음악 작곡 스타일 전이와 음색 분리
본 논문은 폴리포닉 오디오를 입력으로 받아 악보(피아노롤)와 악기 활동을 동시에 예측하는 인코더‑디코더 모델을 제안한다. 악보와 악기 정보를 각각 피치와 음색으로 분리하기 위해 두 가지 구조(DuoED, UnetED)를 설계하고, 적대적 학습을 활용해 피치와 음색의 잠재 표현을 얽힘 없이 학습한다. 학습된 음색 잠재코드를 다른 곡의 피치와 결합함으로써 “작곡 스타일 전이”, 즉 기존 멜로디는 유지하면서 악기 편성을 바꾸는 재배열을 수행한다. 실…
저자: Yun-Ning Hung, I-Tung Chiang, Yi-An Chen
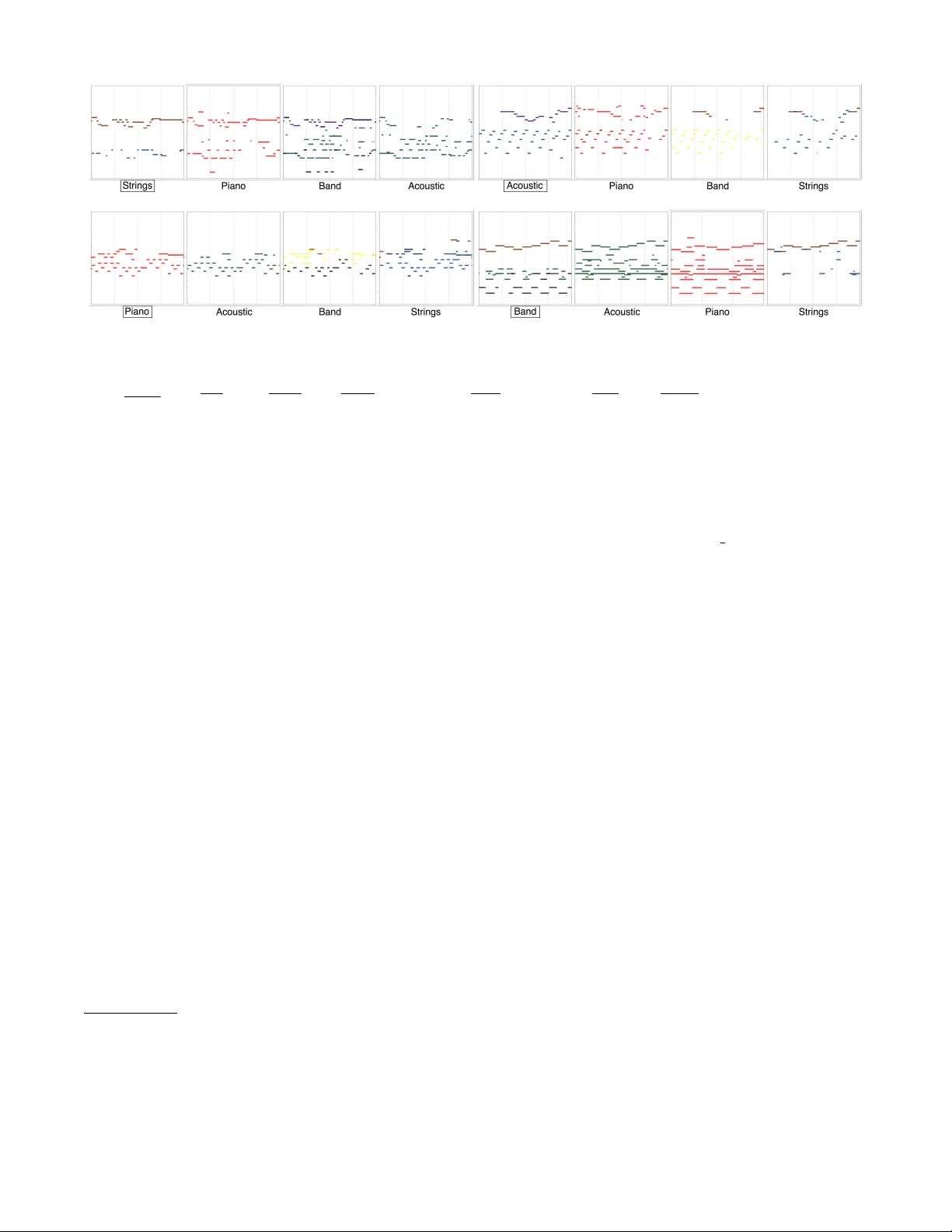
본 논문은 “음악 작곡 스타일 전이”라는 새로운 과제를 정의하고, 이를 실현하기 위한 두 가지 딥러닝 기반 인코더‑디코더 모델을 제안한다. 기존 연구가 멜로디·코드·리듬 등 음악의 내용적 요소 생성에 집중한 반면, 악기 편성이라는 ‘배치’ 요소는 거의 다루지 못했다. 저자들은 폴리포닉 오디오와 대응되는 MIDI 파일을 쌍으로 사용해, 오디오 → 악보(피아노롤) 변환 과정을 학습함으로써 피치와 음색을 동시에 추출한다.
### 1. 데이터 표현
오디오 입력은 16 kHz 샘플링, 512‑샘플 윈도우, 0 오버랩으로 CQT 변환해 88 개의 주파수 bin(12 bin/옥타브)으로 구성된 X_cqt∈ℝ^{88×312} 매트릭스로 만든다. 목표 출력은 멀티트랙 피아노롤 X_roll∈{0,1}^{88×312×M} 로, 여기서 M은 데이터셋에 포함된 악기 종류 수이다. 피아노롤을 축소해 악기 롤 X_t∈{0,1}^{M×312} 와 피치 롤 X_p∈{0,1}^{88×312} 를 얻어, 피치와 음색을 각각 별도 supervision으로 활용한다.
### 2. 모델 설계
#### DuoED (Dual Encoder‑Decoder)
- 두 개의 독립 인코더 E_t, E_p 를 사용해 X_cqt → Z_t(음색) 와 Z_p(피치) 로 변환한다.
- Z_t, Z_p 는 각각 κ×τ 차원의 행렬이며, τ는 시간 차원이다.
- 디코더 D_roll 은 Z_t와 Z_p 를 concat해 피아노롤을 복원하고, D_t와 D_p 는 각각 Z_t, Z_p 로부터 악기 롤·피치 롤을 예측한다.
- 기본 손실은 바이너리 교차 엔트로피(L_roll, L_t, L_p)이며, 적대적 손실 L_nt, L_np 를 도입해 “잘못된” 잠재코드(예: Z_t를 D_p에 입력)로부터의 출력이 0에 가깝게 만들도록 인코더를 훈련한다. 이를 통해 Z_t와 Z_p 사이의 얽힘을 최소화한다.
#### UnetED (U‑Net Encoder‑Decoder)
- 하나의 인코더 E_cqt 로 단일 잠재 Z_t 를 만든다.
- U‑Net 형태의 skip connection을 통해 저층 피처를 디코더 D_roll 로 직접 전달한다. 이 구조는 피치 정보를 skip을 통해 그대로 전달하고, Z_t 에는 순수히 음색 정보만 남게 한다.
- D_t 는 Z_t 로부터 악기 롤을 예측하고, D_p 는 Z_t 로부터 피치를 추출하려 할 때 높은 손실을 부여해 인코더가 피치를 숨기도록 만든다(GAN‑like 적대적 학습).
- 전체 손실은 L_roll + L_t + (적대적 L_np) 로 구성된다.
두 모델 모두 완전 컨볼루셔널 설계라 입력 길이에 제한이 없으며, 학습 시 10 초 청크(312 프레임) 단위로 배치를 만든다.
### 3. 작곡 스타일 전이 방법
전이 과정은 다음과 같다.
1. 소스 오디오 A 를 인코더에 넣어 피치 코드 Z_p(A) (또는 skip) 를 얻는다.
2. 타깃 오디오 B 를 인코더에 넣어 음색 코드 Z_t(B) 를 얻는다.
3. Z_t(B) 와 Z_p(A) (또는 skip) 를 D_roll 에 입력해 새로운 피아노롤 X_{A→B}^{roll} 을 생성한다.
4. 생성된 피아노롤을 MIDI 로 변환하고, 신디사이저(예: FluidSynth)로 오디오를 합성한다. 이렇게 하면 A의 멜로디·하모니는 유지하면서 B의 악기 편성으로 재배열된 결과가 나온다.
### 4. 실험 및 평가
- **데이터**: MusicNet, MAESTRO 등 공개된 오디오‑MIDI 쌍을 사용해 훈련·검증.
- **악기 활동 검출**: F1 점수 80 % 이상, 특히 UnetED가 skip 덕분에 피치 보존이 뛰어남을 확인.
- **스타일 전이 청취 테스트**: 인간 청취자를 대상으로 원본 멜로디 인식 여부와 악기 편성 변화에 대한 만족도를 평가. 참가자들은 대부분 원본 멜로디를 정확히 인식하면서도 새로운 악기 편성을 긍정적으로 평가했다.
- **정성적 분석**: 전이된 오디오가 원본과 비교해 음색이 명확히 변했으며, 불필요한 피치 변형은 거의 없었다.
### 5. 기여 및 한계
- **기여**: (1) 폴리포닉 음악에 대한 최초의 딥러닝 기반 재배열 모델 제시, (2) 피치‑음색 분리를 위한 두 가지 구조와 적대적 학습 설계, (3) 공개 코드와 데이터 전처리 파이프라인 제공.
- **한계**: 현재 모델은 제한된 악기 종류와 고정된 피치 범위에 의존한다. 악기 간 상호작용(예: 합주 효과)이나 다이내믹한 표현(베이스 라인, 스트링 섹션의 레이어링)을 완전히 포착하지 못한다. 또한 최종 오디오 품질은 사용된 신디사이저에 크게 좌우된다.
### 6. 향후 연구 방향
- 더 많은 악기 라벨과 고해상도 오디오 데이터 확보, 멀티모달(오디오·MIDI·악보) 학습으로 음색‑피치 얽힘을 더욱 정교하게 분리, 직접 오디오 도메인에서의 음색 변환(예: WaveNet 기반) 연구, 그리고 실시간 스타일 전이 시스템 구축을 목표로 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기