분류 특성 중심 손실로 적대적 견고성 강화
초록
본 논문은 기존 소프트맥스 교차 엔트로피 손실에 중심 손실을 추가함으로써 클래스별 특징 벡터를 집약하고 intra‑class 변동을 감소시키는 방법을 제안한다. MNIST, CIFAR‑10, CIFAR‑100에서 다양한 백색·흑색 공격과 적대적 학습을 실험한 결과, 중심 손실을 적용한 모델이 기존 모델보다 적대적 예제에 대해 현저히 높은 정확도를 보이며, 특히 강력한 PGD·CW 공격에서도 유의미한 방어 효과를 확인하였다.
상세 분석
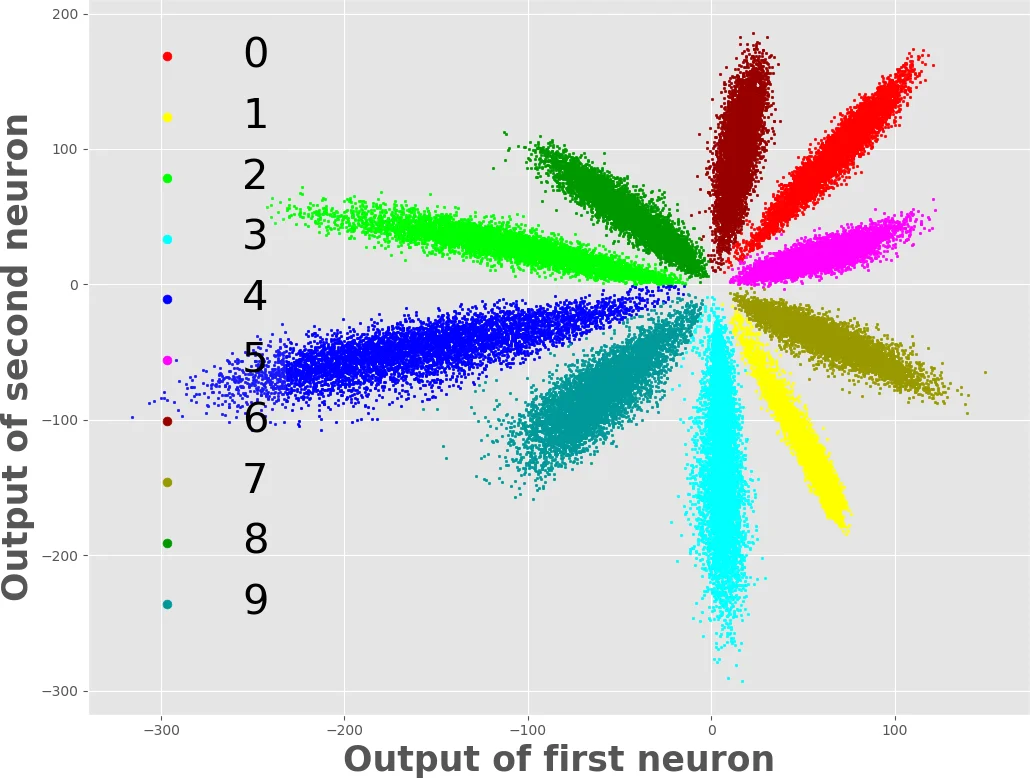
이 연구는 딥러닝 모델의 적대적 취약성을 특징 공간의 분산 구조와 연결시킨다. 기존 소프트맥스 손실은 클래스 간 경계를 넓히는 방향으로 파라미터를 최적화하지만, 특징 벡터 자체의 군집화 정도는 제어하지 않는다. 따라서 동일 클래스 내 샘플들이 서로 멀리 흩어져 있을 경우, 작은 입력 변형만으로도 다른 클래스의 경계 영역을 침범하게 된다. 논문은 이를 해결하기 위해 Center Loss를 도입한다. Center Loss는 각 클래스마다 하나의 중심 벡터 (c_k) 를 유지하고, 미니배치 내 모든 샘플 (x_i) 에 대해 (|f(x_i)-c_{y_i}|^2) 를 최소화한다. 여기서 (f(\cdot))는 마지막 전소프트맥스 특징 맵을 의미한다. 이 손실은 intra‑class 분산을 직접 감소시키며, 동시에 소프트맥스 손실이 제공하는 inter‑class 분리 압력을 유지한다. 결과적으로 특징 공간은 각 클래스마다 고밀도 구형 군집으로 수축하고, 군집 간 거리는 상대적으로 확대된다.
수식 (3)에서 두 손실을 가중치 (\lambda) 로 결합했으며, 실험에서는 (\lambda=1) 로 고정하였다. 이는 두 목표가 동등하게 중요하다는 가정 하에 설정된 값이며, 실제 구현에서는 학습 안정성을 위해 중심 업데이트에 모멘텀을 적용한다. 중심 업데이트는 미니배치 평균을 이용한 지수 이동 방식으로, 급격한 변동을 방지한다.
실험 설계는 크게 네 부분으로 나뉜다. 첫째, MNIST에서 LeNet 기반 MLP를 두 종류(Softmax‑only, Softmax+Center)로 학습하고, FGSM, PGD, CW 등 다양한 공격에 대한 정확도를 비교하였다. 둘째, CIFAR‑10/100에서 VGG‑19, ResNet‑18, DenseNet‑40을 동일하게 학습시켜 백색 공격에 대한 방어 효과를 측정했다. 셋째, 동일 모델들을 흑색 공격(단일 픽셀, 진화 기반)에 적용해 일반화된 방어 능력을 검증하였다. 넷째, 기존 적대적 학습(AT)과 Center Loss를 결합한 AT+Center 모델을 도입해, AT만 사용했을 때보다 더 높은 적대적 정확도를 달성함을 보였다.
결과적으로, Center Loss를 적용한 모델(DSC)은 테스트 정확도에서는 약간 감소하거나 비슷한 수준을 유지하면서, 적대적 정확도에서는 10%50% 이상 향상되었다. 특히 강력한 PGD·CW 공격에서는 CIFAR‑10 ResNet‑18 기준 68.64%→74.29%(≈8% 상승), CIFAR‑100 VGG‑19 기준 40.26%→38.63%(소폭 감소) 등 데이터셋·아키텍처에 따라 차이가 있긴 하지만, 전반적으로 통계적으로 유의미한 개선(p<0.05)을 보였다. 또한, Center Loss와 AT를 결합한 모델은 AT만 사용했을 때보다 적대적 정확도가 평균 25% 정도 추가 상승하였다.
이러한 결과는 특징 공간을 명시적으로 군집화하는 것이 적대적 방어에 기여한다는 가설을 실증한다. 특히, 적대적 공격이 특징 공간을 이동시켜 경계 영역을 넘는 메커니즘을 고려할 때, intra‑class 분산이 작을수록 동일 클래스 내에서의 작은 변형이 다른 클래스의 중심까지 도달하기 어려워진다. 따라서 Center Loss는 방어 메커니즘을 손실 함수 수준에서 제공하는 간단하면서도 효과적인 방법으로 평가된다. 다만, 중심 손실이 과도하게 강제될 경우 클래스 간 거리 감소와 테스트 정확도 저하가 발생할 수 있어, (\lambda) 조절 및 중심 업데이트 전략이 중요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기