aNMM Attention 기반 신경 매칭 모델을 이용한 짧은 답변 텍스트 순위 매김
초록
본 논문은 질문‑답변 매칭을 위해 값‑공유 가중치와 질문‑주의(attention) 메커니즘을 결합한 aNMM 모델을 제안한다. QA 매칭 매트릭스를 단어 임베딩 코사인 유사도로 구성하고, 매칭 값의 구간별(빈) 가중치를 학습함으로써 위치‑공유 가중치가 아닌 값‑공유 가중치를 적용한다. 질문 단어별 중요도는 질문‑주의 네트워크를 통해 학습된다. TREC QA 데이터셋 실험에서 추가 특징 없이도 기존 CNN·LSTM 기반 모델을 크게 앞섰으며, 간단한 추가 특징(QL)과 결합했을 때는 모든 기존 베이스라인을 능가한다.
상세 분석
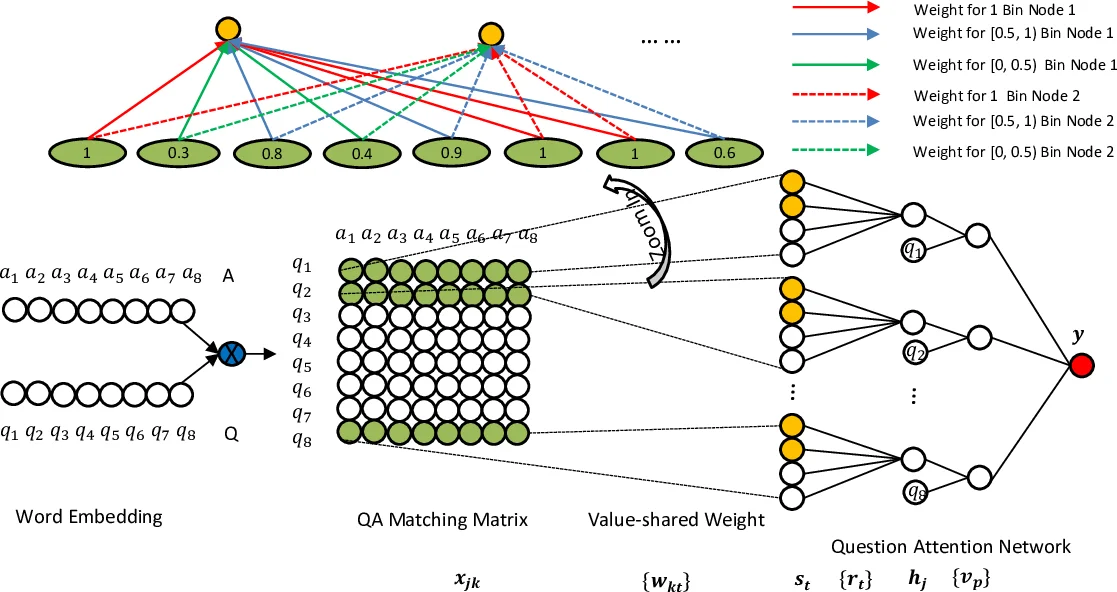
aNMM은 기존 딥러닝 기반 QA 매칭 모델이 갖는 두 가지 근본적인 한계를 해결한다. 첫째, CNN이 이미지 처리에 최적화된 위치‑공유(weight sharing) 방식을 그대로 차용하면, 질문‑답변 텍스트 간의 의미 매칭에서 중요한 신호가 위치에 무관하게 발생할 수 있다는 점을 간과한다. aNMM은 매칭 매트릭스의 각 원소 값을 구간(bin)으로 나누고, 구간별 가중치를 학습하는 값‑공유(weight sharing) 방식을 도입한다. 이는 “유사도 값이 높을수록(예: 0.9~1.0) 더 큰 가중치를 부여한다”는 직관을 모델이 스스로 학습하도록 만든다. 구간 수와 폭은 실험적으로 조정했으며, 본 논문에서는 0.1 간격의 21개 빈을 사용해 정밀한 신호 구분이 가능하도록 설계하였다.
둘째, 질문 내 핵심 용어에 대한 차별화된 중요도 부여가 부족했다는 점이다. 기존 LSTM 기반 모델은 순차적 처리에 의존해 마지막 단어에 가중치를 두는 경향이 있었고, CNN 기반 모델은 모든 질문 단어를 동일하게 취급했다. aNMM은 질문‑주의 네트워크를 별도 게이팅 층으로 두어, 각 질문 단어의 매칭 벡터와 전체 매칭 컨텍스트를 입력으로 중요도 스코어를 계산한다. 이 스코어는 최종 점수 계산 시 가중합에 사용되어, 질문 핵심어가 포함된 매칭 신호가 강조된다.
모델 구조는 크게 세 단계로 이루어진다. 1) 사전 학습된 Word2Vec 임베딩을 이용해 질문‑답변 쌍의 매칭 매트릭스를 구축한다. 2) 첫 번째 은닉층에서 값‑공유 가중치를 적용해 매트릭스의 각 행을 고정 길이 벡터로 변환하고, 이후 전통적인 완전 연결층을 쌓아 고차원 추상화를 수행한다. 3) 질문‑주의 네트워크가 각 질문 행에 가중치를 부여하고, 가중합을 통해 최종 관련도 점수를 산출한다. 두 가지 변형(aNMM‑1, aNMM‑2)이 제시되었으며, aNMM‑2는 다중 은닉층과 더 정교한 가중치 공유 방식을 포함한다.
실험에서는 TREC QA 트랙 813의 사실형 질문 데이터셋을 사용했으며, 평가 지표는 MAP, MRR, 그리고 정확도이다. aNMM은 추가 특징 없이도 기존 CNN(Luo et al., 2016)·LSTM(Wang & Nyberg, 2015) 모델보다 평균 57%p 높은 점수를 기록했다. 또한, 질의‑문서 언어 모델(QL) 점수를 단순히 선형 결합한 경우, aNMM+QL은 모든 기존 베이스라인을 압도하며, 특히 최신 신경망 기반 모델을 3~4%p 앞섰다.
이러한 결과는 값‑공유 가중치가 의미 매칭에서 “값 자체”에 초점을 맞추어 위치 불변성을 제공하고, 질문‑주의가 질문 핵심을 효과적으로 강조함으로써, 전통적인 특징 엔지니어링 없이도 강력한 성능을 달성할 수 있음을 입증한다. 또한, 모델이 비교적 단순하고 학습 비용이 낮으며, 외부 파싱 도구나 지식 베이스에 의존하지 않아 다양한 언어와 도메인에 쉽게 확장될 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기