목소리 필터 화자 조건부 스펙트로그램 마스킹
본 논문은 목표 화자의 사전 녹음(레퍼런스)으로부터 추출한 화자 임베딩을 이용해, 다중 화자 음성에서 원하는 화자의 목소리만을 선택적으로 분리하는 시스템을 제안한다. 화자 인코더와 스펙트로그램 마스크 네트워크를 별도로 학습시켜, 잡음이 섞인 음성에 적용했을 때 인식 오류율(WER)을 크게 낮추면서 단일 화자 상황에서는 성능 저하를 최소화한다.
저자: Quan Wang, Hannah Muckenhirn, Kevin Wilson
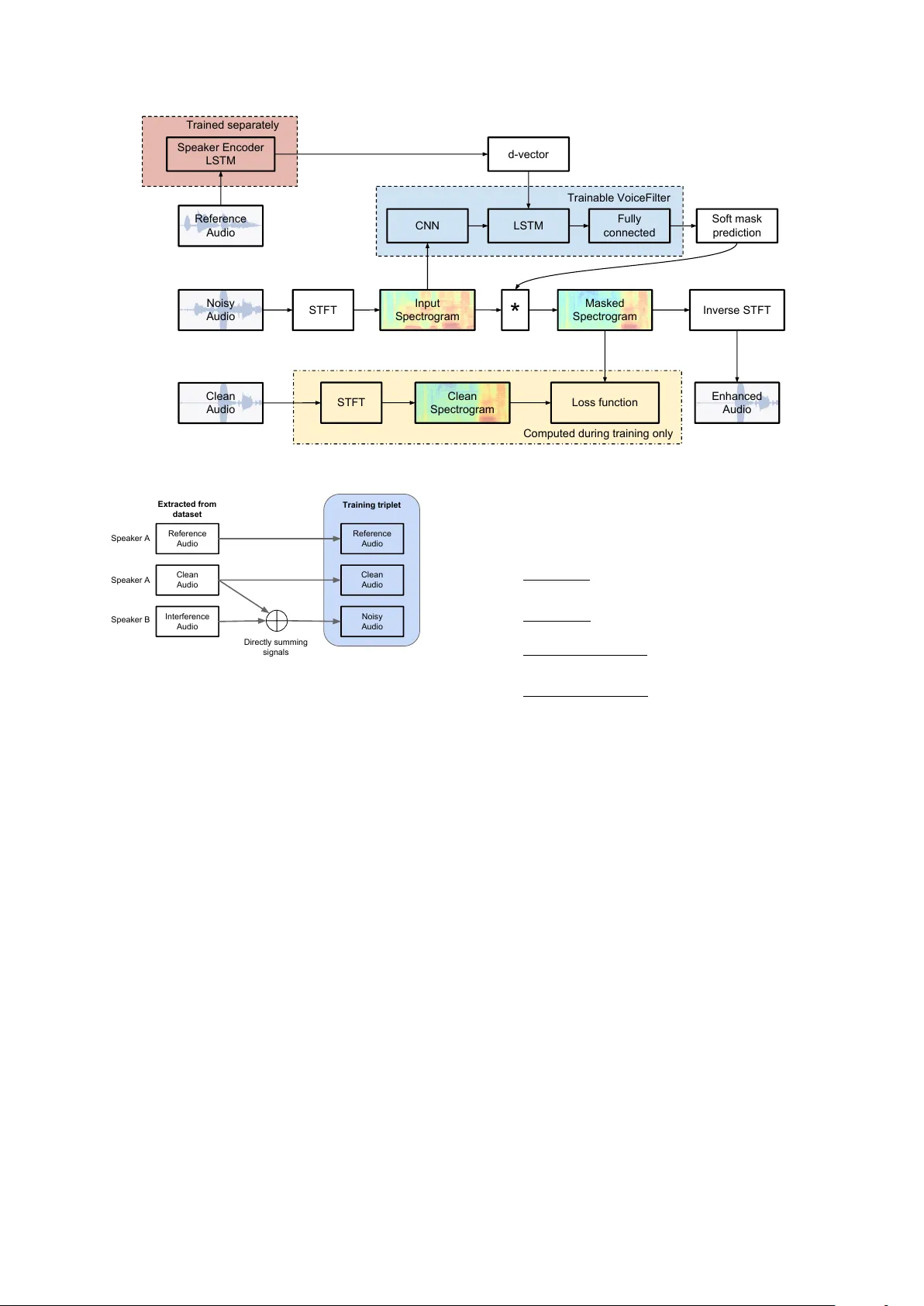
본 논문은 다중 화자 음성 신호에서 특정 화자만을 선택적으로 추출하는 “voice filtering” 문제를 정의하고, 이를 해결하기 위한 두 단계의 딥러닝 기반 시스템을 제안한다. 첫 번째 단계는 화자 인코더(speaker encoder)이며, 3‑layer LSTM 구조에 generalized end‑to‑end loss를 적용해 256‑차원의 d‑vector를 생성한다. 이 인코더는 1.6 초 길이의 로그‑멜 스펙트로그램을 입력으로 받아, 슬라이딩 윈도우와 L2 정규화를 통해 화자별 고유 임베딩을 얻는다. 학습 데이터는 구글 내부 음성 로그(3천4백만 발화, 13만8천 화자)와 공개 데이터(LibriSpeech, VoxCeleb, VoxCeleb2)를 결합한 대규모 셋으로, 기존 i‑vector나 one‑hot 방식보다 화자 구분 성능이 뛰어나다는 점을 실험적으로 입증한다.
두 번째 단계는 VoiceFilter 네트워크이다. 이 네트워크는 noisy 음성의 magnitude spectrogram과 화자 인코더에서 얻은 d‑vector를 동시에 입력받아, 타임‑프레임마다 d‑vector를 convolution 레이어의 출력에 concat한 뒤 LSTM을 통과시킨다. 전체 구조는 8개의 dilated convolution 레이어(필터 64개, 다양한 dilation), 1개의 LSTM(400 유닛), 2개의 fully‑connected 레이어(각 600 유닛)로 이루어지며, 마지막 sigmoid 활성화가 soft mask를 생성한다. 생성된 mask는 noisy spectrogram에 element‑wise 곱해 향상된 magnitude spectrogram을 만든 뒤, 원본 phase를 그대로 사용해 inverse STFT를 수행해 최종 waveform를 복원한다. 손실 함수는 power‑law 압축된 magnitude 차이를 최소화하는 reconstruction loss이며, 이는 직접적인 신호 복원을 목표로 한다.
데이터 생성은 세 가지 오디오(청정 목표 화자, 방해 화자, 레퍼런스 목표 화자)를 이용해 삼중항(triplet) 형태로 구성한다. 레퍼런스 화자 음성은 목표 화자의 다른 발화를 사용하고, 방해 화자 음성은 다른 화자에서 무작위로 선택한다. noisy 입력은 청정 목표 화자와 방해 화자를 단순히 합산하고, 필요에 따라 방해 음성에 0~2 사이의 랜덤 가중치를 곱해도 성능에 큰 차이가 없었다.
평가에서는 두 가지 지표를 사용한다. 첫 번째는 자동 음성 인식(ASR) 시스템의 Word Error Rate(WER)이며, clean, noisy, clean‑enhanced, noisy‑enhanced 네 가지 상황을 비교한다. 목표는 noisy‑enhanced WER을 크게 낮추면서 clean‑enhanced WER은 원래와 거의 동일하게 유지하는 것이다. 두 번째는 Source‑to‑Distortion Ratio(SDR)로, 신호 복원 품질을 dB 단위로 측정한다.
실험 결과, bi‑LSTM을 포함한 VoiceFilter 모델이 가장 높은 성능을 보였다. LibriSpeech 데이터셋에서 bi‑LSTM 모델은 noisy‑enhanced WER을 55.9 %에서 23.4 %로 58 % 상대 감소시켰으며, SDR도 17.9 dB까지 향상되었다. LSTM이 없는 모델은 성능이 크게 떨어졌고, uni‑LSTM 모델도 bi‑LSTM에 비해 약간 낮은 결과를 보였다. VCTK 데이터셋에서도 비슷한 경향이 나타났으며, 특히 LibriSpeech에서 학습된 모델이 VCTK에서도 좋은 일반화 능력을 보여, 대규모 화자 다양성이 모델 성능에 중요한 역할을 함을 확인했다.
또한, 기존의 화자‑독립적 분리 기법(예: deep clustering, deep attractor network)과 비교했을 때, VoiceFilter는 화자 수 추정 및 퍼뮤테이션 문제를 회피하고, 단일 출력만을 제공함으로써 실시간 시스템에 더 적합하다. 화자 인코더와 VoiceFilter를 별도 학습함으로써 데이터 요구사항을 분리하고, 추론 시 d‑vector를 한 번만 계산해 여러 입력에 재사용할 수 있는 효율성을 확보했다.
결론적으로, 이 논문은 화자 임베딩을 활용한 스펙트로그램 마스킹 방식이 다중 화자 환경에서 ASR 성능을 크게 개선할 수 있음을 실증하였다. 향후 연구에서는 다중 목표 화자 동시 처리, 복합 잡음 환경, 그리고 화자 인코더와 VoiceFilter를 joint end‑to‑end로 학습하는 방안을 탐색함으로써 더욱 강력한 음성 전처리 시스템을 구축할 수 있을 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기