시각 추적 기반 가중 딜레이‑합 빔포밍을 이용한 인간‑로봇 상호작용 향상
초록
본 논문은 로봇 카메라의 시각 서보잉을 이용해 목표 물체를 영상 중앙에 고정시키고, 이미지 처리로 얻은 방향 정보를 마이크 어레이의 가중 딜레이‑합 빔포밍에 결합한다. PR2 로봇 실험에서 정적·동적 머리 자세와 외부 잡음원을 변화시켜 검증했으며, 순수 빔포밍 대비 최대 34%의 단어 오류율(WER) 감소를 달성하였다.
상세 분석
이 연구는 인간‑로봇 상호작용(HRI) 환경에서 음성 인식 성능을 향상시키기 위해 청각과 시각 정보를 융합하는 새로운 프레임워크를 제안한다. 핵심 아이디어는 마이크 어레이의 빔포밍 이득이 메인 로브와 목표 방향 사이의 각도 차이에 크게 의존한다는 점을 이용해, 로봇 머리의 시각 서보잉으로 그 각도 차이를 최소화하는 것이다. 구체적으로, 로봇 카메라가 촬영한 영상에서 객체 검출 및 추적 알고리즘(예: 칼만 필터 기반 색상/형태 기반 추적)을 적용해 목표 물체의 2D 이미지 좌표를 얻고, 이를 로봇 좌표계에 매핑해 목표 방향(azimuth, elevation)을 계산한다. 동시에 마이크 어레이는 다채널 음성 신호를 수집하고, 전통적인 딜레이‑합(Delay‑and‑Sum) 빔포밍에 가중치를 부여하는 방식으로 보강한다. 가중치는 시각에서 추정된 방향과 마이크 어레이의 실제 응답 축 사이의 각도 차이에 역비례하도록 설계되었으며, 이는 빔포밍의 직접성(directivity) 손실을 보정한다.
시스템 아키텍처는 크게 세 부분으로 나뉜다. 첫 번째는 시각 모듈로, 객체 검출·추적·좌표 변환을 담당한다. 두 번째는 청각 모듈로, 마이크 어레이 캘리브레이션, 신호 전처리(노이즈 억제, 프레임 동기화) 및 가중 딜레이‑합 빔포밍을 수행한다. 세 번째는 통합 제어 모듈로, 시각 모듈에서 제공된 목표 방향을 실시간으로 빔포밍 가중치에 반영하고, 동시에 로봇 머리의 서보잉 명령을 생성한다.
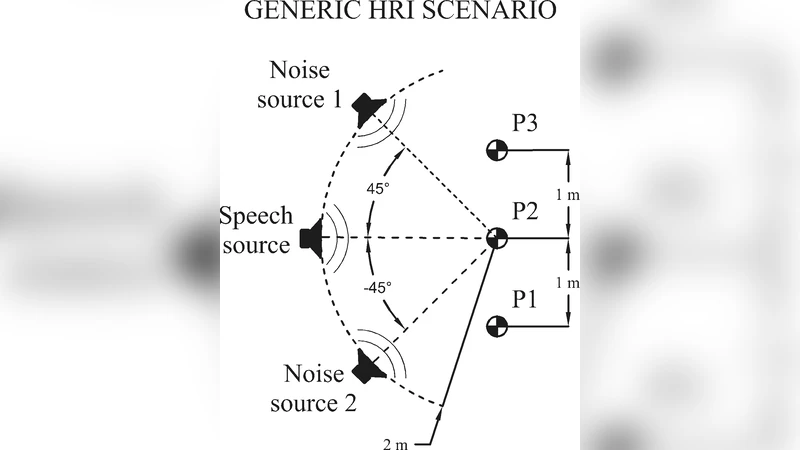
실험은 PR2 로봇에 4‑채널 마이크 어레이와 RGB‑D 카메라를 장착하고, 정적 머리와 회전 가능한 머리 두 가지 설정에서 수행되었다. 잡음원은 한 개와 두 개를 사용해 각각 백색 잡음과 실제 사람의 대화 소리를 재현하였다. 평가 지표는 음성 인식 엔진(예: Google Speech API)의 단어 오류율(WER)이며, 시각‑청각 융합 시스템이 순수 딜레이‑합 빔포밍 대비 평균 21% 개선, 최악의 경우 34%까지 WER을 감소시켰다. 특히 동적 머리 상황에서 시각 서보잉이 목표 물체를 지속적으로 중앙에 유지함으로써 빔포밍 각도 오차가 최소화되고, 급격한 머리 회전에도 시스템이 빠르게 재조정되는 것이 확인되었다.
이 논문의 주요 기여는 (1) 시각 서보잉을 이용해 물리적 빔포밍 각도 오차를 사전에 감소시키는 전략, (2) 시각에서 얻은 방향 정보를 가중 딜레이‑합 빔포밍에 정량적으로 통합하는 수식적 프레임워크, (3) 실제 모바일 로봇 플랫폼에서 정적·동적 상황 및 다양한 잡음 환경을 포괄적으로 평가한 실증적 결과이다. 한계점으로는 객체 검출·추적 실패 시 빔포밍 가중치가 부정확해질 위험, 그리고 현재 2D 영상 기반 방향 추정이 깊이 정보를 충분히 활용하지 못해 고도 차이에 민감도가 낮다는 점을 들 수 있다. 향후 연구에서는 3D 포인트 클라우드와 딥러닝 기반 객체 인식을 결합해 방향 추정 정확도를 높이고, 다중 객체 상황에서의 혼합 빔포밍 전략을 탐구할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기