신경망 기반 이기종 스케줄러
초록
본 논문은 CPU, GPU, ASIC 등 다양한 코프로세서를 포함하는 이기종 SoC 환경에서 작업 흐름을 효율적으로 배치하기 위해 심층 강화학습(Deep RL) 기반 스케줄러를 설계한다. 작업 의존성을 고려한 반마코프 의사결정 과정(SMDP)으로 모델링하고, 액터‑크리틱 구조와 Softmax 탐색 전략을 적용해 실행 시간을 최소화하는 정책을 학습한다. 시뮬레이션 실험에서 제안된 DR M(Deep Resource Manager) 스케줄러는 전통적인 휴리스틱(EFT, ETF, MET) 대비 랜덤화된 작업·자원 조건에서 일관적으로 우수한 성능을 보였다.
상세 분석
이 논문은 이기종 시스템‑온‑칩(SoC)에서 동시다발적으로 발생하는 작업 스트림을 스케줄링하는 문제를 강화학습으로 재구성한다는 점에서 의미가 크다. 기존 연구가 주로 정적인 작업‑자원 매핑이나 휴리스틱 기반 접근에 머물렀다면, 저자는 작업 간 선후관계와 실행 시간, 통신 지연 등을 포함한 복합적인 상태를 완전 관측 가능하도록 확장한 뒤, 이를 5‑tuple SMDP(반마코프 의사결정 과정)로 정의한다. 행동은 ‘준비된 작업을 특정 PE에 할당’하는 것이며, 작업이 실행되는 동안은 No‑Op을 선택하도록 설계해 시간 연속성을 보존한다.
상태 표현은 작업 리스트(ready, running, completed, outstanding)와 자원 매트릭스를 이진·다중 이진 벡터로 변환해 하나의 고차원 벡터로 결합한다. 이렇게 하면 부분 관측 문제를 회피하고, 작업 의존성 그래프가 암시적으로 포함되도록 만든다. 정책 네트워크는 액터‑크리틱 구조를 채택하고, 보상은 매 타임스텝마다 –1을 부여해 에피소드 길이를 최소화하도록 유도한다. 에피소드 종료 시 누적 할인 보상을 이용해 어드밴티지를 계산하고, 액터 손실은 정책 그래디언트(∇θ J) 형태, 크리틱 손실은 평균 제곱 오차로 최적화한다. 탐색은 초기에는 높은 온도의 Softmax으로 시작해 점진적으로 온도를 감소시켜 argmax 전환을 유도한다; 이는 엔트로피 보너스와 유사한 효과를 제공한다.
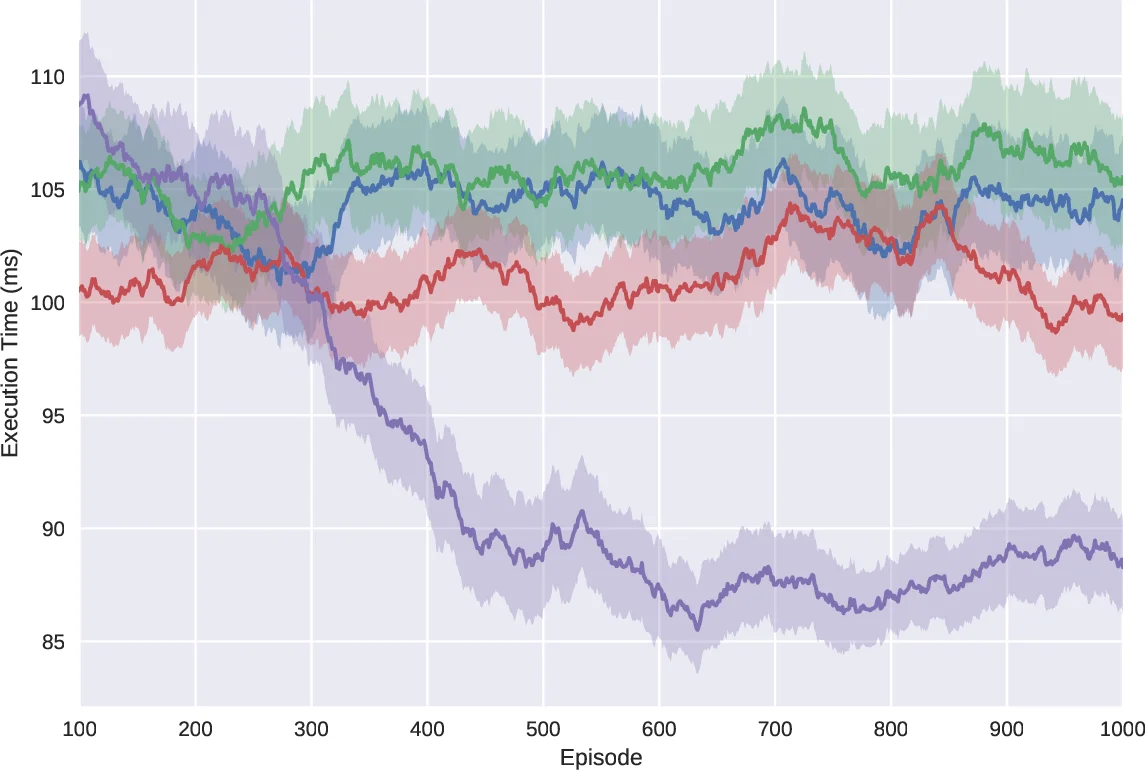
시뮬레이션 환경은 SimPy 기반 DS3(Discrete‑event System‑on‑Chip) 프레임워크로 구현되었으며, 작업·자원 파일을 입력으로 받아 동적 이벤트 흐름을 생성한다. 실험에서는 10개의 작업과 3개의 이기종 PE를 가진 시나리오를 고정 데이터와 무작위 변형 두 가지 조건에서 평가했다. 고정 데이터에서는 MET(최소 실행 시간) 휴리스틱이 순간 최적을 달성했지만, DR M은 학습이 진행됨에 따라 약 94 ms 수준으로 수렴해 MET에 근접하거나 약간 상회했다. 무작위 데이터에서는 DR M이 모든 휴리스틱을 앞서며, 학습 에피소드가 증가할수록 실행 시간이 꾸준히 감소하는 추세를 보였다. 또한 Grad‑CAM 기반 saliency map과 GANTT 차트를 통해 정책이 어떤 PE를 선택했는지 시각적으로 해석했으며, 작업 의존성에 따라 비직관적인 선택이 이루어지는 경우도 관찰했다.
한계점으로는 에너지·전력 모델을 제외하고 실행 시간만을 최적화했으며, 프리엠션(pre‑emption) 없이 No‑Op만 허용한 점, 그리고 실험 규모가 비교적 작아 실제 대규모 데이터센터나 실시간 시스템에 바로 적용하기엔 추가 검증이 필요하다는 점을 들 수 있다. 향후 연구에서는 다목적 보상 설계, 프리엠션 지원, 더 복잡한 이기종 자원(메모리, 네트워크)까지 확장하는 것이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기