악기 라벨 기반 엔드투엔드 사운드 소스 분리
초록
본 논문은 Wave‑U‑Net을 확장하여 악기 라벨을 이용한 멀티소스 엔드투엔드 모노럴 음악 분리를 제안한다. 최대 N개의 악기 출력을 고정하고, 존재하지 않는 악기에는 무음 트랙을 학습시켜 비정형적인 소스 수에 대응한다. 또한 bottleneck에서 라벨을 곱셈적으로 조건화함으로써 분리 성능을 향상시킨다.
상세 분석
이 연구는 기존 Wave‑U‑Net이 사전 정의된 소스 수(2·4)만 지원한다는 한계를 극복하기 위해 두 가지 주요 변형을 도입한다. 첫 번째는 “Exp‑Wave‑U‑Net”으로, 전체 데이터셋에 등장하는 모든 악기를 최대 N(예: 13)개의 출력 채널에 매핑하고, 실제 믹스에 포함되지 않은 악기에는 무음 오디오를 학습시켜 모델이 언제든지 가변적인 소스 수에 대응하도록 설계했다. 이는 “고정‑출력‑다중‑소스” 전략이라 할 수 있으며, 학습 단계에서 각 출력 채널에 어떤 악기가 대응되는지를 명시하지만 추론 시에는 에너지 임계값만으로 활성 소스만을 선택한다는 점이 특징이다.
두 번째 변형은 “CExp‑Wave‑U‑Net”으로, 악기 존재 여부를 나타내는 이진 라벨 벡터를 bottleneck(인코더‑디코더 사이의 가장 압축된 표현)에서 곱셈적으로 적용한다. 곱셈 조건화는 해당 악기가 활성화될 경우 해당 채널의 특성을 강화하고, 비활성 악기일 경우 신호를 억제한다. 이 방식은 early‑fusion(인코더 초입)이나 late‑fusion(디코더 최종)보다 메모리·연산 비용이 적으면서도 중요한 정보는 보존한다는 장점을 가진다.
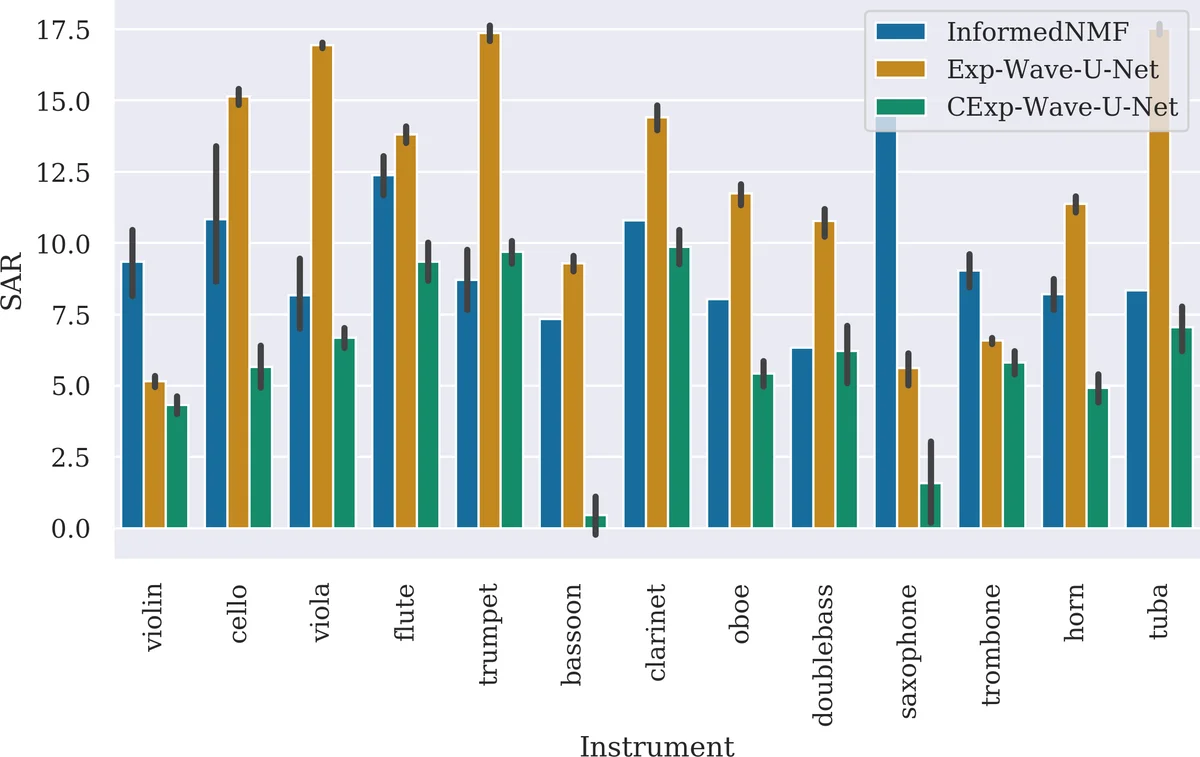
데이터는 URMP(University of Rochester Musical Performance) 데이터셋을 사용했으며, 44곡 중 33곡을 학습·검증, 11곡을 테스트에 활용했다. 실험에서는 Informed‑NMF(악기별 timbre 모델을 사전에 학습한 비음향 기반 방법)와 비교했으며, 평가 지표는 SDR, SIR, SAR을 사용했다. 결과는 다음과 같다. 전체 평균 SDR에서는 Informed‑NMF이 가장 높았지만, CExp‑Wave‑U‑Net은 SIR에서 가장 우수했으며, Exp‑Wave‑U‑Net은 SAR에서 가장 높은 값을 기록했다. 특히 소스 수가 3~4개로 증가할수록 CExp‑Wave‑U‑Net의 성능 저하 폭이 다른 두 방법보다 작아, 라벨 조건화가 다중 악기 상황에서 강인함을 제공함을 확인했다. 악기별 분석에서도 CExp‑Wave‑U‑Net이 tuba, double‑bass, saxophone, viola 등 저음역 악기에서 상대적으로 좋은 SDR·SIR을 보였으며, 반면 SAR에서는 전체적으로 낮은 점수를 받았다(즉, 잔여 잡음이 다소 남음).
한계점으로는 (1) 동일 악기군 내 다중 파트(예: violin 1 vs violin 2)를 구분하지 못한다는 점, (2) 라벨이 0/1 이진값에만 의존해 연주 강도나 뉘앙스를 반영하지 못한다는 점, (3) 표준 BSS 평가 지표가 무음 트랙에 대해 정의되지 않아 실제 “불필요한 소스 억제” 능력을 정량화하기 어렵다는 점을 들 수 있다. 향후 연구에서는 시각 정보(영상에서의 악기 움직임)와 결합한 멀티모달 조건화, 연속적인 라벨(예: MIDI 노트 정보) 활용, 그리고 동일 악기 다중 파트 구분을 위한 추가적인 어텐션 메커니즘 도입이 제안된다.
전반적으로 이 논문은 Wave‑U‑Net 구조에 라벨 기반 곱셈 조건화를 적용함으로써, 고정된 출력 채널 수 내에서 가변적인 소스 수와 악기 정보를 효율적으로 처리할 수 있음을 실험적으로 입증했다. 이는 음악 정보 검색, 자동 믹싱, 그리고 멀티모달 음악 분석 등 실용적인 응용 분야에 중요한 전진을 의미한다.
댓글 및 학술 토론
Loading comments...
의견 남기기