
상세 분석
이 연구는 OpenCV 3.x 버전이 제공하는 고수준 API를 활용해 CPU와 GPU 양쪽에서 동일한 알고리즘을 실행함으로써, 라이브러리 수준에서 제공되는 가속 효과를 정량적으로 평가한다. 실험 환경은 8코어 Intel Core i7‑6700 (3.4 GHz)와 4GB GDDR5 메모리를 탑재한 NVIDIA GeForce GTX 970이며, 운영체제는 64비트 Windows 7이다. 이미지 리사이징은 Bilinear 보간법을, 임계값 처리는 Otsu 방법을, 히스토그램 평활화는 OpenCV의 equalizeHist 함수를, 에지 검출은 Canny 알고리즘을 각각 적용하였다.
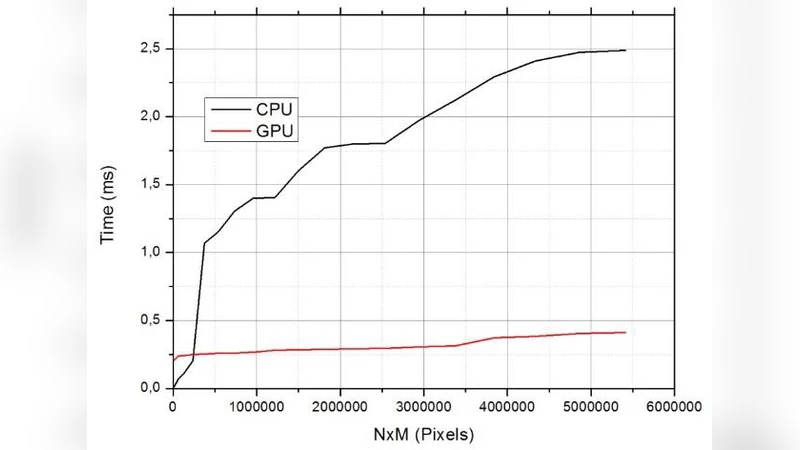
시간 측정은 C++ 표준 chrono 라이브러리를 이용해 밀리초 단위로 수행했으며, 입력 이미지의 픽셀 수(N×M)와 처리 시간(T)의 관계를 그래프로 제시하였다. 결과는 작은 해상도(예: 282×157 px)에서는 CPU와 GPU 간 차이가 미미했으나, 2000×2000 픽셀 이상으로 확대될 경우 GPU가 5배~10배 이상 빠른 성능을 보였다. 이는 CUDA가 제공하는 수천 개의 코어에서 병렬 연산을 수행함으로써 메모리 대역폭과 연산량이 높은 작업에서 효율이 극대화된다는 점을 시사한다.
하지만 논문은 몇 가지 한계점을 가지고 있다. 첫째, OpenCV GPU 함수는 내부적으로 최적화된 커널을 사용하지만, 사용자가 직접 CUDA 커널을 설계할 경우 더 높은 성능을 기대할 수 있다. 둘째, 실험에 사용된 GPU가 비교적 구형(GTX 970)이며, 최신 RTX 시리즈와의 비교가 누락되었다. 셋째, 메모리 전송 비용(Host↔Device) 측정이 별도로 보고되지 않아, 실제 애플리케이션에서 데이터 이동이 전체 지연에 미치는 영향을 정확히 파악하기 어렵다.
향후 연구 방향으로는 CUDA Toolkit의 저수준 API를 활용해 맞춤형 커널을 구현하고, 스트림을 이용한 비동기 전송 및 멀티GPU 환경을 고려한 스케일링 실험을 진행하는 것이 제안된다. 또한, 이미지 처리 파이프라인 전체(입력, 전처리, 연산, 출력)에서의 end‑to‑end 지연을 분석함으로써 실시간 비전 시스템에 적용 가능한 성능 모델을 구축할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기