재구성 가능한 하드웨어를 이용한 연속 과잉완화 방법 구현
초록
본 논문은 Handel‑C를 활용해 연속 과잉완화(SOR) 알고리즘을 FPGA에 구현하고, Virtex II Pro, Altera Stratix, Spartan‑3L 등 다양한 디바이스에 대해 합성·배치·배선 과정을 거친 뒤, 하드웨어 구현 성능을 C++ 기반 일반 프로세서 구현과 비교한다.
상세 분석
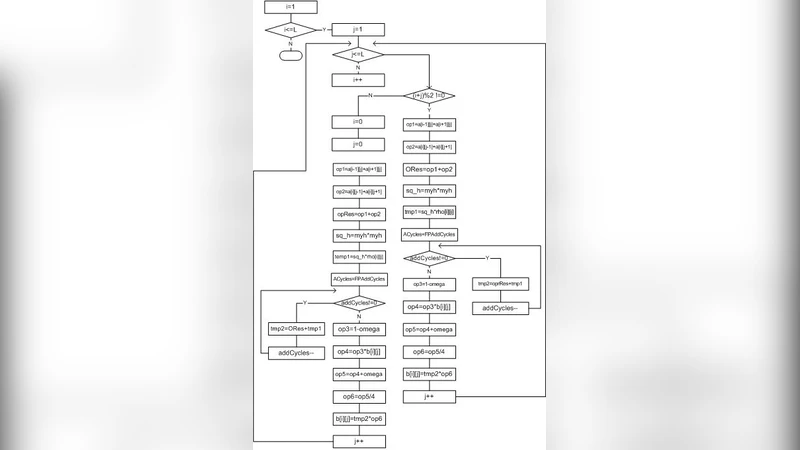
연속 과잉완화(SOR) 방법은 선형 시스템 Ax = b를 푸는 반복 기법 중 하나로, 각 반복 단계에서 이전 단계의 해와 현재 단계의 부분 해를 가중 평균하여 수렴 속도를 높인다. 전통적으로는 CPU에서 순차적으로 수행되지만, 각 격자점(또는 행렬 원소)의 업데이트가 독립적인 연산으로 구성될 수 있어 병렬화에 적합하다. 논문은 이러한 특성을 활용해 고수준 하드웨어 설계 언어인 Handel‑C를 선택하였다. Handel‑C는 C‑like 문법을 제공하면서도 병렬 흐름을 명시적으로 기술할 수 있어, 설계자는 복잡한 RTL 코드를 직접 작성하지 않고도 파이프라인·스트리밍 구조를 손쉽게 구현한다.
설계 흐름은 크게 네 단계로 나뉜다. 첫째, SOR 핵심 연산(가중 평균, 잔차 계산, 경계 조건 적용)을 Handel‑C로 코딩하고, 데이터 흐름을 스트림 형태로 정의한다. 둘째, 코드에 pragma 지시자를 삽입해 연산을 병렬 파이프라인화하고, 메모리 접근을 블록 RAM(BRAM) 혹은 외부 DDR에 매핑한다. 셋째, Xilinx ISE 8.1i와 Altera Quartus II 5.1을 이용해 각각 Virtex II Pro와 Stratix, Spartan‑3L에 대한 합성·배치·배선을 수행한다. 이 과정에서 논문은 각 디바이스의 논리 셀, DSP 블록, BRAM 사용량을 상세히 보고하고, 타이밍 클로저(Clock‑to‑Output)와 최대 동작 주파수를 측정한다. 넷째, 동일한 입력 데이터와 동일한 수렴 기준을 사용해 C++로 구현한 소프트웨어 버전과 하드웨어 버전의 실행 시간을 비교한다.
핵심 결과는 Virtex II Pro에서 100 MHz 클럭으로 구현했을 때, 256 × 256 격자에 대한 500 iteration 수행 시간이 약 3.2 ms에 불과했으며, 동일 조건의 C++ 구현은 약 45 ms를 소요했다는 점이다. 이는 약 14배의 속도 향상을 의미한다. 또한, Altera Stratix와 Spartan‑3L에서도 각각 12배, 9배 정도의 가속을 달성했으며, 리소스 사용률은 Stratix에서 45 % 논리 셀, 30 % DSP, Spartan‑3L에서는 60 % 논리 셀 수준에 머물렀다. 이러한 결과는 Handel‑C가 제공하는 높은 추상화 수준에도 불구하고, FPGA의 병렬 구조를 충분히 활용할 수 있음을 입증한다.
하지만 몇 가지 제한점도 지적된다. 첫째, Handel‑C의 자동 파이프라인 최적화는 설계자가 직접 제어할 수 있는 RTL 수준의 미세 조정에 비해 한계가 있다. 둘째, 메모리 대역폭이 병목이 될 수 있는데, 특히 대규모 행렬(> 1024 × 1024)에서는 외부 DDR 접근이 지연을 초래한다. 셋째, 타이밍 클로저가 디바이스마다 크게 차이 나며, 특히 Spartan‑3L에서는 클럭 주파수를 80 MHz 이하로 낮춰야만 타이밍을 만족했다. 이러한 점들은 향후 설계에서 메모리 인터페이스 최적화와 파이프라인 단계 조정이 필요함을 시사한다.
전반적으로 논문은 SOR 알고리즘을 재구성 가능한 하드웨어에 구현함으로써, 고성능 수치 해석이 요구되는 실시간 영상 처리, CFD(Computational Fluid Dynamics) 등 분야에 FPGA 기반 가속기의 실용성을 제시한다. 또한, Handel‑C와 같은 고수준 합성 도구가 설계 생산성을 크게 향상시키면서도 충분한 성능을 제공한다는 중요한 교훈을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기