소형 디바이스용 단일채널 음성 강화와 키워드 탐지 통합 모델
본 논문은 작은 메모리와 연산량을 갖는 임베디드 디바이스에 적합하도록 설계된 단일채널(모노럴) 음성 강화 전처리와 CNN 기반 키워드 스포팅(KWS) 시스템을 하나의 네트워크로 결합하고, 전체 모델을 공동 학습(joint‑training)함으로써 잡음 환경에서의 인식 정확도를 크게 향상시키는 방법을 제안한다. 핵심은 파라미터와 연산량을 최소화한 Convolution‑Recurrent Network(CRN)와, 강화된 스펙트로그램을 바로 MFCC…
저자: Yue Gu, Zhihao Du, Hui Zhang
본 연구는 “항상 켜져 있는”(always‑on) 상태에서 동작해야 하는 소형 디바이스용 키워드 스포팅(KWS) 시스템의 잡음 강인성을 향상시키기 위해, 음성 강화 전처리와 KWS 모델을 하나의 네트워크로 결합하고 공동 학습(joint‑training)하는 새로운 프레임워크를 제안한다. 기존의 KWS 시스템은 깨끗한 환경에서는 높은 정확도를 보이지만, 실제 사용 환경에서는 배경 잡음, 화이트 노이즈, 일상 소음 등에 의해 성능이 급격히 저하된다. 이를 해결하기 위해 일반적으로는 다중 조건 학습(multi‑condition training)이나 별도의 잡음 억제 전처리를 적용하지만, 전자는 모델 규모가 커져 소형 디바이스에 부적합하고, 후자는 강화 모델과 KWS 모델 간의 목표 불일치로 최적화 효율이 낮다.
논문은 이러한 문제점을 인식하고, 두 모델을 연속적으로 연결한 뒤 전체 파라미터를 동시에 최적화하는 방식을 채택한다. 구체적인 구성은 다음과 같다.
1. **음성 강화 모델**
- 마스크 기반 접근법을 사용해 이상적인 비율 마스크(IRM)를 예측한다.
- 손실 함수는 예측 마스크와 실제 IRM 사이의 평균 제곱 오차(MSE)이다.
- 입력은 Mel‑spectrogram이며, 이는 파워 스펙트럼 대비 차원 수가 적고 MFCC 추출에 바로 활용 가능하다는 장점이 있다.
2. **Convolution‑Recurrent Network(CRN)**
- Encoder‑Decoder 형태의 컨볼루션 블록과 양방향 LSTM 기반 RNN 블록을 결합한다.
- Encoder는 시간·주파수 축 모두에 stride를 적용해 특성 맵을 압축하고, Decoder는 skip‑connection을 통해 세밀한 정보를 복원한다.
- Decoder 단계에서 leaky‑ReLU(lReLU)를 사용해 모든 위치에서 비제로 그래디언트를 유지, 학습 안정성을 강화한다.
- 두 가지 규모(Full‑size와 Narrow)를 설계했으며, Narrow 모델은 파라미터 180 k 이하, 연산량 30 M MACs 수준으로 매우 경량화되었다.
3. **Feature Transformation Block(FTB)**
- 강화된 Mel‑spectrogram을 MFCC로 변환하는 과정을 신경망 레이어 형태로 구현한다.
- Mel‑filter bank와 로그‑DCT 연산을 각각 선형 레이어로 표현해 역전파가 가능하도록 만든다.
- 파워 스펙트럼 기반 모델의 경우에도 동일한 변환 과정을 적용하지만, 차원 수가 커 연산량이 증가한다.
4. **키워드 스포팅 모델**
- 기존 연구에서 좋은 성능을 보인 cnn‑trad‑pool2 구조를 사용한다.
- 첫 번째 max‑pooling 레이어의 크기와 stride를 (2,2)로 설정하고, 중간의 fully‑connected 레이어를 제거해 경량화하였다.
5. **학습 전략**
- (①) 강화 모델을 MSE 손실로 사전 학습.
- (②) 사전 학습된 강화 모델을 고정하고 KWS 모델을 MFCC(노이즈 음성)로 학습(KWS+Enhancement).
- (③) 강화 모델과 KWS 모델을 동시에 최적화하는 joint‑training.
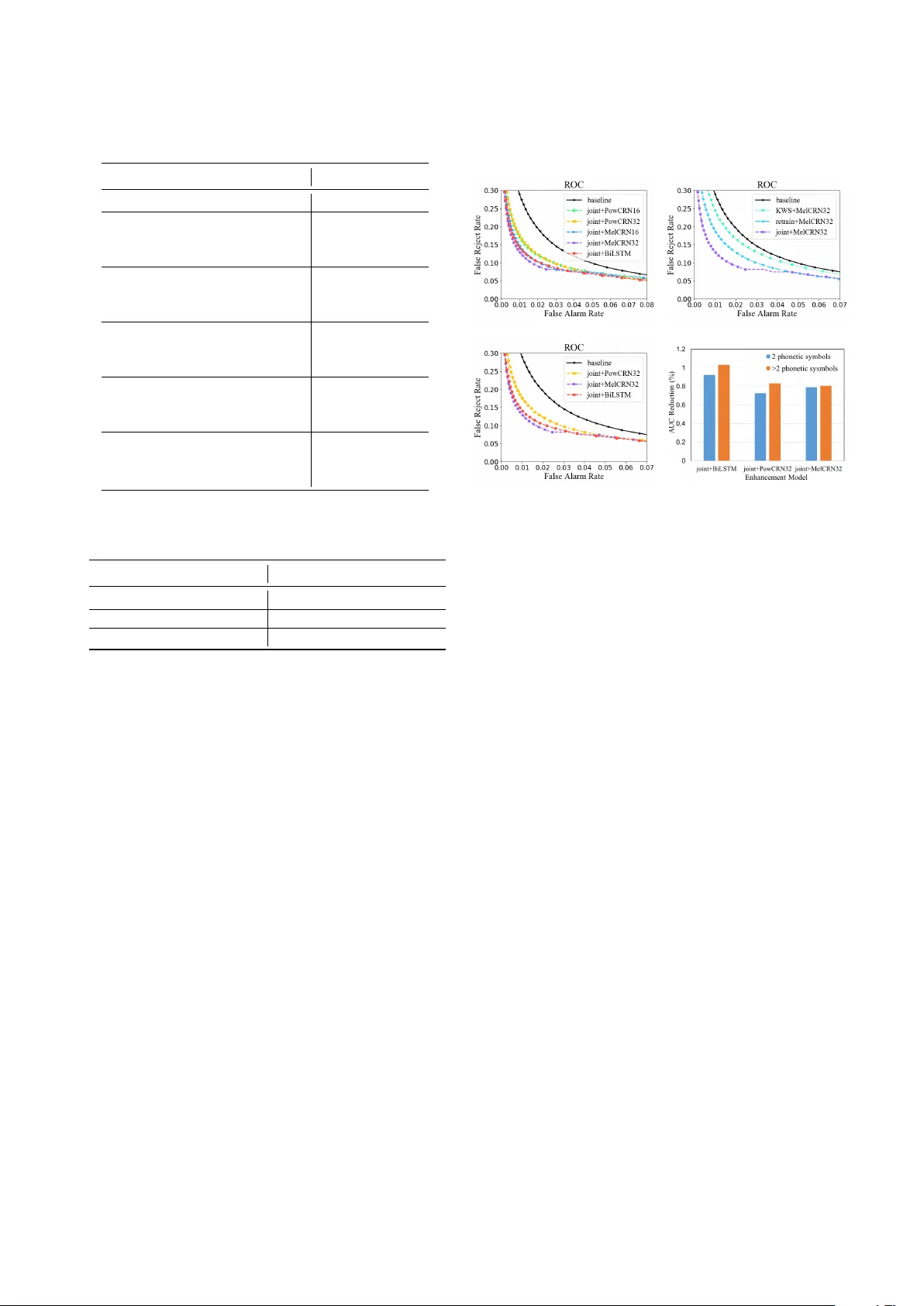
- 또한, 강화 모델만 사용해 KWS 모델을 재학습(retrain+Enhancement)하는 경우도 실험하였다.
**실험 설정**
- 데이터셋: Google Speech Commands Dataset (1 s 길이 음성, 10개 키워드 + unknown + silence).
- 잡음: 6가지 배경 잡음(핑크, 화이트, 설거지, 자전거 등)과 SNR {‑3, 0, 3, 6} dB를 혼합해 약 812 k 훈련 샘플을 생성.
- 평가: 정확도, AUC, EER, ROC 곡선.
- 모델 파라미터와 연산량: Baseline cnn‑trad‑pool2(493 k 파라미터, 95.9 M MACs), BiLSTM(5 661 k 파라미터, 432.7 M MACs), PowCRN32(724 k, 280.1 M), PowCRN16(182 k, 73 M), MelCRN32(881 k, 115 M), MelCRN16(221 k, 29 M).
**주요 결과**
- 모든 강화 기반 모델이 다중 조건 학습 Baseline(80.89 % 정확도)보다 우수했다.
- joint‑training이 가장 높은 정확도와 가장 낮은 AUC/EER을 기록했으며, 특히 MelCRN32 joint‑training은 93.17 % 정확도와 1.19 % AUC를 달성했다.
- 파라미터가 180 k 수준인 MelCRN16 joint‑training도 92.56 % 정확도와 1.28 % AUC를 보여, 경량 모델에서도 높은 성능을 유지함을 확인했다.
- 잡음이 매치되지 않은 테스트(다양한 비음성 소리)에서도 MelCRN32 joint‑training은 78.12 % 정확도로 가장 높은 일반화 성능을 보였다.
- Mel‑spectrogram 기반 모델이 파워 스펙트럼 기반 모델보다 연산량이 적고, 동일하거나 더 낮은 FRR을 달성해 KWS 시스템에 적합함을 입증했다.
**의의 및 향후 과제**
- 제안된 CRN 구조는 파라미터와 연산량을 크게 줄이면서도 잡음 억제와 키워드 인식 성능을 동시에 최적화한다는 점에서 소형 임베디드 디바이스에 실용적이다.
- Mel‑spectrogram을 직접 강화하고 바로 MFCC로 변환함으로써 전처리 단계에서 정보 손실을 최소화하고, 전체 파이프라인을 end‑to‑end 학습 가능하게 만든 것이 핵심 혁신이다.
- 향후 연구에서는 실시간 구현을 위한 하드웨어 최적화, 다양한 언어·키워드 세트에 대한 확장성 검증, 그리고 사용자 개인화에 맞춘 적응형 강화 모델 개발 등을 통해 실제 제품에 적용할 수 있는 로드맵을 제시할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기