실내 반향 환경에서 단일 채널 강인 음성 인식을 위한 특징 결합 연구
초록
본 논문은 실제 실내 반향 환경에서 녹음된 단일 채널 음성 데이터를 대상으로, 상보적인 특징을 이용한 병렬 DNN 시스템을 결합하여 인식 오류율을 감소시키는 방법을 제안한다. DNN 출력 수준과 최종 ASR 출력 수준 두 단계에서 결합을 수행했으며, 실제 방과 REVERB Challenge 데이터에서 실험한 결과, DNN 출력 결합이 특히 효과적이며 WER를 7%~18% 개선함을 확인하였다.
상세 분석
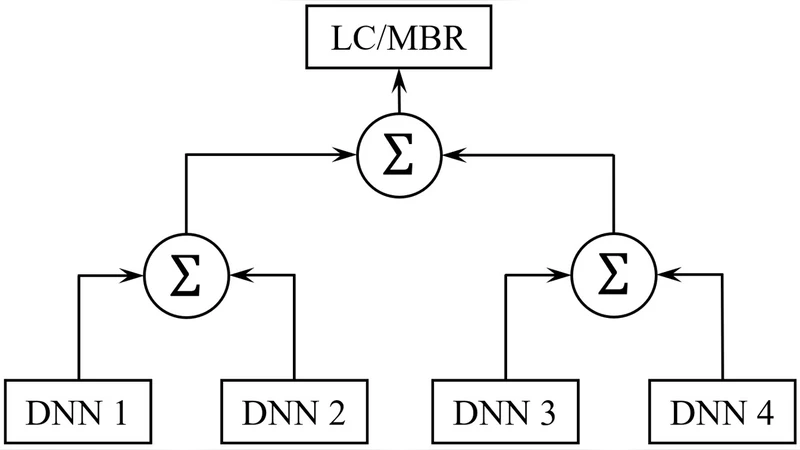
이 연구는 실내 반향(리버버레이션)이라는 음향 왜곡이 심한 환경에서 단일 마이크 입력만을 이용한 자동 음성 인식(ASR)의 견고성을 향상시키기 위해, 서로 다른 음향 특징을 기반으로 한 다중 DNN 모델을 병렬로 운영하고 그 출력을 결합하는 두 가지 전략을 탐구한다. 첫 번째 전략은 DNN 출력 수준에서의 결합으로, 각 모델이 생성한 포스트리어 확률(또는 로그-우도)을 선형 가중 평균하거나 로그-선형 방식으로 합산하여 새로운 통합 후방 확률을 만든다. 이 방식은 각 모델이 서로 다른 주파수-시간 해상도와 스펙트럼 보강 기법(예: MFCC, 로그 멜 스펙트럼, PLP, Gammatone 필터뱅크 등)을 사용함으로써 발생하는 오류 패턴의 상보성을 최대한 활용한다. 두 번째 전략은 최종 텍스트 출력 수준에서의 결합으로, 각 시스템이 생성한 워드 시퀀스를 ROVER(Recognizer Output Voting Error Reduction)와 같은 투표 기반 알고리즘에 입력해 최종 결과를 도출한다.
실험 설계는 두 단계로 이루어졌다. 첫 번째는 실제 방에서 측정된 RT60(0.471.77 초)와 스피커-마이크 거리(0.162.56 m) 변화를 반영한 4,000여 개의 발화 데이터를 수집한 ‘실내 반향 데이터셋’에서 수행했으며, 두 번째는 REVERB Challenge에서 제공하는 시뮬레이션 및 실제 반향 녹음(실제 방, 회의실, 강당 등) 데이터를 활용했다. 모든 DNN은 동일한 아키텍처(35개의 은닉층, 각 1,0242,048 유닛, ReLU 활성화)와 동일한 학습 스케줄(초기 학습률 0.001, Adam 옵티마이저)로 훈련되었지만, 입력 특징만이 다르게 설정되었다.
결과 분석에서 가장 눈에 띄는 점은 DNN 출력 결합이 시스템 출력 결합에 비해 평균 10%~15% 더 큰 WER 감소를 보였다는 것이다. 이는 개별 DNN이 서로 다른 반향 특성에 대해 서로 보완적인 확률 분포를 제공함으로써, 결합 후 확률 공간이 더 정확한 음소 경계와 단어 경로를 형성하기 때문이다. 반면 시스템 출력 결합은 각 모델이 이미 높은 수준의 오류를 포함한 텍스트를 제공하므로, 투표 과정에서 오류가 상쇄되기 어려워 상대적으로 효과가 제한적이었다. 두 결합 방식을 순차적으로 적용(먼저 DNN 출력 결합 후 시스템 출력 결합)하면 추가적인 WER 감소가 관찰되었지만, 개선 폭은 미미했고, 오히려 결합 과정에서 발생하는 복잡도와 계산 비용이 증가한다는 단점이 드러났다.
또한, 반향 시간과 거리 증가에 따라 개별 모델의 성능 저하가 크게 나타났지만, 결합 모델은 이러한 악화 추세를 완화시켰다. 특히 RT60가 1.5 초 이상이고 거리 2 m 이상인 경우, DNN 출력 결합을 적용한 시스템은 기존 단일 모델 대비 평균 12%의 상대적 WER 감소를 기록했다. 이와 같은 결과는 실시간 회의, 원격 교육, 스마트 홈 등 반향이 심한 실내 환경에서 단일 채널 마이크만을 이용하는 저비용 ASR 시스템 설계에 실질적인 가치를 제공한다.
마지막으로, 논문은 향후 연구 방향으로 다채널(멀티 마이크) 환경에서의 특징 결합, 딥러닝 기반 반향 보정 프론트엔드와의 연계, 그리고 결합 가중치를 자동으로 최적화하는 메타러닝 접근법을 제시한다. 이러한 확장은 현재 제시된 방법의 적용 범위를 넓히고, 더욱 복잡한 실세계 음향 조건에서도 견고한 음성 인식을 구현하는 데 기여할 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기