LMFAO: 대규모 집계 배치를 위한 다계층 최적화 엔진
초록
LMFAO는 조인된 관계형 데이터에 대해 수천 개에 달하는 그룹‑바이 집계들을 메모리 내에서 효율적으로 처리하도록 설계된 다계층 엔진이다. 조인 트리 구축, 다중 루트 탐색, 방향성 뷰 생성·병합, 그룹 뷰와 다중 출력 최적화, 병렬 실행 및 C++ 코드 특수화까지 일련의 논리·물리 최적화를 적용한다. 실험 결과, 기존 DBMS와 머신러닝 프레임워크에 비해 여러 차례(10⁰~10³배) 빠른 성능을 보이며, 릿지 회귀, 의사결정·회귀 트리, Chow‑Liu 베이지안 네트워크, 데이터 큐브 등 다양한 분석 작업에 적용 가능함을 입증한다.
상세 분석
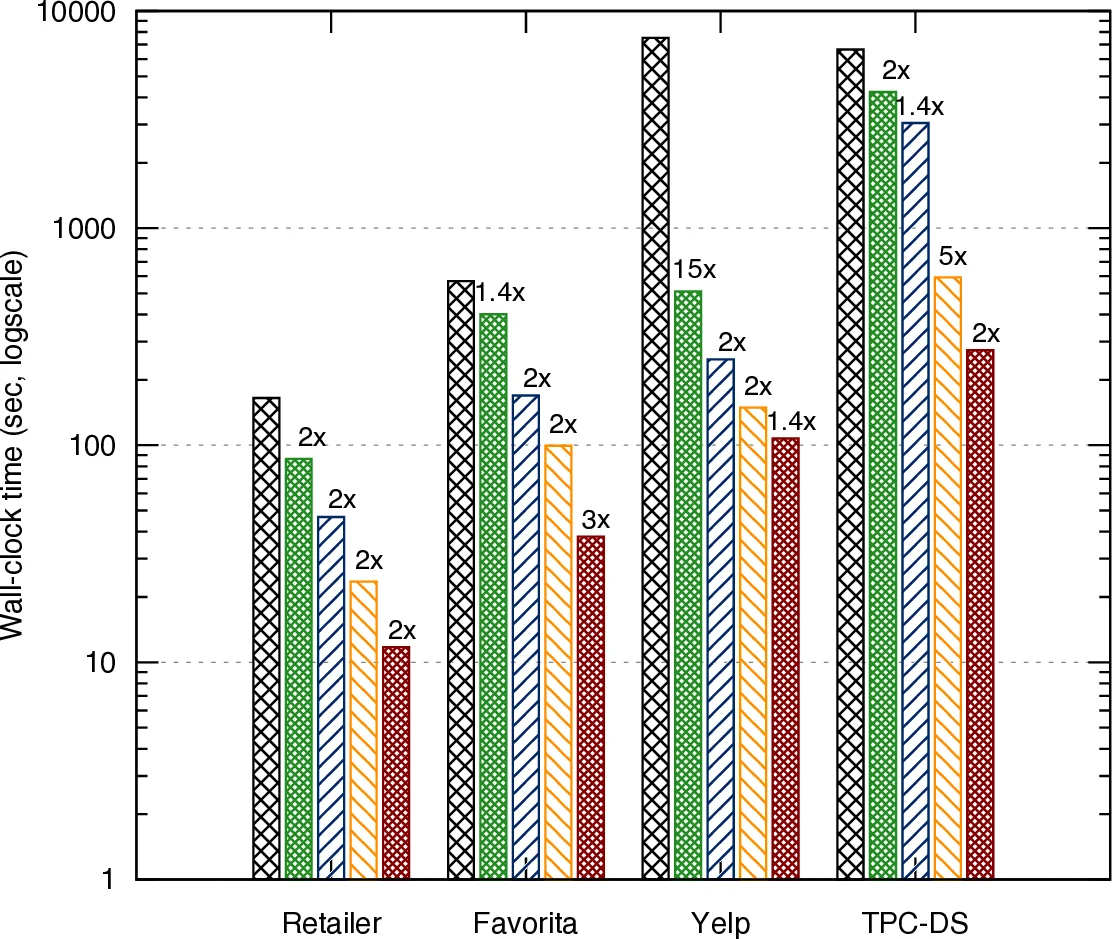
LMFAO의 핵심 아이디어는 “대량의 집계 배치를 하나의 조인 트리 위에서 공유·재사용한다”는 점이다. 먼저 입력 관계와 카디널리티 정보를 바탕으로 최적의 조인 트리를 생성하고, 기존 DBMS가 단일 쿼리당 하나의 루트만 사용하는 것과 달리 ‘Find Roots’ 단계에서 여러 루트를 선택한다. 이는 동일한 조인 트리를 서로 다른 루트에서 바라보게 하여 뷰의 중복을 크게 줄이고, 실험에서는 2~5배의 속도 향상을 가져왔다.
‘Aggregate Pushdown’ 단계에서는 각 집계를 트리의 각 엣지마다 방향성 뷰로 분해한다. 이 뷰는 해당 서브트리에서 부분 집계를 미리 수행해 조인 비용을 앞당기는 역할을 하며, 동일한 서브트리를 공유하는 여러 집계가 동일 뷰를 재사용하도록 설계되었다. 이어지는 ‘Merge Views’ 단계에서는 (1) 동일 뷰 중복 제거, (2) 동일 그룹‑바이·동일 본문·다른 집계 병합, (3) 동일 그룹‑바이·다른 본문 병합 순으로 뷰를 통합한다. 예시로 Retailer 데이터셋에서 814개의 집계를 3,256개의 뷰로 전개했지만, 최종적으로 34개의 뷰만 남겨 1,468개의 집계를 한 번에 처리하도록 압축하였다.
‘Group Views’ 단계는 같은 노드에서 독립적인 뷰들을 하나의 그룹으로 묶어, 입력 관계를 한 번 스캔하면서 그룹 내 모든 뷰를 동시에 계산하도록 한다. 이때 트리 구조를 트라이 형태로 조직해, 행 기반 스캔 대비 최대 3배 적은 원소 접근을 달성한다. ‘Multi‑Output Optimization’은 각 뷰 그룹에 대해 한 번의 관계 스캔과 키‑루크업만으로 모든 필요한 집계를 업데이트하도록 실행 계획을 생성한다. 특히 대용량 팩트 테이블을 가진 스노우플레이크 스키마에서 큰 효과를 보인다.
‘Parallelization’ 레이어는 뷰 그룹 간 의존성을 그래프로 분석해, 독립적인 그룹을 여러 스레드에 할당하고 입력 관계를 파티셔닝한다. 4‑코어 환경에서 1.4~3배의 추가 가속을 얻었다. 마지막 ‘Compilation’ 단계에서는 전체 파이프라인을 C++ 코드로 자동 생성한다. 조인 트리와 스키마에 특화된 코드가 각 뷰 그룹별로 별도 컴파일되며, 인라인, 연속 메모리 배치, 연산 재사용, 루프 합성 등 벡터화 기법을 적용해 메모리 접근과 연산 오버헤드를 최소화한다. 동적 UDAF가 필요한 경우에는 인라인을 피하고 런타임에 재컴파일하도록 설계돼, 반복 학습 시에도 높은 효율을 유지한다.
LMFAO는 이러한 다계층 최적화를 통해 기존 DBMS가 제공하는 단일 집계 최적화 수준을 넘어, 수천 개의 복합 집계를 동시에 처리하면서도 메모리 사용량을 수십 MB 수준으로 억제한다. 실험에서는 PostgreSQL, MonetDB, 상용 DBMS 대비 10⁰10³배, TensorFlow·Scikit‑learn·R·AC/DC 대비 10⁰10²배의 성능 향상을 기록했으며, 특히 모델 학습 파이프라인 전체에서 데이터 물질화 비용을 크게 감소시켜 전체 실행 시간을 수십 배 단축하였다.
댓글 및 학술 토론
Loading comments...
의견 남기기