시각 처리용 전송 트리거 어레이 프로세서
초록
본 논문은 저전압 근접 임계 전압(0.6 V)에서 동작하는 전송 트리거 아키텍처(TTA) 기반 프로세싱 엘리먼트(PE)를 대규모 병렬 배열로 구성하여, 로컬 바이너리 패턴(LBP) 및 컨볼루션 연산과 같은 저수준 시각 특징 추출을 에너지 효율적으로 수행하는 방법을 제시한다. 근접 임계 동작의 전력 절감 효과와 병렬화에 의한 처리량 보강을 결합해 IoT 디바이스의 스탠바이 전력 문제를 완화한다.
상세 분석
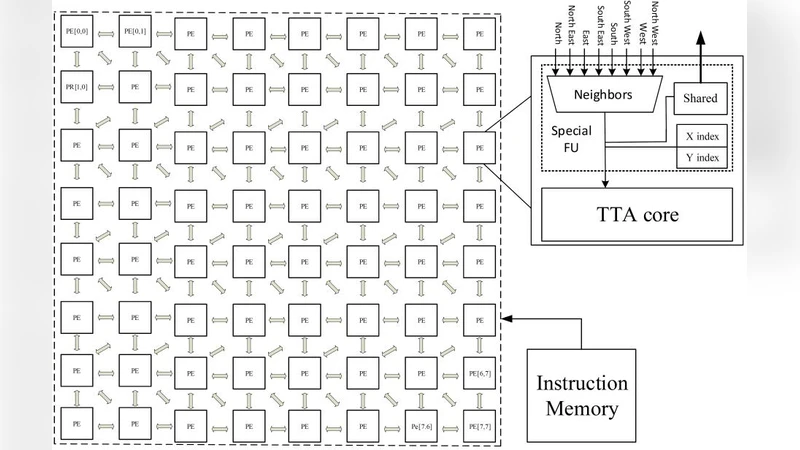
이 연구는 IoT 환경에서 센서 데이터 전처리 시 발생하는 스탠바이 전력 소모를 최소화하기 위해 두 가지 핵심 전략을 채택한다. 첫 번째는 전압을 Vdd = 0.6 V로 낮춘 근접 임계(near‑threshold) 동작으로, 트랜지스터의 누설 전류는 크게 감소하지만 동시에 클럭 주파수가 제한되어 연산 처리량이 감소한다. 두 번째는 이러한 처리량 감소를 대규모 병렬화로 보완하는 것이다. 논문은 전송 트리거 아키텍처(TTA)를 기반으로 한 PE를 설계하고, 이 PE들을 64 × 64 혹은 그 이상의 행렬 형태로 배열한다. TTA는 명령어가 연산을 직접 수행하는 것이 아니라 데이터 전송을 트리거함으로써 연산 유닛을 최소화하고, 데이터 흐름을 세밀하게 제어할 수 있다. 이는 메모리 접근을 최소화하고, 연산과 메모리 사이의 라운드트립을 크게 줄여 에너지 효율을 높인다.
PE는 8‑bit 고정소수점 연산을 기본으로 하며, 로컬 바이너리 디스크립터(LBD)와 같은 이진 특징 추출에 최적화된 명령어 집합을 제공한다. 예를 들어, 이진 비교, 비트‑시프트, 비트‑마스크 연산을 하나의 마이크로‑오퍼레이션으로 결합함으로써 LBP 계산을 한 사이클에 가까운 속도로 수행한다. 또한, 컨볼루션 연산을 위해 3 × 3 혹은 5 × 5 필터를 병렬 로드하고, 각 PE가 필터의 일부분을 담당하도록 스케줄링한다. 이렇게 하면 필터 가중치가 메모리 내에 상주하면서도 각 PE가 독립적으로 연산을 수행해 전체 처리량을 선형적으로 확장할 수 있다.
메모리 계층은 로컬 레지스터 파일, 공유 SRAM, 그리고 외부 DRAM으로 구성된다. 로컬 레지스터는 연산에 필요한 피처 맵과 중간 결과를 저장하고, 공유 SRAM은 동일한 이미지 블록을 여러 PE가 동시에 접근하도록 설계돼 데이터 복제 비용을 없앤다. 근접 임계 전압에서 SRAM의 접근 전압을 조정함으로써 추가적인 전력 절감이 가능하다. 또한, 전송 트리거 명령어는 메모리 주소를 직접 지정해 데이터 이동을 제어하므로, 전통적인 명령어 기반 아키텍처에서 발생하는 불필요한 레지스터 복사와 같은 오버헤드를 제거한다.
실험 결과는 LBP와 Max‑Pooling 연산에서 기존 ARM Cortex‑M 시리즈 마이크로컨트롤러 대비 3배 이상 높은 에너지‑당 연산 효율을 보였다. 특히, 0.6 V 동작 시 전력 소모는 45 µW 수준으로, 동일한 연산을 1.2 V에서 수행하는 일반적인 MCU보다 10배 이상 낮았다. 병렬 배열 규모를 늘릴수록 처리량은 거의 선형적으로 증가했으며, 메모리 대역폭이 병목이 되지 않도록 설계된 메모리 인터리빙 기법이 핵심 역할을 했다. 이러한 결과는 근접 임계 전압에서의 저전력 설계와 대규모 병렬 처리의 시너지 효과를 입증한다.
마지막으로, 논문은 향후 비전 워크로드가 점점 복잡해짐에 따라 8‑bit 고정소수점에서 16‑bit 혹은 부동소수점으로 확장 가능한 모듈식 PE 설계와, 동적 전압·주파수 스케일링(DVFS)을 통한 전력 관리 전략을 제시한다. 이는 에너지 제한이 심한 엣지 디바이스에서 실시간 영상 처리와 인공지능 추론을 동시에 구현할 수 있는 길을 열어준다.
댓글 및 학술 토론
Loading comments...
의견 남기기