음성 기반 시각 말합성, ASR 모델 전이 학습으로 품질 향상
초록
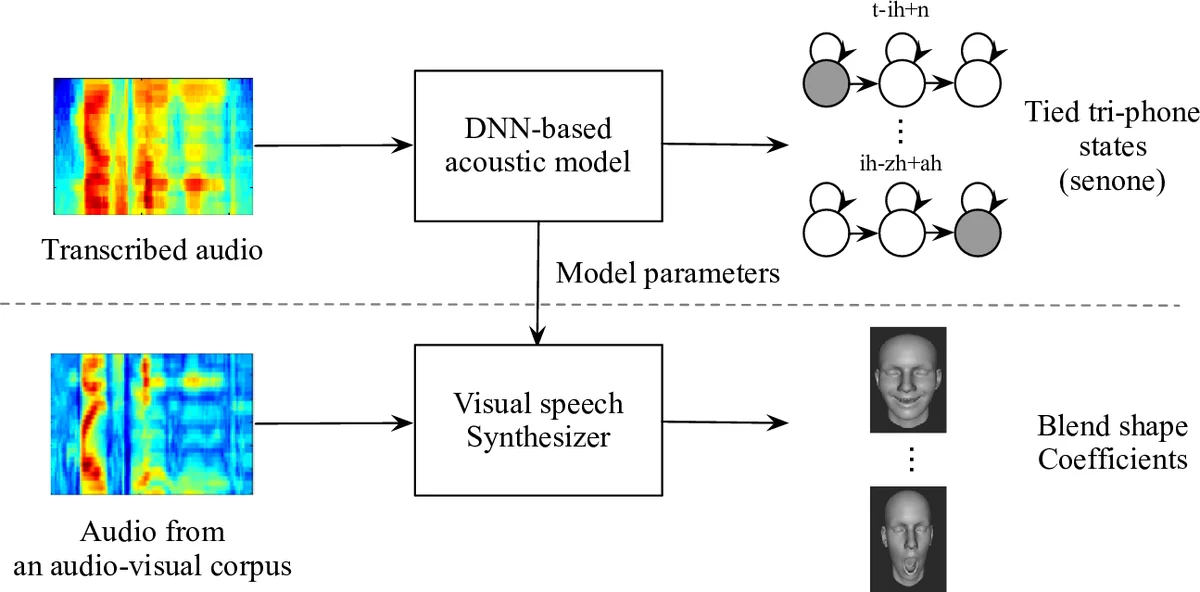
본 논문은 대규모 음성 전용 데이터로 사전 학습된 자동음성인식(ASR) 음향 모델을 시각 말합성에 전이시켜, 90시간의 동기화된 오디오‑비디오 데이터만으로도 화자 독립적인 입술 애니메이션을 구현한다. 사전 학습 모델을 초기화로 사용한 DNN이 무작위 초기화 모델보다 주관적 평가에서 현저히 선호되는 결과를 보이며, 음향 모델의 풍부한 표현력이 시각 말합성에 큰 이점을 제공함을 입증한다.
상세 분석
이 연구는 두 단계의 학습 파이프라인을 제안한다. 첫 번째 단계에서는 10,000시간 규모의 텍스트 라벨이 있는 음성 데이터만을 이용해 Kaldi 기반의 DNN/HMM 하이브리드 음향 모델을 구축한다. 모델은 13차원 MFCC와 1차·2차 미분, 이후 LDA와 fMLLR 변환을 거친 40차원 LMFB 특징을 사용하며, 5개의 1024‑노드 전결합 층과 512‑차원 병목층, 8,419개의 senone을 출력하는 소프트맥스 층으로 구성된다. 교차 엔트로피와 sMBR 손실을 모두 실험했으며, sMBR이 약간 높은 프레임 정확도를 제공한다. 두 번째 단계에서는 동일한 네트워크 구조를 유지하되, 소프트맥스 층을 32차원 선형 회귀 층으로 교체하고, 사전 학습된 가중치를 고정한 채 90시간의 동기화된 오디오‑비디오·깊이 데이터에 대해 미세조정한다. 회귀 층은 음향 특징을 얼굴 블렌드쉐입 계수(BSC)로 직접 매핑한다. BSC는 51개의 블렌드쉐입을 기반으로 하며, 자동 라벨링 파이프라인을 통해 RGB‑D 영상에서 추출된다. 이 파이프라인은 2D 랜드마크 CNN 검출, ICP 기반 깊이 정합, 그리고 L1 정규화를 포함한 가우스‑시델 방식 최적화를 사용한다. 실험에서는 60 fps와 100 fps 특징을 비교했으며, 60 fps가 더 넓은 컨텍스트를 제공해 정확도가 높았다. 객관적 MAE는 두 초기화 방식 간 차이가 미미했지만, 주관적 평가에서는 사전 학습된 AM으로 초기화한 모델이 시각적 자연스러움에서 유의하게 우위에 있었다. 이는 음성 신호에 내재된 억양·강세 정보가 입술 움직임을 정교히 예측하는 데 기여함을 시사한다. 한계점으로는 비음성 얼굴 움직임(예: 미소) 예측이 약하고, 데이터 규모가 여전히 제한적이라는 점을 들 수 있다. 향후 연구에서는 멀티모달 사전 학습, 변분 오토인코더 기반 생성 모델, 그리고 실시간 스트리밍 적용을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기