AssemblyNet 전체 뇌 MRI 분할을 위한 새로운 딥 의사결정 프로세스
초록
본 논문은 제한된 학습 데이터에도 불구하고 132개의 해부학적 라벨을 정확히 분할하는 것을 목표로, 250개의 U‑Net을 두 개의 “의회”처럼 구성한 AssemblyNet을 제안한다. 인접 U‑Net 간 가중치 전이, 비선형 Atlas 사전 지식, 2 mm→1 mm 다중 스케일 캐스케이드 및 다수결 투표를 결합해 기존 글로벌 U‑Net, SLANT‑27 및 JLF 대비 Dice 점수를 10~28% 향상시켰으며, 실용적인 학습·추론 시간을 유지한다.
상세 분석
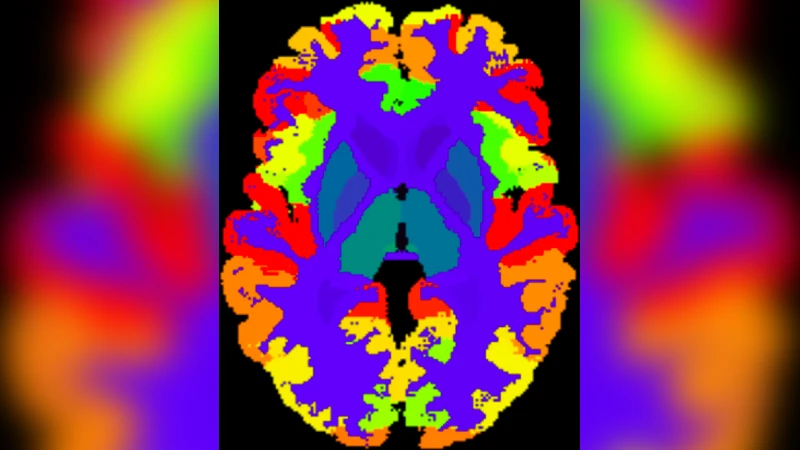
AssemblyNet은 전체 뇌 MRI 분할이라는 고차원 다라벨 문제를 해결하기 위해 ‘의회’ 메커니즘을 차용한 두 단계의 앙상블 구조를 설계하였다. 첫 번째 어셈블리는 2 × 2 × 2 mm 해상도의 125개 U‑Net으로 구성되어, 뇌 전체를 겹치는 서브볼륨으로 나누어 각 영역에 대한 초기(코스) 라벨링을 수행한다. 여기서 각 U‑Net은 공간적으로 가장 가까운 이웃 네트워크의 가중치를 초기값으로 복사하는 ‘최근접 이웃 전이 학습(Nearest‑Neighbor Transfer Learning)’을 적용한다. 이는 동일한 해부학적 패턴을 공유하는 인접 영역 간에 학습 효율을 높이고, 제한된 훈련 샘플(45개)에서도 일반화 성능을 강화한다.
두 번째 어셈블리는 1 × 1 × 1 mm 해상도의 또 다른 125개 U‑Net으로 구성되며, 첫 번째 어셈블리에서 얻은 코스 세그멘테이션을 최근접 이웃 보간법으로 업샘플한 뒤, 비선형 Atlas 사전(다중 라벨 Atlas를 비선형 정합)과 결합한다. 이 ‘수정(amendment)’ 단계는 코스 결과를 고해상도에서 재검토·정제하는 역할을 하며, 마치 입법 과정에서 상원·하원이 법안을 다듬는 과정과 유사하다. 최종 결과는 두 어셈블리의 모든 U‑Net이 제시한 라벨에 대해 다수결 투표를 수행함으로써 결정된다.
데이터 전처리는 표준화된 파이프라인(노이즈 제거, 편향 보정, MNI 정합, 강도 정규화, 뇌 추출)으로 이루어졌으며, Atlas 사전은 MICCAI 2012 Multi‑Atlas 라벨링 챌린지 데이터를 비선형 정합해 얻었다. 학습에는 100 epoch + 20 epoch 가중치 평균화, 드롭아웃 테스트 시 적용, MixUp 데이터 증강 등을 활용해 과적합을 억제하였다. 각 U‑Net은 24개의 필터(3×3×3)로 경량화했으며, 배치 크기 1, Adam 옵티마이저, Dice‑Loss를 사용하였다.
실험 결과, AssemblyNet은 동일한 45개의 훈련 이미지만을 사용했음에도 불구하고 전역 Dice 평균 73.3%를 달성했으며, 이는 기존 글로벌 U‑Net(57.0%), SLANT‑8(57.0%), SLANT‑27(66.1%) 대비 각각 28%, 28%, 10% 이상의 향상을 의미한다. 특히 2 mm 어셈블리만 사용했을 때도 67.9%의 Dice를 기록해, 다중 스케일 캐스케이드가 1.6%p의 추가 이득을 제공함을 확인했다. 훈련 시간은 약 7일, 추론 시간은 10분 수준으로, 대규모 라이브러리 확장 없이도 실용적인 워크플로우를 제공한다.
또한, 테스트 데이터셋을 OASIS(성인), CANDI(소아), Colin27(고해상도)로 구분해 평가했을 때, AssemblyNet은 모든 도메인에서 최고 성능을 유지했다. 특히 소아 데이터에서 기존 방법들이 크게 성능 저하를 보이는 반면, AssemblyNet은 71.1%의 Dice를 유지해 데이터 분포 변화에 대한 강인성을 입증했다. 이는 인접 U‑Net 간 지식 공유와 Atlas 사전 활용이 다양한 해부학적·촬영 조건에 대한 일반화 능력을 크게 향상시킨 결과로 해석된다.
전반적으로 AssemblyNet은 ‘의회형’ 딥 앙상블이라는 새로운 설계 패러다임을 제시함으로써, 제한된 라벨링 자원과 GPU 메모리 제약 속에서도 고정밀 전체 뇌 분할을 가능하게 한다. 향후 연구에서는 어셈블리 수와 서브볼륨 크기의 최적화, 더 다양한 사전 지식(예: 기능적 연결성) 통합, 그리고 클라우드 기반 대규모 데이터 확장에 대한 비용 효율성을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기