밀도 변환으로 메모리 절감·MPI 성능 향상: 변환기 모델 대규모 학습 혁신
초록
본 논문은 TensorFlow 기반 Transformer 모델에서 가정된 희소 텐서를 강제로 밀도로 전환하여 메모리 사용량을 82배 감소시키고, MPI 집계 연산을 gather에서 reduce로 바꿈으로써 CPU‑only 환경에서 1200 MPI 프로세스(300노드)까지 91% 수준의 약한 스케일링 효율과 400 MPI 프로세스(200노드)까지 65% 수준의 강한 스케일링 효율을 달성한 연구이다.
상세 분석
이 연구는 최신 NMT(Neural Machine Translation) 시스템인 Transformer가 대규모 데이터와 다수의 에포크를 필요로 함에도 불구하고, 분산 학습 시 메모리 병목 현상으로 확장성이 크게 제한된다는 문제점을 정확히 짚어낸다. 특히 TensorFlow가 gradient accumulation 단계에서 입력 gradient의 형태를 검사해, 두 종류의 텐서(희소 IndexedSlices와 밀도 Tensor)를 구분하고, 희소 텐서가 포함될 경우 gather 기반 집계를 선택하도록 설계된 점을 지적한다. Transformer의 임베딩 레이어와 projection 레이어는 동일한 가중치 행렬을 공유하지만, 전자는 gradient가 매우 희소하고 후자는 밀도가 높다. TensorFlow는 이 두 gradient를 모두 IndexedSlices 형태로 변환해 concatenate(gather) 연산을 수행하게 만들며, 이는 MPI 메시지 버퍼가 11 GB를 초과하는 대용량 데이터를 전송하게 만든다. 결과적으로 32 MPI 프로세스 이상에서는 OOM 오류와 급격한 스케일링 효율 저하가 발생한다.
논문은 Horovod의 DistributedOptimizer에 sparse_as_dense=True 옵션을 도입해 모든 gradient를 강제로 밀도 Tensor로 변환하도록 수정한다. 이 변경은 두 가지 핵심 효과를 만든다. 첫째, TensorFlow가 gradient accumulation을 reduce 연산으로 처리하게 되어, 메시지 크기가 11.4 GB에서 139 MB(≈82배 감소)로 축소된다. 둘째, 연산 시간도 4320 ms에서 169 ms(≈25배 감소)로 크게 단축된다. 이러한 메모리와 시간 절감은 각 MPI 프로세스당 메모리 풋프린트를 크게 낮추어, 더 많은 프로세스를 동시에 사용할 수 있게 하고, 배치 크기를 확대하면서도 OOM을 방지한다.
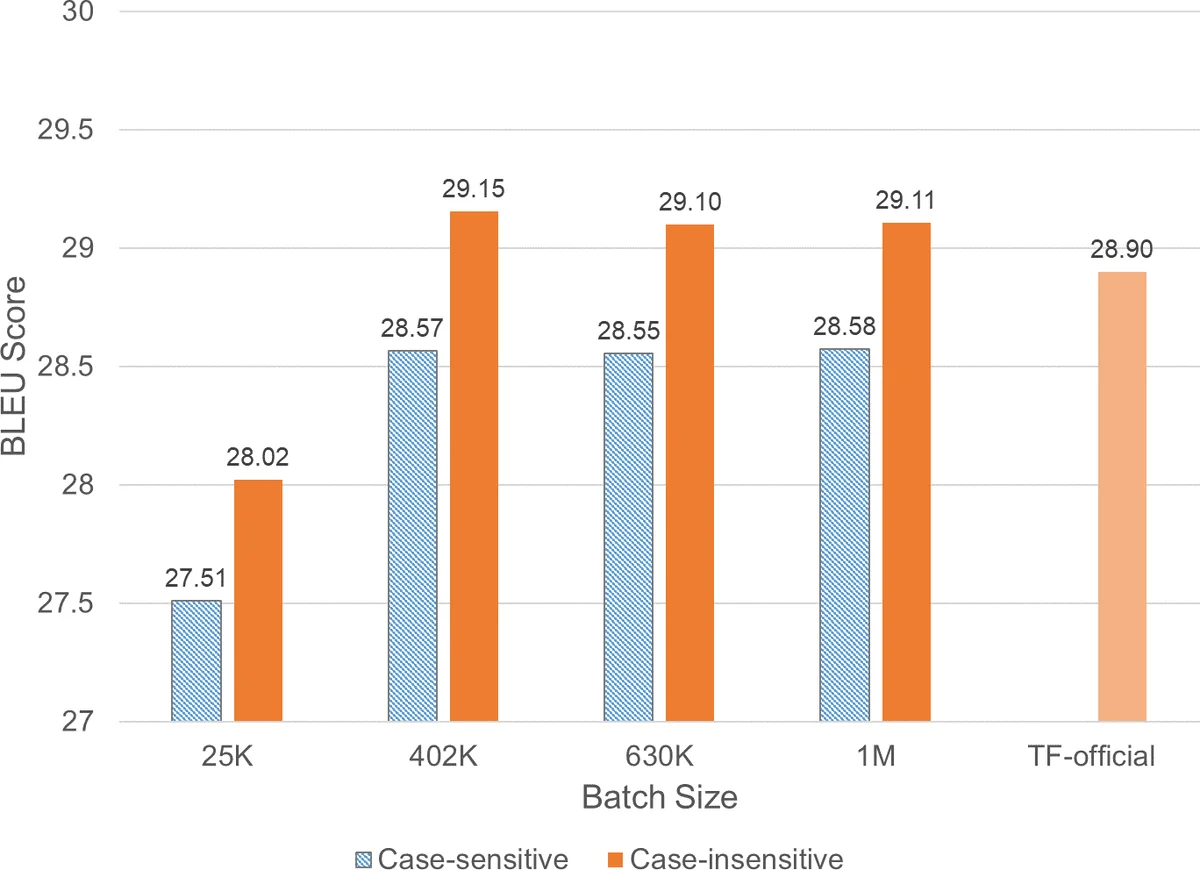
실험에서는 두 슈퍼컴퓨터(델 EMC Zenith, 텍사스 A&M Stampede2)에서 동일한 Transformer 모델을 WMT‑17 영어‑독일 코퍼스로 학습시켰다. 약한 스케일링 테스트에서는 4 PPN(프로세스 per node) 설정으로 1200 MPI 프로세스까지 91.5% 효율을 유지했으며, 강한 스케일링에서는 전체 배치를 819 200 토큰으로 고정하고 200‑300 노드까지 확장했을 때 6시간 이하로 학습 시간을 단축, BLEU 27.5 점의 번역 품질을 유지했다. 특히, 희소 텐서 집계 방식(gather)과 밀도 텐서 집계 방식(reduce)의 스케일링 효율 차이를 그래프와 수치로 명확히 보여주어, 메모리 절감이 단순히 저장 공간을 아끼는 수준을 넘어 통신 비용과 전체 시스템 효율성에 결정적 영향을 미친다는 점을 입증한다.
이 연구는 Horovod 0.15.2 이후 버전에 해당 옵션이 기본 포함됨을 알리며, 다른 대규모 딥러닝 모델에서도 유사한 희소‑밀도 혼합 구조가 존재한다면 동일한 접근법을 적용해 확장성을 크게 향상시킬 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기