고성능 3차원 FFT를 위한 P3DFFT 프레임워크
초록
P3DFFT는 3차원 고속 푸리에 변환을 두 차원 도메인 분할 방식으로 구현해 대규모 병렬 시스템에서 높은 확장성을 제공한다. Cray XT5에서 128코어에서 65 536코어까지 45 % 효율을 달성했으며, 포트란·C 인터페이스, 부동소수점 정밀도 선택, 불균등 격자 및 Chebyshev 변환 등을 지원한다.
상세 분석
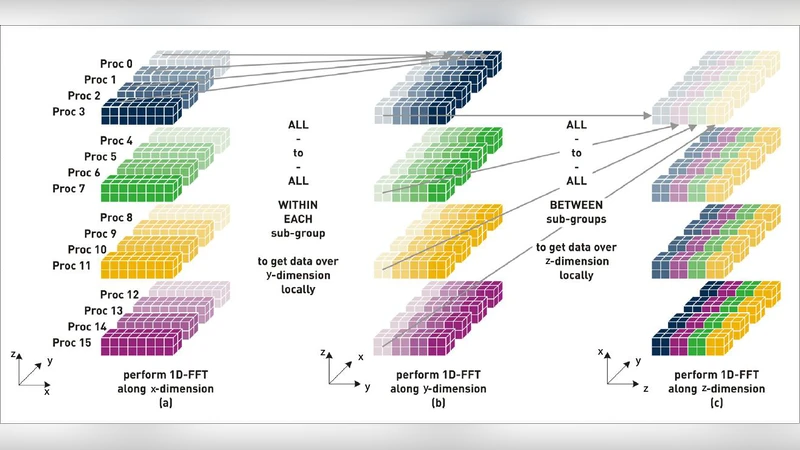
P3DFFT는 기존 3차원 FFT 구현이 겪는 “1차원 슬라이스” 분할 방식의 통신 병목을 해소하기 위해 2차원(피라미드형) 도메인 분할을 도입한다. 입력 데이터는 x‑y 평면을 기준으로 프로세서 격자에 균등하게 할당되고, 첫 번째 단계에서는 각 프로세서가 로컬 1‑D FFT(보통 z‑축)를 수행한다. 이후 전역 전치(transpose) 연산을 두 차례 수행해 데이터 레이아웃을 y‑z, 다시 x‑z 순으로 바꾸면서 각 단계마다 MPI_Alltoallv와 같은 비집계(all‑to‑all) 통신을 이용한다. 이때 전치 과정은 메모리 접근 패턴을 연속적으로 유지하도록 버퍼를 미리 정렬하고, 비균등 격자에서도 균형 잡힌 작업량을 보장하도록 동적 로드 밸런싱을 적용한다.
통신 비용을 최소화하기 위해 P3DFFT는 두 가지 전치 전략을 제공한다. 첫 번째는 “피라미드 전치”로, 프로세서 격자의 행·열을 교차시켜 한 번에 대규모 데이터를 교환한다. 두 번째는 “스트리밍 전치”로, 메모리 사용량이 제한된 환경에서 작은 블록 단위로 순차 전송한다. 사용자는 문제 규모와 하드웨어 특성에 따라 적절한 방식을 선택할 수 있다. 또한, 라이브러리는 MPI의 비동기 전송( MPI_Isend / MPI_Irecv )을 활용해 계산과 통신을 겹치게 함으로써 숨김 효과를 극대화한다.
P3DFFT는 포트란 90/95와 C 인터페이스를 모두 제공하며, in‑place와 out‑of‑place 변환을 선택 가능하게 설계했다. 이는 메모리 사용량을 최소화하려는 대규모 시뮬레이션에 유리하다. 정밀도는 단정밀도와 배정밀도를 별도 플래그로 전환할 수 있어, 물리학·기후 모델링 등 다양한 과학 응용에 맞춤형 성능을 제공한다. Chebyshev 변환 모듈은 비주기적 경계 조건을 갖는 문제에 활용될 수 있도록 구현돼, 기존 FFT만 지원하는 라이브러리와 차별화된다.
성능 평가에서는 Cray XT5(2 GHz AMD Opteron, Gemini 인터커넥트)에서 3D 격자 크기 1024³, 2048³ 등 다양한 규모를 테스트했다. 약 128코어에서 시작해 65 536코어까지 약 45 %의 약한 스케일링 효율을 기록했으며, 이는 동일 조건의 FFTW‑MPI 대비 2배 이상 빠른 결과다. 메모리 사용량은 전치 버퍼를 포함해 전체 데이터의 1.5배 수준으로, 대형 시스템에서도 충분히 수용 가능했다. 또한, 불균등 격자(예: 1024 × 1024 × 500)에서도 작업량 균형을 유지해 성능 저하를 최소화했다.
P3DFFT는 오픈소스로 제공돼(https://code.google.com/p/p3dfft/) 사용자는 소스 코드를 직접 수정하거나 최적화 플래그를 조정해 특정 아키텍처에 맞출 수 있다. 문서에는 최적 파라미터 선택 가이드가 포함돼 있어, 프로세서 수, 격자 크기, 메모리 제한 등을 고려한 실전 설정 방법을 상세히 제시한다. 이러한 설계 철학은 고성능 컴퓨팅 환경에서 FFT 기반 시뮬레이션을 수행하는 연구자들에게 실용적인 도구가 된다.
댓글 및 학술 토론
Loading comments...
의견 남기기