인간 음성 감정 인식: 전통 특징과 딥러닝 융합 접근법
초록
본 논문은 MFCC·STFT와 같은 전통적인 음성 특징 추출에 CNN·LSTM 등 딥러닝 모델을 결합하고, 텍스트 컨텍스트를 활용해 8가지 감정(중립, 차분, 행복, 슬픔, 분노, 공포, 혐오, 놀람)을 분류한다. RA‑VDESS와 TESS 데이터셋을 이용해 하이퍼파라미터 탐색과 데이터 증강을 수행했으며, 최종 CNN 모델이 85% Top‑1 정확도를 달성했다. 실시간 적용 가능성을 검토했지만, 데이터 변동성 부족과 과적합 문제가 남아 있다.
상세 분석
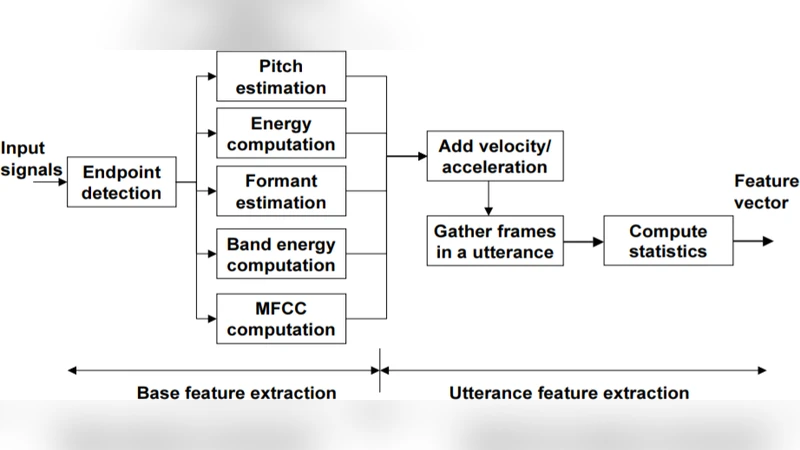
이 연구는 음성 감정 인식 분야에서 전통적인 신호 처리 기법과 최신 딥러닝 아키텍처를 동시에 탐색한다는 점에서 의미가 크다. 먼저 MFCC와 STFT 같은 스펙트럼 기반 특징을 추출하고, 이를 13×26 형태의 2차원 맵으로 변환해 CNN에 입력한다. 논문은 13개의 MFCC가 충분히 정보를 담는다고 주장하지만, 실험 결과에서는 MFCC 수가 20을 넘어가면 정확도가 크게 향상되지 않고 50 이상에서는 오히려 변동성을 보였다. 이는 MFCC가 고차원 주파수 정보를 압축하면서 손실이 발생함을 시사한다.
SVM 기반 베이스라인은 RBF와 Linear 커널을 각각 C=10, γ=scale으로 설정했으며, 최적화된 경우에도 48% 수준에 머물렀다. 이는 전통적인 기계학습 모델이 감정 구분에 한계가 있음을 보여준다. 반면, 2‑D CNN은 AlexNet 스타일의 구조(두 개의 Conv‑Block + Fully‑Connected)로 85% Top‑1 정확도를 기록했으며, 1‑D Conv도 비슷한 성능을 보였다. 이는 MFCC가 시간‑주파수 2차원 배열로 표현될 때, 공간적 상관관계를 학습하는 CNN이 효과적임을 확인한다.
데이터 증강 측면에서는 음성 반전(polarity flip)과 역전된 오디오를 추가했지만, 정확도 향상이 미미했다. MFCC가 이미 평균화된 스펙트럼을 제공하기 때문에, 이미지 증강에서 흔히 보는 변형이 음성 데이터에 동일한 효과를 주지 못한다는 점을 강조한다. 또한, 데이터 표준화 방식을 샘플별로 수행했는데, 이는 클래스 간 변동성을 감소시켜 모델이 미세한 감정 차이를 학습하기 어렵게 만든다.
실시간 적용 가능성에 대한 논의는 제한적이다. 모델은 500 epoch 학습 후 85% 정확도를 보였지만, 추론 속도와 메모리 요구량에 대한 정량적 분석이 부족하다. 실제 음성 비서 시스템에 적용하려면 모델 경량화(예: MobileNet, pruning)와 스트리밍 MFCC 추출 파이프라인 최적화가 필요하다.
마지막으로, 논문은 향후 bidirectional LSTM, attention 기반 임베딩, 멀티모달(영상‑음성) 교차 증류 등을 제안한다. 이러한 방향은 현재의 MFCC‑CNN 한계를 보완하고, 감정 표현의 장기 의존성 및 컨텍스트 정보를 더 잘 포착할 수 있을 것으로 기대된다. 전체적으로 연구는 전통적인 음성 특징과 딥러닝을 결합한 실험적 비교를 제공하지만, 데이터 다양성 확보, 과적합 방지, 실시간 성능 평가 등 실용적 측면에서 보완이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기