훈련 데이터가 노래 보컬 분리 성능을 좌우한다
초록
본 연구는 최신 U‑Net 기반 보컬·반주 분리 모델을 동일하게 학습시킨 뒤, 세 종류의 훈련 데이터(공개 MUSDB, 대규모 사설 Bean, 추정된 보컬을 포함한 Catalog)와 데이터 증강 기법이 성능에 미치는 영향을 체계적으로 평가한다. 결과는 데이터 양·다양성·품질이 모두 중요한 요인이며, 특히 고품질·다양한 곡을 많이 포함할수록 SDR이 크게 향상된다는 것을 보여준다. 반면 일반적인 스펙트로그램 변환 기반 증강은 성능 개선 효과가 미미했다.
상세 분석
이 논문은 보컬·반주 분리 성능을 좌우하는 훈련 데이터의 특성을 정량적으로 규명하고자 한다. 먼저 세 가지 데이터셋을 정의한다. MUSDB는 150곡(10 시간) 정도의 고품질 다중트랙 공개 데이터로, 원본 보컬·반주가 정확히 분리돼 있다. Bean은 24 097곡(≈95 시간) 규모의 사설 데이터로, 동일한 고품질 분리본을 제공하며 아티스트 단위로 학습·검증·테스트를 겹치지 않게 설계했다. Catalog은 Deezer 음악 카탈로그에서 원곡·반주 쌍을 매칭해 만든 28 810곡(≈79 시간) 데이터로, 보컬은 믹스와 반주 스펙트로그램 차이를 절반 웨이브 정류(half‑wave rectified) 방식으로 추정했기 때문에 잡음과 잔류 악기 성분이 섞여 있다. 즉, 품질이 낮은 ‘약한 라벨’ 데이터이다.
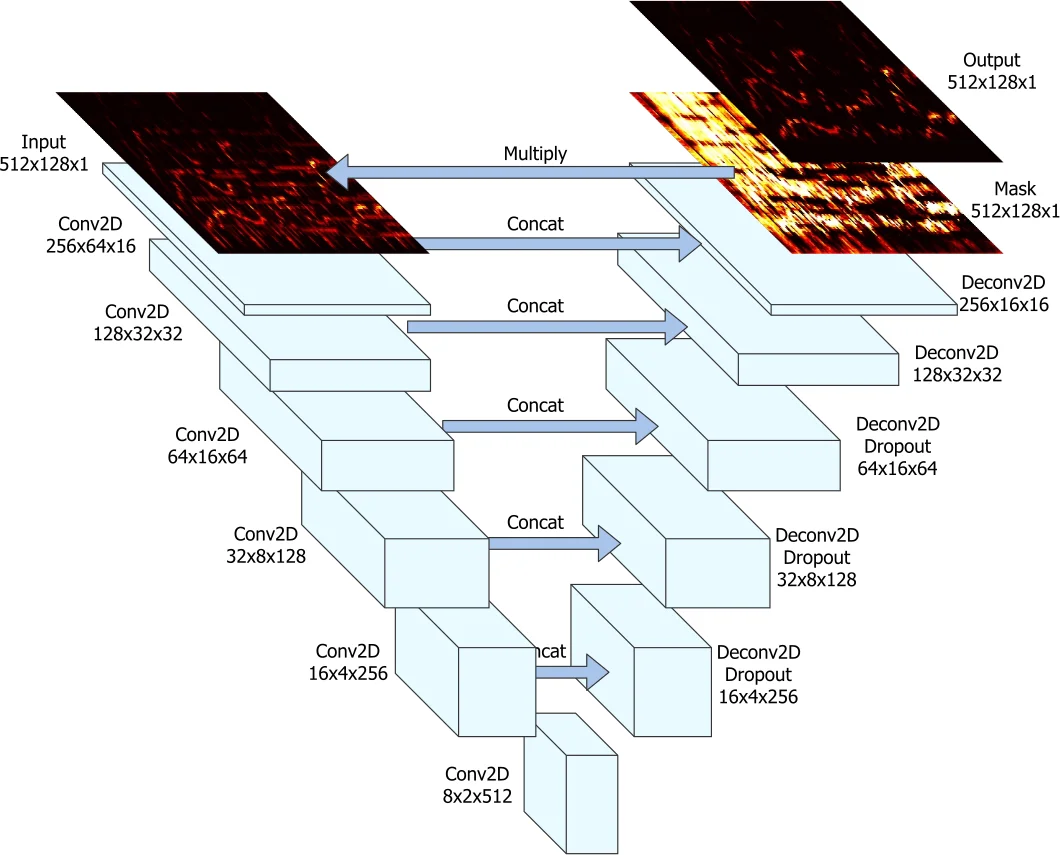
모델은 기존 연구에서 최고 성능을 기록한 U‑Net 구조를 채택했으며, 스테레오 입력을 3차원 텐서(채널, 시간, 주파수)로 처리하도록 확장했다. 모든 오디오를 22 050 Hz로 다운샘플링하고 11.88 초 길이의 세그먼트로 자른 뒤, STFT(윈도우 2048, 홉 512)로 스펙트로그램을 만든다. 학습은 500 epoch, 배치 1, L1 손실, Adam(learning rate 0.0001)으로 진행했으며, 조기 종료를 위해 검증 세트를 활용했다.
실험은 네 가지 축으로 구성된다. (1) 데이터 규모·다양성·품질 비교: 동일 모델을 각각 MUSDB, Bean, Catalog A, Catalog B에 학습시켜 테스트셋(MUSDB + Bean)에서 SDR, SIR, SAR을 측정했다. 결과는 Bean이 가장 높은 평균 SDR(≈6.8 dB)을 기록했으며, Catalog A는 품질 저하로 인해 약 0.9 dB 낮았다. Catalog B는 장르 재균형을 통해 약간 개선되었지만 여전히 Bean에 미치지 못했다. 이는 ‘양’보다 ‘품질’과 ‘다양성’이 더 큰 영향을 미친다는 결론을 뒷받침한다. (2) 데이터 증강 효과: MUSDB(소규모) 학습 시 여섯 가지 변환(채널 교환, 시간 스트레칭, 피치 시프팅, 리믹싱, 필터링, 라우드니스 스케일)과 이들의 조합을 적용했다. 통계적 유의성을 검증하기 위해 paired t‑test를 수행했으며, 일부 변환(채널 교환, 피치 시프팅, 시간 스트레칭)이 평균 SDR을 0.20.3 dB 정도 향상시켰지만, 전체적으로 0.2 dB 이하의 미미한 개선에 그쳤다. 이는 스펙트로그램 기반 변환이 실제 오디오 신호의 비선형 특성을 충분히 반영하지 못함을 시사한다. (3) 다중 악기 소스 활용: MUSDB의 4‑stem(보컬, 드럼, 베이스, 기타) 정보를 모두 사용해 ‘instrumental’을 세 개 비보컬 스템의 합으로 예측하도록 실험했다. 결과는 보컬 SDR에 0.10.2 dB 정도의 소폭 향상을 보였으며, 특히 드럼 잔류가 감소해 SIR이 눈에 띄게 개선되었다. 이는 비보컬 스템을 별도로 학습시키면 악기 간 상관관계를 더 정밀히 모델링할 수 있음을 의미한다.
전반적으로 논문은 (i) 충분히 큰 고품질 데이터가 없으면 모델이 과적합하거나 잡음에 민감해진다, (ii) 데이터 다양성(장르·아티스트·템포·키 등)이 모델의 일반화 능력을 크게 좌우한다, (iii) 기존 MIR 분야에서 흔히 쓰이는 스펙트로그램 변환 기반 증강은 보컬·반주 분리와 같은 복합 소스 문제에선 한계가 있다, (iv) 다중 스템을 활용한 멀티태스크 학습이 약간의 성능 향상을 제공한다는 점을 실증했다. 이러한 결과는 앞으로 대규모 고품질 멀티트랙 데이터베이스 구축과, 증강 방법을 오디오 신호 수준(예: 고품질 파형 변환, 가상 보컬 합성)으로 확장할 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기