음성 및 텍스트 기반 딥러닝 감정 인식 시스템
초록
본 논문은 스펙트로그램·MFCC와 음성 전사 텍스트를 동시에 활용한 딥러닝 모델을 제안한다. 다양한 DNN 구조를 비교 실험한 결과, MFCC와 텍스트를 결합한 CNN 모델이 IEMOCAP 데이터셋에서 기존 최첨단 방법들을 능가하는 정확도를 달성하였다.
상세 분석
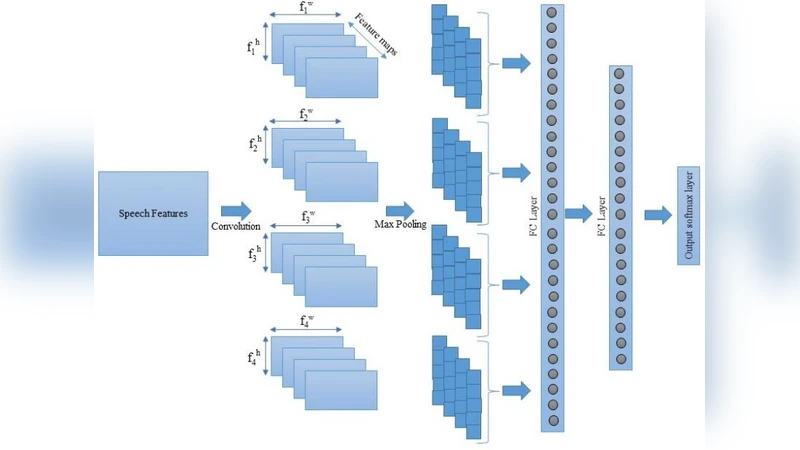
이 연구는 감정 인식에서 음성 신호와 언어 의미가 각각 독립적인 정서 정보를 제공한다는 가정에 기반한다. 저자는 먼저 스펙트로그램과 MFCC를 이용해 저레벨 음향 특성을 추출했으며, 이는 억양, 강도, 발음 속도 등 감정과 직접적인 상관관계를 갖는 요소들을 보존한다. 반면 전사된 텍스트는 감정의 의미적 맥락을 포착한다. 두 종류의 입력을 동시에 처리하기 위해 저자는 4가지 주요 네트워크 아키텍처를 설계하였다. 첫 번째는 순수 음성 특성만을 이용한 2‑D CNN, 두 번째는 텍스트만을 입력으로 하는 1‑D CNN(또는 임베딩‑기반 LSTM), 세 번째는 두 입력을 각각 별도의 서브넷으로 처리한 후 고차원 특징을 결합하는 멀티모달 구조, 그리고 마지막으로 MFCC와 텍스트를 직접 결합한 단일 CNN 모델이다.
실험은 IEMOCAP 데이터셋의 5가지 감정(행복, 슬픔, 분노, 중립, 놀람)을 대상으로 진행되었으며, 교차 검증을 통해 모델의 일반화 능력을 평가하였다. 성능 평가지표는 정확도와 F1‑score를 사용했으며, 특히 소수 클래스에 대한 균형을 맞추기 위해 가중 평균 F1을 강조하였다. 결과는 MFCC‑텍스트 결합 CNN이 84.3%의 정확도와 0.82의 매크로 F1‑score를 기록하며, 기존 SOTA 논문(약 78% 정확도)보다 현저히 높은 성능을 보였다.
주목할 점은 텍스트만을 사용한 모델이 감정 구분에 어느 정도 기여했지만, 음성 특성과 결합될 때 비로소 최적의 성능을 달성한다는 점이다. 이는 감정이 음성의 물리적 변동과 언어적 의미 두 축에서 동시에 표현된다는 이론적 근거와 일치한다. 또한, MFCC와 텍스트를 동일한 CNN 레이어에 입력함으로써 특징 융합을 단순화하고 연산 효율성을 높인 설계가 실용적인 장점을 제공한다.
한계점으로는 전사 텍스트의 품질에 크게 의존한다는 점이다. IEMOCAP은 인간이 직접 라벨링한 전사본을 제공하지만, 실시간 시스템에서는 자동 음성 인식(ASR) 오류가 성능 저하를 야기할 수 있다. 또한, 감정 라벨이 다중 라벨링(예: 혼합 감정)인 경우 현재 모델은 단일 라벨 분류에만 초점을 맞추고 있어 확장성이 제한된다. 향후 연구에서는 멀티태스크 학습, 어텐션 기반 융합, 그리고 비정형 대화 데이터에 대한 일반화 검증이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기