상태변화 메모리 기반 스파이킹 신경망의 고성능 감독 학습
초록
본 논문은 비휘발성 상변화 메모리(PCM) 소자를 이용해 스파이킹 신경망(SNN)을 직접 학습시키는 방법을 제시한다. 177 k개 이상의 PCM 디바이스를 8개씩 묶어 차동형 시냅스로 구성하고, NormAD 알고리즘으로 정확한 스파이크 타이밍을 학습한다. 실험 결과, 다중 PCM 구성을 통해 92 % 수준의 정확도를 달성했으며, 장치 비선형·확률성·드리프트를 고려한 모델링과 시스템 수준 보정 기법을 제시한다.
상세 분석
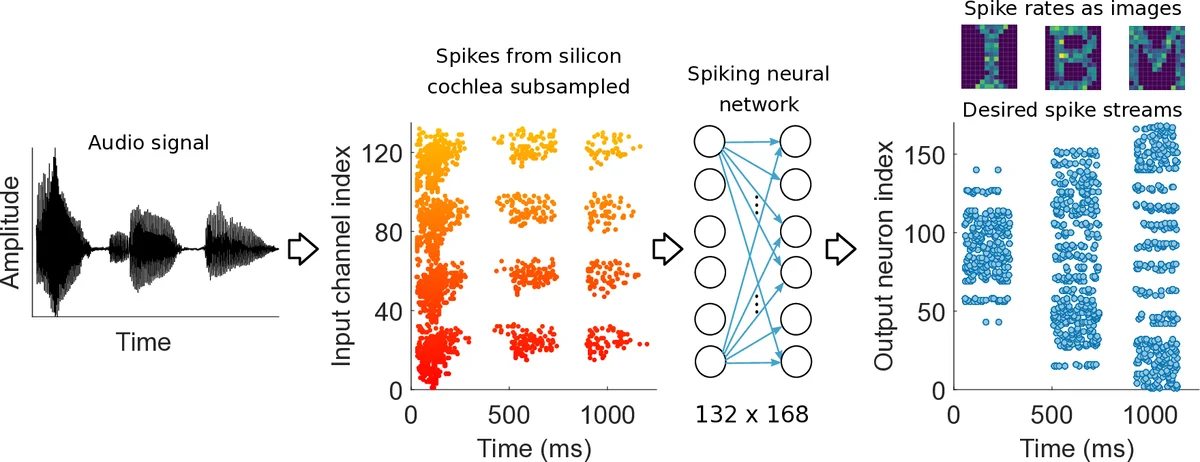
이 연구는 기존의 ANN‑to‑SNN 변환 방식이 갖는 시간‑레이트 손실과 고정밀 디지털 가중치 저장의 비효율성을 극복하고자, 비휘발성 상변화 메모리(PCM) 기반의 계산 메모리 아키텍처를 직접 SNN 학습에 적용하였다. PCM은 결정(SET)과 비정질(RESET) 상태 사이의 저항 변화를 이용해 연속적인 전도도 조절이 가능하지만, 비선형성, 스토캐스틱 변동, 드리프트 등 비이상적 특성을 가진다. 이를 보완하기 위해 저자들은 각 시냅스 가중치를 두 개의 PCM 소자(G⁺, G⁻) 차동 구조로 구현하고, 각 전도도 값을 4개의 디바이스를 병렬로 합산하는 다중‑PCM 구성을 도입하였다. 이렇게 하면 하나의 프로그래밍 펄스가 전체 가중치 변화에 미치는 영향을 평균화해 정밀도와 대칭성을 향상시킬 수 있다.
학습 알고리즘으로는 NormAD(Normalized Approximate Descent)를 선택했는데, 이는 스파이크 타이밍 차이에 기반한 이벤트‑드리븐 가중치 업데이트를 제공한다. 구체적으로, 원하는 출력 스파이크와 실제 스파이크 사이의 차이 e(t)를 입력 스파이크와 LIF 뉴런의 근사 임펄스 응답을 컨볼루션한 ˆd(t)와 곱해 학습률 η와 패턴 지속시간 T에 따라 ΔW를 계산한다. 이 ΔW는 차동 PCM 가중치에 매핑되어 50 ns, 40‑130 µA 범위의 프로그래밍 전류 펄스로 변환된다. 중요한 점은 ‘블라인드 프로그래밍’ 방식을 채택해, 업데이트 후 실제 전도도 변화를 읽어 검증하지 않음으로써 읽기‑검증 오버헤드를 제거하고, 향후 대규모 계산 메모리 시스템에 적합한 설계 철학을 제시했다.
실험은 실리콘 코클레(chip)에서 추출한 알파벳 음성 스파이크 스트림을 입력으로, 14×12 픽셀 이미지(‘I’, ‘B’, ‘M’)를 출력 스파이크 시퀀스로 변환하는 단일 레이어 SNN을 구축했다. 입력은 132개의 주파수 채널, 평균 10 Hz 스파이크 레이트이며, 출력은 168개의 뉴런이 각 픽셀 강도를 시간‑스파이크로 인코딩한다. 전체 네트워크는 22 176개의 시냅스로 구성되고, 각 시냅스는 8개의 PCM 디바이스(총 177 408개)로 구현되었다.
학습 결과는 다중‑PCM 구성을 늘릴수록 정확도가 상승함을 보여준다. 1개 디바이스당 시냅스에서는 약 70 % 수준이었으나, 4개 디바이스를 병합한 경우 92.5 %에 근접한 정확도를 달성했다. 또한, 입력 스파이크에 랜덤 지터를 추가하면 학습 수렴 속도가 향상되고, 시간에 따른 전도도 드리프트를 보상하기 위한 배열‑레벨 보정(예: 주기적 재보정 펄스) 기법이 정확도 저하를 억제한다는 점을 모델링을 통해 검증하였다.
이 논문은 PCM 기반 계산 메모리가 SNN의 이벤트‑드리븐 특성과 자연스럽게 결합될 수 있음을 실증적으로 증명한다. 차동·다중‑PCM 설계, 블라인드 프로그래밍, 그리고 스파이크 타이밍 기반 감독 학습 알고리즘의 조합은 메모리‑컴퓨팅 패러다임에서 에너지 효율과 병렬성을 동시에 확보할 수 있는 길을 제시한다. 향후 연구에서는 더 큰 네트워크 규모, 다중‑클래스 복합 인코딩, 그리고 온‑칩 뉴런 회로와의 통합을 통해 실제 임베디드 AI 시스템으로의 전이 가능성을 탐색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기