가상현실에서 인간‑에이전트 공동 행동 학습
초록
본 연구는 VR 기반 포식 과제를 통해 인간 파일럿과 학습형 코파일럿 에이전트가 예측·정책 학습과 음성 신호를 이용한 의사소통을 수행하며 공동 목표를 달성하는 과정을 탐색한다. 세 가지 조건(코파일럿 없음, Pavlovian 제어, 밴딧 정책)에서의 행동 변화를 비교해 인간‑기계 공동 행동의 가능성을 시연한다.
상세 분석
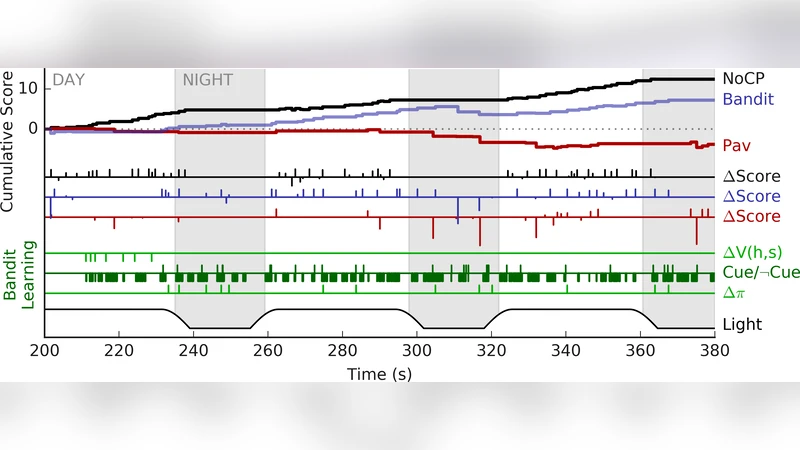
이 논문은 인간‑기계 공동 행동(joint action)의 실시간 학습 메커니즘을 검증하기 위해 가상현실(VR) 환경을 설계하고, 단일 피험자를 대상으로 세 가지 실험 조건을 적용하였다. 첫 번째 조건(NoCP)은 인간이 스스로 과일을 수확하는 기본 상황으로, 에이전트의 개입이 없으므로 인간의 순수한 패턴 학습 능력을 측정한다. 두 번째 조건(Pav)은 코파일럿이 학습된 가치 함수 V(h,s)를 기반으로 정해진 음성 cue를 제공하는 Pavlovian 제어 방식을 사용한다. 여기서 인간은 왼손 컨트롤러로 과일을 ‘가르치고’ 가치 업데이트를 수행하며, 코파일럿은 V가 양수이면 해당 과일에 고유 음향을 재생한다. 이는 인간에게 예측 기반 피드백을 제공하지만, 행동 선택에 대한 에이전트의 의도적 조절은 없다. 세 번째 조건(Bandit)은 컨텍스추얼 밴딧 알고리즘을 적용해 V를 상태로 삼아 확률적 정책 π(V)를 학습한다. 코파일럿은 cue를 재생할지 여부를 스스로 결정하고, 인간이 과일을 수확했을 때 얻은 보상에 따라 정책을 강화·약화한다. 이 구조는 인간의 행동과 에이전트의 의사결정이 상호작용하는 진정한 공동 행동을 구현한다는 점에서 가장 혁신적이다.
실험 설계는 ‘낮·밤’ 조명 변화를 도입해 인간의 시각 정보가 제한되는 상황을 만들었으며, 이는 인간이 에이전트의 음성 cue에 더 의존하도록 유도한다. 과일은 색상(hue, saturation)과 리핑 사이클을 통해 보상이 변동하는 복합적인 신호를 제공한다. 이러한 설계는 인간이 단순히 색을 인식하는 수준을 넘어, 시간에 따른 보상 패턴을 추론하도록 만든다.
결과는 밴딧 코파일럿이 밤 시간대에 인간의 포식 행동을 증가시키는 반면, Pav 조건에서는 cue 해석 오류로 인한 실수도 증가함을 보여준다. 특히, ‘음성 cue와 보상 사이의 시간 지연’과 ‘신용 할당(credit assignment)’ 문제가 공동 행동에서 핵심적인 제약으로 작용한다는 점을 강조한다. 논문은 정책 기반 코파일럿이 더 높은 적응성을 제공한다는 결론을 내리지만, 샘플 수가 1명에 불과하고 실험 블록이 제한적이라는 통계적 일반화의 한계가 있다. 또한, 인간의 시선, 머리 위치, 손 움직임 등 추가적인 멀티모달 신호를 활용하면 cue 타이밍을 더욱 정교하게 조정할 수 있을 것으로 기대된다.
향후 연구는 (1) 다중 피험자를 통한 통계적 검증, (2) 복합 감각(시선, 뇌파 등) 기반의 상황 인식 모델 통합, (3) 장기 지속 학습을 위한 지속적인 정책 업데이트 메커니즘, (4) 실제 로봇 혹은 AR 환경으로의 전이 등을 제안한다. 전반적으로 이 연구는 VR이라는 안전하고 통제된 플랫폼에서 인간‑에이전트 공동 학습을 구현한 최초 사례 중 하나이며, 인간의 인지·행동 제한을 보완하는 지능형 에이전트 설계에 중요한 실증적 토대를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기