LSTM으로 동적 카운팅을 구현하고 계층 구조를 학습한다
초록
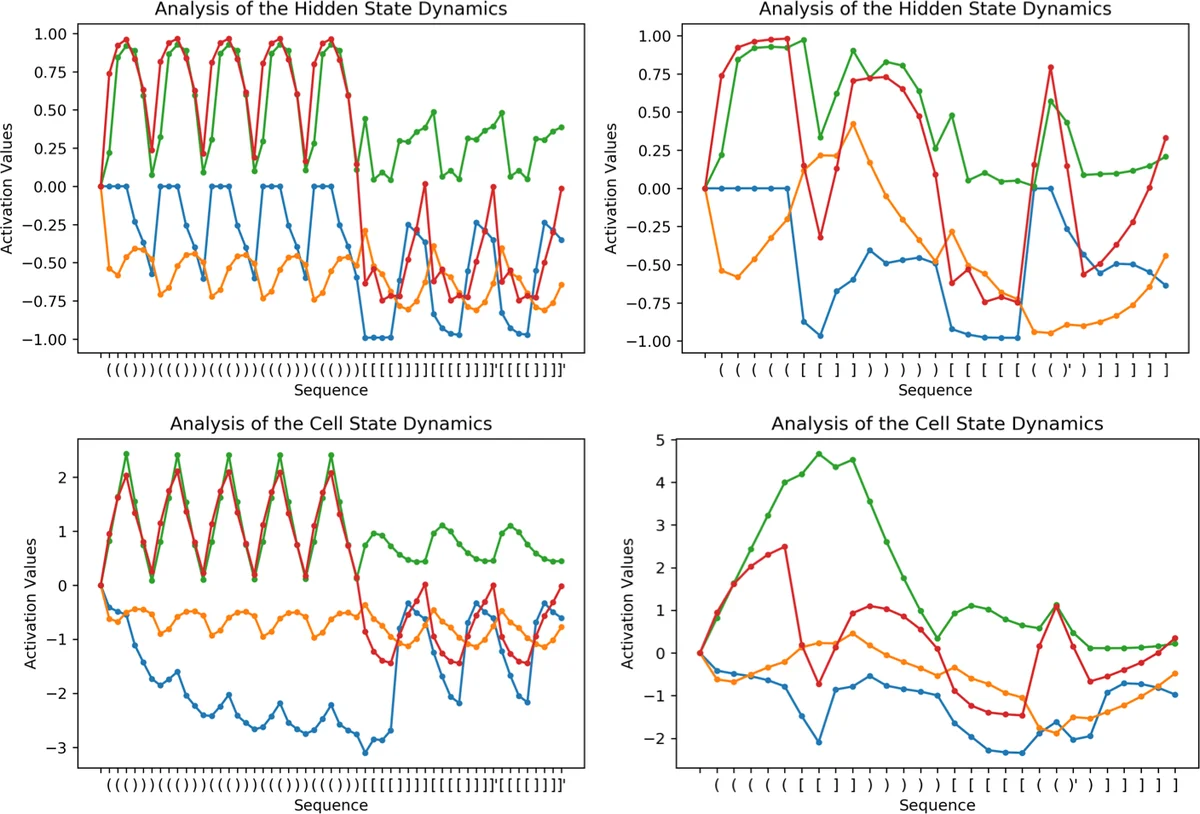
본 논문은 소형 LSTM 네트워크가 동적 카운팅을 통해 Dyck‑1 언어와 여러 Dyck‑1 언어의 셔플을 정확히 인식함을 실험적으로 입증한다. 단일 은닉 유닛 하나만으로도 Dyck‑1을 완벽히 학습할 수 있지만, 스택 구조가 필요한 Dyck‑2 언어는 학습에 실패한다.
상세 분석
이 연구는 LSTM이 실제로 카운터 머신을 모방할 수 있는지를 검증하기 위해 네 가지 인공 언어(Dyck‑1, Dyck‑2, Shuffle‑2, Shuffle‑6)를 사용하였다. 실험 설계는 모델 크기를 10개 이하의 은닉 유닛으로 제한함으로써 네트워크가 단순히 훈련 데이터를 암기하는 것이 아니라 내부 메커니즘을 형성했는지를 확인한다. LSTM은 셀 상태와 게이트 동작을 통해 실시간으로 정수 카운터를 유지하고, 각 괄호 종류별로 독립적인 카운터를 업데이트한다. 특히 Shuffle‑2와 Shuffle‑6 실험에서 LSTM이 100% 정확도에 근접한 성능을 보인 것은, 다중 카운터를 임의의 턴 수만큼 전환하면서도 정확히 동작한다는 강력한 증거이다. 반면, 동일한 설정의 Elman‑RNN과 GRU는 카운터 유지 능력이 제한적이어서 짧은 테스트에서는 어느 정도 성능을 보였지만, 길이가 늘어나면 급격히 성능이 저하된다. Dyck‑2 실험에서는 모든 모델이 0%에 가까운 정확도를 기록했는데, 이는 Dyck‑2가 단순 카운터가 아닌 스택 기반의 중첩 구조를 요구하기 때문이다. LSTM이 현재의 게이트 구조만으로는 스택을 완전하게 구현하지 못한다는 점을 시사한다. 또한, 논문은 학습 목표를 “다음 가능한 문자 집합 예측”으로 설정함으로써, 모델이 열린 괄호는 언제든지 예측하고, 닫힌 괄호는 현재 카운터 값이 양수일 때만 예측하도록 강제한다. 이 방식은 전통적인 다음 문자 예측(task)과 달리 언어의 구조적 제약을 직접 반영하므로, 모델의 내부 상태 해석이 용이해진다. 실험 결과는 LSTM이 단일 은닉 유닛으로도 Dyck‑1을 완벽히 학습하고, 다중 카운터를 필요로 하는 셔플 언어에서도 높은 일반화 능력을 보임을 보여준다. 이는 LSTM이 제한된 파라미터로도 동적 카운팅을 수행할 수 있음을 의미하며, 자연어 처리에서 계층적 구조를 추론하는 데 유용한 메커니즘으로 활용될 가능성을 제시한다. 그러나 스택 기반 언어에 대한 한계는 여전히 존재하므로, 향후 연구에서는 외부 메모리 모듈이나 새로운 게이트 설계가 필요할 것으로 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기