예기치 않은 의미의 계산적 구조
본 논문은 화자가 의도하지 않은 의미가 청자에게 어떻게 전달되는지를 베이지안 모델로 설명한다. 부분관찰 확률 게임(POSG)과 상호 신념 상태를 이용해 화자와 청자의 관점‑전이 과정을 정량화하고, 실험을 통해 ‘우연한 실수’와 ‘고의적 모욕’을 구분한다.
저자: Mark K. Ho, Joanna Korman, Thomas L. Griffiths
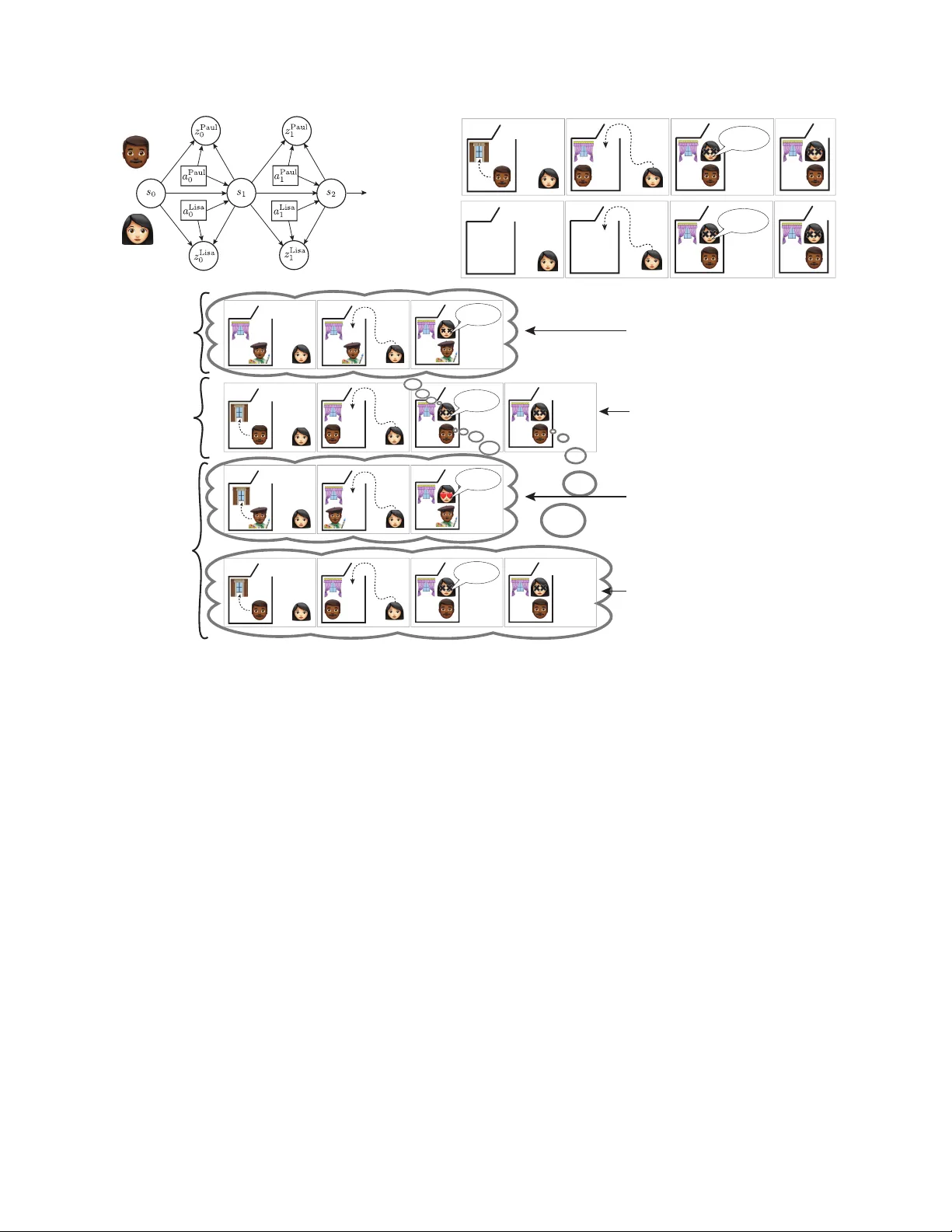
본 논문은 화자가 의도하지 않은 의미가 청자에게 어떻게 전달되는지를 베이지안 관점에서 체계적으로 분석한다. 서론에서는 일상 대화에서 발생할 수 있는 ‘우연한 실수’(faux pas)와 ‘고의적 모욕’ 사이의 미묘한 차이를 제시하고, 이러한 현상이 기존의 그라이스(Grice)·스피버‑윌슨(Sperber & Wilson) 모델로는 충분히 설명되지 않음을 지적한다. 저자들은 이를 해결하기 위해 두 단계의 모델을 제안한다. 첫 번째는 세계를 부분관찰 확률 게임(POSG)으로 형식화하는 세계 모델이며, 두 번째는 에이전트(화자·청자)의 상호 신념 상태를 베이즈 방식으로 업데이트하는 에이전트 모델이다.
세계 모델에서는 n명의 에이전트가 각각 개인적인 관찰 Zᵢ와 행동 Aᵢ(발화 포함)를 가지고, 상태 S는 변수 x₁…x_k 로 구성된다. 전이 함수 T(s, a) → p(s′, z) 가 행동과 관찰이 다음 상태와 공동 관찰을 어떻게 생성하는지를 확률적으로 정의한다. 예시인 ‘Curtains’ 시나리오에서는 초기 상태 s₀에 폴이 새 커튼을 고르고, 리사가 나중에 방에 들어와 “그 커튼은 끔찍해”라고 발화한다. 리사는 폴이 커튼을 고른 순간을 관찰하지 못했으며, 따라서 그녀의 관찰 히스토리는 폴의 선택과 무관하게 커튼의 미적 품질만을 포함한다.
에이전트 모델에서는 각 에이전트 i가 신념 bᵢ = p(· | ~zᵢᵗ) 로 표현된다. 이 신념은 1차, 2차, … k차 상호 신념을 포함하며, 예를 들어 폴은 “리사가 내 취향을 어떻게 생각하는가”라는 2차 신념 E b_Paul b_Lisa (Taste) 를 유지한다. 베이즈 정리와 히스토리 ~hₜ를 이용해 신념을 갱신하고, 이를 통해 에이전트는 다른 에이전트의 목표와 기대를 추론한다.
화자 모델은 두 종류의 변수 X_Info(정보적)와 X_Eval(평가적)를 구분한다. 화자는 청자가 X_Info와 X_Eval에 대해 어떤 신념 변화를 겪을지를 예측하고, 각각에 가중치 θ_L‑Info, θ_L‑Eval을 부여한 보상 R_S = θ_L‑Info·ΔL‑Info + θ_L‑Eval·ΔL‑Eval 를 최대화한다. θ_L‑Eval이 양수이면 화자는 청자의 평가를 긍정적으로 바꾸려 하고, 음수이면 청자를 깎아내리려는 의도를 나타낸다.
청자 모델은 문자 그대로의 의미와 화자의 의도 모델을 동시에 고려한다. 문자 그대로의 청자는 발화 a_S 의 진리값 함수 r(a_S, s) 에 따라 발화가 사실인지 여부를 판단하고, 작은 오류 확률 ε 를 허용한다. 의도적 청자는 화자의 보상 구조와 신념을 역추론해 ΔL‑Info와 ΔL‑Eval 를 추정한다. 이때 청자는 자신이 관찰하지 못한 사건(예: 화자가 커튼 선택을 목격했는지 여부)을 히스토리 차이를 통해 추정한다.
시뮬레이션에서는 동일한 발화가 두 가지 히스토리 상황에서 다르게 해석되는지를 확인한다. 공유 히스토리(화자와 청자가 모두 커튼 선택을 목격)에서는 화자는 청자가 자신의 평가를 알았다고 가정하고, θ_L‑Eval < 0 로 설정되어 있어 의도적 모욕으로 해석된다. 반면 분기 히스토리(화자가 선택 과정을 놓침)에서는 화자는 자신의 발화가 단순히 미적 평가에 불과하다고 믿으며, θ_L‑Eval ≈ 0 이므로 청자는 이를 ‘우연한 실수’로 받아들인다. 두 경우 모두 청자는 ΔL‑Eval < 0 (즉, 자신의 능력이 낮다고 인식) 를 학습하지만, 화자의 기대와 청자의 기대가 일치 여부가 차이를 만든다.
실험에서는 200명 이상의 참가자를 대상으로 공유 히스토리와 분기 히스토리 두 종류의 vignette 를 제시하고, (1) 발화가 의도적 모욕인지 우연한 실수인지, (2) 화자가 청자의 감정을 예측했는지 여부, (3) 청자가 화자의 의도를 어떻게 추론했는지를 물었다. 조작 검사를 통과한 참가자들의 응답은 모델이 예측한 바와 일치했으며, 특히 히스토리 차이에 대한 인식이 판단에 큰 영향을 미쳤다. 이는 인간이 고차원적인 관점‑전이와 베이즈식 신념 업데이트를 실제 대화에서 수행한다는 강력한 증거다.
논문의 기여는 다음과 같다. 첫째, 언어 의미 전달을 부분관찰 확률 게임과 베이즈 신념 네트워크로 정량화함으로써 기존의 의미론·화용론 모델을 확장했다. 둘째, 의도와 비의도를 구분하는 평가 변수 X_Eval 을 도입해 ‘불쾌감’이라는 정성적 개념을 수치화하고, 화자와 청자의 보상 구조를 명시적으로 모델링했다. 셋째, 인간 실험을 통해 모델의 예측력을 검증함으로써 인공지능 대화 시스템이 의도와 비의도를 구별하도록 설계될 수 있는 이론적 기반을 제공했다. 마지막으로, 이 접근은 사회적 인지·이론‑마인드 연구와 인간‑컴퓨터 상호작용(HCI) 분야에 적용 가능하며, 특히 AI 비서나 챗봇이 사용자의 감정을 오해하지 않도록 하는 설계에 직접적인 시사점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기