라우팅 게임에서 미지 네트워크 상태 학습과 수렴 분석
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
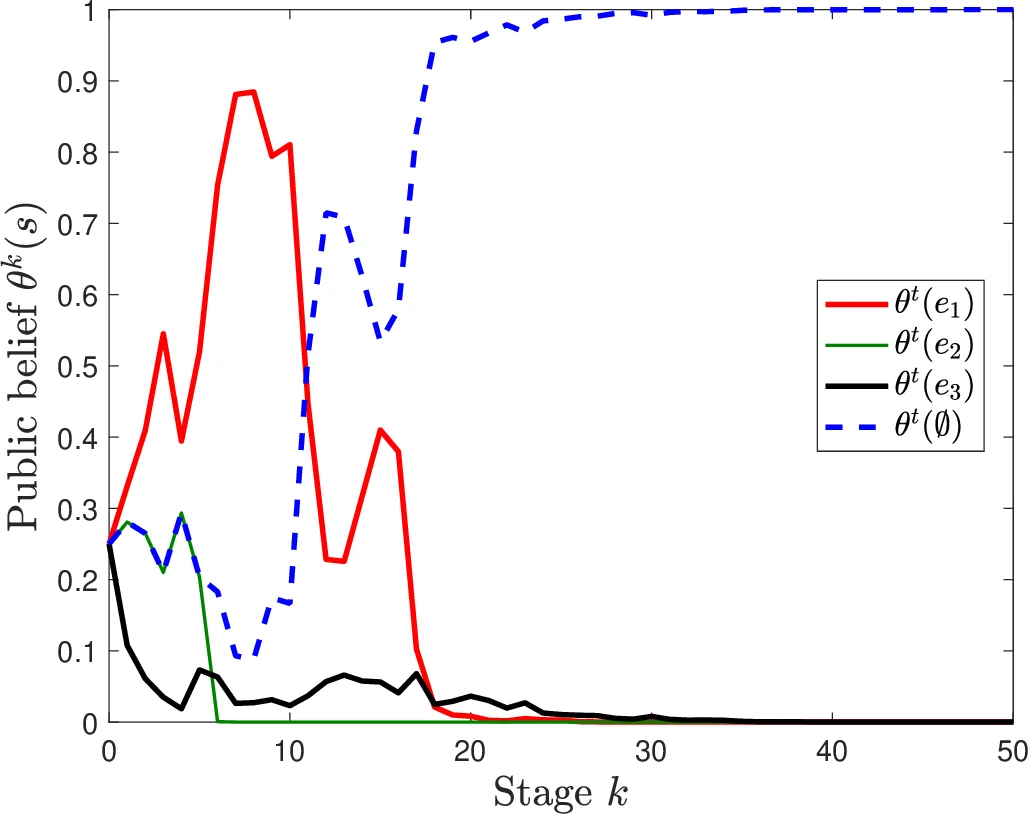
본 논문은 교통 네트워크의 불확실한 상태를 추정하기 위해, 여행자들이 매 단계마다 Wardrop 균형을 따르고, 공공 정보 시스템이 관측된 이용된 도로의 부하와 실현 비용을 이용해 베이즈식으로 상태에 대한 사후 확률을 업데이트하는 동적 학습 메커니즘을 제안한다. 저자들은 이 과정에서 공개된 사전·사후 신념과 도로 부하 벡터가 거의 확실히 수렴함을 증명하고, 사용된 도로에 대해서는 정확한 비용 학습이 이루어지지만, 사용되지 않은 도로는 학습이 불완전할 수 있음을 밝힌다. 또한 완전 학습이 보장되는 조건과 시리즈‑패러렐 네트워크에서의 비용 하한을 제시한다.
상세 분석
이 연구는 비원자적 여행자들이 동일한 출발‑도착 쌍을 가진 교통망에서 반복적으로 라우팅 게임을 수행한다는 가정하에 전개된다. 네트워크 상태 s는 사전 확률 θ₀에 의해 초기화되며, 각 상태마다 특정 도로 e의 비용 함수 ℓₛₑ(·)가 부하 wₑ에 대해 엄격히 증가하고, 미분값이 양의 하한 α>0을 갖는다(A1). 실현 비용은 가우시안 잡음 εₖₑ를 더한 형태이며, 잡음은 평균 0, 비퇴화 공분산 Σ을 갖는 독립 동일분포이다(A2).
각 단계 k에서 정보 시스템은 현재 사전 θₖ₋₁을 방송하고, 여행자들은 기대 비용 E_{θₖ₋₁}
댓글 및 학술 토론
Loading comments...
의견 남기기