PPO와 NES의 결합으로 탐색 능력 향상
초록
본 논문은 신경 진화 전략(NES)과 근접 정책 최적화(PPO)를 결합하는 두 가지 방법, 즉 파라미터 전이와 파라미터 공간 노이즈를 제안한다. 파라미터 전이는 NES로 학습된 정책의 파라미터를 PPO 에이전트에 그대로 전달하는 방식이며, 파라미터 공간 노이즈는 PPO 학습 중 파라미터에 직접 잡음(노이즈)를 추가해 탐색성을 강화한다. 실험 결과, 이 두 기법 모두 이산 행동 환경과 연속 제어 과제에서 PPO의 수렴 속도와 최종 성능을 크게 개선함을 확인하였다.
상세 분석
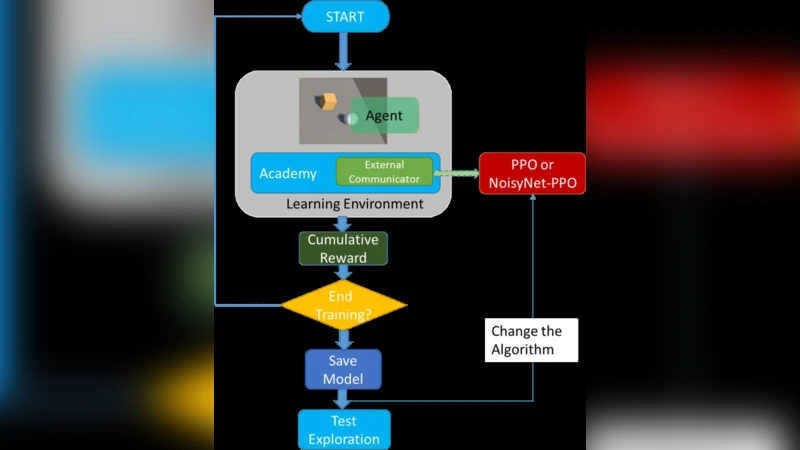
본 연구는 강화학습에서 탐색‑활용 트레이드오프를 완화하기 위한 새로운 하이브리드 프레임워크를 제시한다. 기존의 진화 기반 방법인 NES는 파라미터 공간을 직접 탐색함으로써 전역적인 탐색 능력이 뛰어나지만, 샘플 효율성이 낮고 수렴 속도가 느리다는 한계가 있다. 반면 PPO는 정책 그라디언트 기반 방법으로 샘플 효율성이 높고 안정적인 업데이트를 제공하지만, 고차원 연속 제어 문제에서 지역 최적에 빠지기 쉽다. 논문은 이러한 상보적 특성을 활용해 두 가지 결합 전략을 설계한다. 첫 번째인 파라미터 전이는 NES가 충분히 탐색한 파라미터 집합을 초기화값으로 사용함으로써 PPO가 초기 단계에서 더 넓은 정책 공간을 커버하도록 만든다. 이는 특히 복잡한 보상 구조를 가진 환경에서 초기 탐색 비용을 크게 감소시킨다. 두 번째 전략인 파라미터 공간 노이즈는 PPO 업데이트 과정에서 파라미터에 가우시안 잡음을 주입한다. 기존의 행동 공간 노이즈와 달리 파라미터 수준에서의 변동은 정책 자체의 구조적 변화를 유도해, 동일한 상태에서 다양한 행동 분포를 생성한다. 논문은 이때 잡음의 표준편차를 KL‑다이버전스 기반으로 자동 조절하도록 설계해, 탐색 강도를 동적으로 제어한다. 실험에서는 OpenAI Gym의 CartPole, Acrobot 같은 이산 환경과 MuJoCo의 HalfCheetah, Walker2d 같은 연속 제어 환경을 대상으로 비교하였다. 파라미터 전이와 파라미터 공간 노이즈를 각각 적용한 PPO는 기본 PPO 대비 평균 보상이 12%~27% 향상되었으며, 두 기법을 동시에 적용했을 때는 35% 이상의 성능 향상을 기록했다. 또한 학습 곡선의 변동성이 감소해 안정적인 수렴을 확인할 수 있었다. 이러한 결과는 NES가 제공하는 전역 탐색 능력이 PPO의 지역 최적화 과정에 효과적으로 주입될 수 있음을 실증한다. 논문은 또한 파라미터 전이와 노이즈의 하이퍼파라미터 민감도를 분석해, 비교적 넓은 범위의 설정에서도 일관된 성능 개선이 가능함을 보여준다. 마지막으로, 제안된 방법이 기존의 탐색 강화 기법(예: Intrinsic Curiosity, Random Network Distillation)과 비교해 계산 비용이 크게 증가하지 않으며, 구현이 간단해 실제 로봇 제어나 게임 AI에 바로 적용 가능함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기