시간 영역 완전합성 ConvTasNet 이상적인 시간주파수 마스크 초월
** ConvTasNet은 시간 영역에서 직접 작동하는 완전합성 신경망으로, 선형 인코더‑디코더와 깊은 1‑D 팽창 합성곱 블록(Temporal Convolutional Network, TCN)으로 구성된다. 마스크 추정을 전적으로 합성곱으로 대체해 파라미터 수와 연산량을 크게 줄였으며, 두 화자·세 화자 혼합에서 기존 시간‑주파수 기반 방법과 이상적인 마스크(IBM, IRM, WFM)를 모두 능가한다. 또한 비인과 인(실시간) 모두에서 작…
저자: Yi Luo, Nima Mesgarani
**
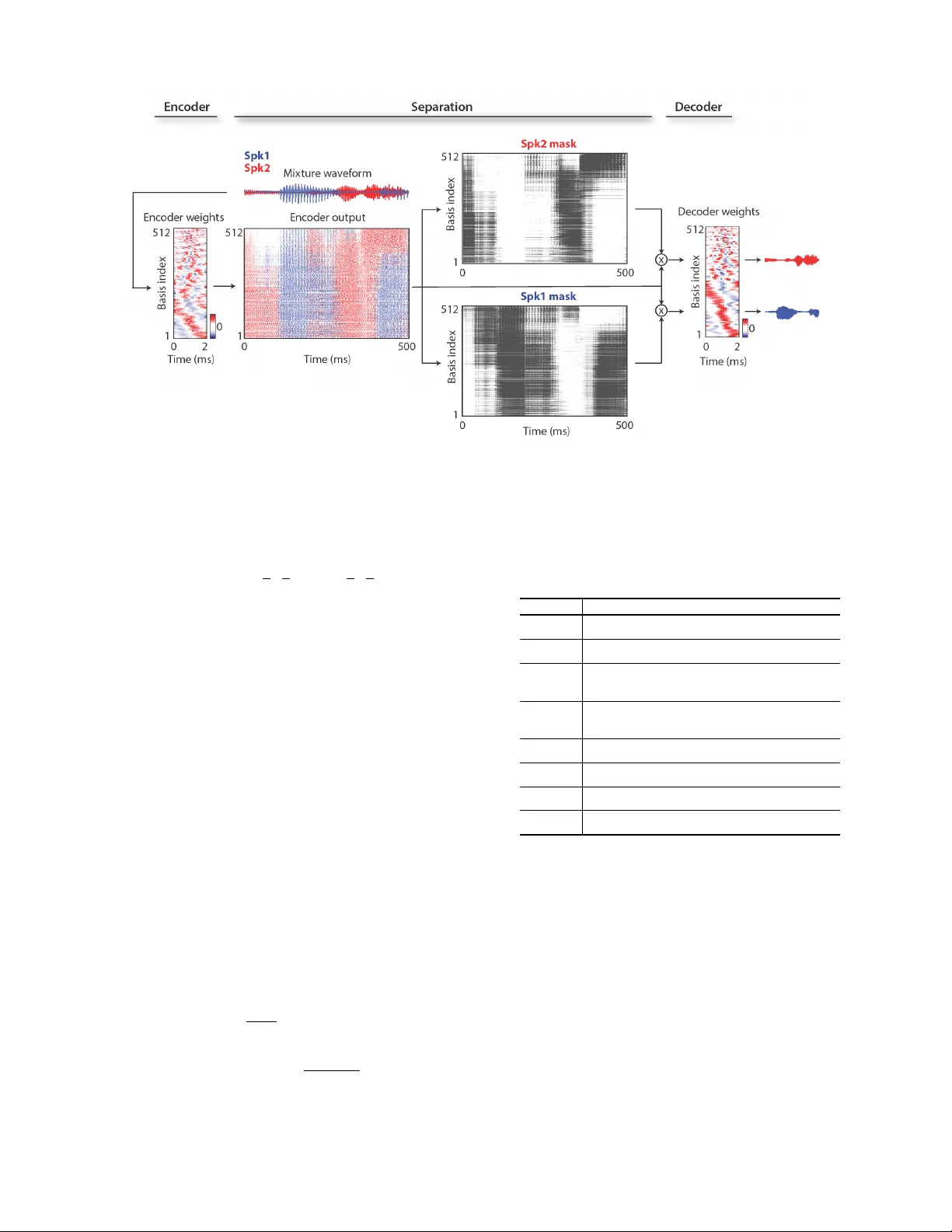
본 논문은 단일 채널, 화자 독립적인 스피치 분리 문제에 대해 기존 시간‑주파수(TF) 기반 접근법이 갖는 구조적 한계를 분석하고, 이를 극복하기 위한 완전합성(time‑domain) 신경망인 Conv‑TasNet을 제안한다. 기존 TF 기반 방법은 STFT를 통해 스펙트로그램을 만든 뒤 마스크를 추정하거나 직접 스펙트럼을 회귀하는 방식으로 동작한다. 그러나 STFT는 일반적인 신호 변환으로, 스피치 분리에 최적화되지 않았으며, 위상 정보를 정확히 복원하기 어려워 이상적인 마스크조차도 복원 품질에 한계를 만든다. 또한 고해상도 주파수 분석을 위해 긴 윈도우를 사용해야 하므로 최소 지연이 수십 밀리초에 달해 실시간 응용에 부적합하다.
이에 저자들은 파형을 직접 처리하는 구조를 설계하였다. 먼저, 1‑D 선형 인코더가 입력 파형을 겹치는 짧은 세그먼트(L) 단위로 나누어 N개의 필터(encoder basis)와 컨볼루션 연산을 수행해 고차원 특징 w∈ℝ^{N} 로 변환한다. 이 단계는 전통적인 STFT와 달리 학습 가능한 필터를 통해 스피치 분리에 최적화된 표현을 자동으로 찾는다. 인코더 출력 w에 대해 각 화자별 마스크 m_i∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기