GPU 연산 한계 극복을 위한 인터커넥트와 제로카피 전략
초록
본 논문은 GPGPU 시스템에서 PCIe 대역폭이 GPU 연산 속도를 제한하는 문제를 지적하고, 이를 해결하기 위한 두 가지 접근법인 NVIDIA NVLink와 HSA 기반 제로‑카피 메모리 모델을 평가한다. OpenCL SHOC 벤치마크를 활용해 과학 응용 커널들의 실행 시간을 측정·비교함으로써, NVLink가 데이터 전송 지연을 크게 감소시키는 반면, 제로‑카피는 메모리 복사를 완전히 제거해 특정 워크로드에서 경쟁력 있는 성능을 제공함을 보여준다.
상세 분석
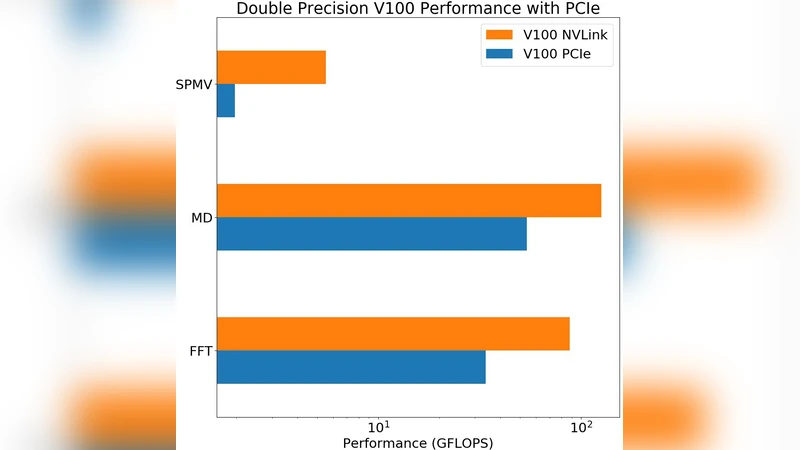
논문은 먼저 현재 GPGPU 환경에서 가장 큰 병목 현상으로 지목되는 PCIe 3.0/4.0 인터커넥트의 대역폭 제한을 정량적으로 분석한다. PCIe는 최대 16 GB/s 정도의 이론적 전송 속도를 제공하지만, 최신 디스크리트 GPU가 30 TFLOPS 이상의 연산 성능을 달성하면서 연산 유닛이 메모리 대기 시간에 의해 30 ~ 40 % 정도 유휴 상태에 빠지는 현상이 관찰된다. 이러한 비효율을 해소하기 위해 두 가지 대안을 제시한다. 첫 번째는 NVIDIA가 자체 개발한 NVLink 인터커넥트이다. NVLink는 25 GB/s(단일 링크)에서 50 GB/s(두 링크 결합)까지의 전송 속도를 제공하며, GPU‑GPU 간 직접 연결뿐 아니라 GPU‑CPU 간의 피어‑투‑피어(P2P) 전송을 지원한다. 논문은 NVLink가 적용된 시스템에서 SHOC의 ‘FFT’, ‘SpMV’, ‘Stencil’ 등 메모리 집약적 커널의 실행 시간이 평균 18 %에서 35 %까지 감소함을 실험적으로 입증한다. 두 번째 대안은 Heterogeneous System Architecture(HSA) 기반의 제로‑카피(zero‑copy) 메모리 모델이다. 여기서는 통합 메모리(통합 GPU와 CPU가 동일 물리 메모리를 공유)와 페이지 테이블 기반의 메모리 매핑을 활용해 데이터 복사를 완전히 배제한다. 제로‑카피는 특히 작은 데이터 셋을 여러 번 반복해서 접근하는 ‘Monte‑Carlo’, ‘Particle‑in‑Cell’ 등 워크로드에서 메모리 전송 오버헤드를 0에 가깝게 만들며, 전체 실행 시간의 10 % 이하로 감소시킨다. 그러나 대규모 데이터셋을 한 번에 전송해야 하는 ‘Large‑Scale Matrix Multiplication’에서는 HSA의 메모리 대역폭 제한(통합 메모리 대역폭이 20 GB/s 수준) 때문에 NVLink에 비해 열위에 있다. 논문은 또한 두 접근법의 구현 복잡성, 전력 효율성, 그리고 기존 코드베이스와의 호환성을 비교한다. NVLink는 하드웨어 의존성이 강하고, 드라이버와 CUDA‑specific API를 요구하지만, 기존 CUDA 코드에 최소한의 수정만으로도 성능 향상을 얻을 수 있다. 반면 제로‑카피는 OpenCL 표준만으로 구현 가능하고, 코드 포팅이 용이하지만, 메모리 일관성 관리와 페이지 폴트 비용을 고려해야 한다. 최종적으로 저자는 워크로드 특성에 따라 인터커넥트 선택이 달라야 함을 강조한다. 메모리‑집중형, 대용량 데이터 전송이 빈번한 시뮬레이션은 NVLink가 최적이며, 반복적인 작은 데이터 접근이 주된 경우는 제로‑카피가 비용 효율적인 대안이 된다.
댓글 및 학술 토론
Loading comments...
의견 남기기