데이터셋 외 화자 지원을 위한 다대다 음성 변환
초록
본 논문은 Cycle‑GAN에 화자 임베딩 추출기를 결합해, 훈련에 사용되지 않은 화자와도 양방향으로 음성 변환이 가능한 다대다 음성 변환 모델을 제안한다. 화자 임베딩은 공동 학습을 통해 얻어지며, 단일 생성기와 단일 판별기로 모든 화자 간 변환을 수행한다. 인‑데이터셋 화자에 대해서는 기존 최첨단 모델과 동등한 스타일 변환 품질을 보이며, 아웃‑오브‑데이터셋 화자에 대해서는 별도 재학습 없이도 자연스러운 변환이 가능함을 확인하였다.
상세 분석
제안된 시스템은 크게 세 부분으로 구성된다. 첫째, 멜‑스펙트로그램을 입력으로 하는 CNN 기반 Feature Extractor(FE)이며, 이는 각 화자의 음성에서 화자 고유의 스타일을 압축한 임베딩 eₛ를 생성한다. FE는 다수의 화자(251명)로 구성된 Librispeech train‑clean‑100 데이터에서 공동 학습되며, 임베딩 차원은 1×8×8로 설계돼 시간 축에 대한 평균 풀링 후 복제 과정을 거쳐 생성기(G)의 bottleneck에 결합된다. 둘째, 동일한 CNN 구조를 공유하는 Generator(G)는 입력 멜‑스펙트로그램 Uₛⱼ와 목표 화자 임베딩 eₛₖ를 결합해 변환된 스펙트로그램 Ũₛₖ를 출력한다. 여기서 임베딩은 bottleneck 레이어에 채널 차원으로 concat되어 스타일 정보를 직접 주입한다. 셋째, 단일 Discriminator(D)는 2N개의 출력(각 화자에 대한 real/fake)을 갖는 다중 클래스 소프트맥스 구조로, 실제 화자와 변환된 화자를 동시에 판별한다. D는 서로 다른 시간 길이의 패치를 세 개의 서브‑CNN으로 처리해 시간적 다양성을 포착한다. 학습 목표는 전통적인 Cycle‑GAN 손실(L_G, L_D)과 함께 L1 기반 사이클 일관성 손실(L_cycle)을 사용해 내용 보존을 강제한다.
핵심 차별점은 화자 임베딩을 one‑hot 벡터가 아닌 학습 가능한 연속 표현으로 대체함으로써, 훈련에 포함되지 않은 화자에 대해서도 FE가 의미 있는 임베딩을 생성한다는 점이다. 이는 FE가 화자별 스펙트럼 분포를 일반화하도록 설계된 결과이며, 실험에서는 dev‑clean에 포함된 40명의 아웃‑오브‑데이터셋 화자에 대해 높은 화자 식별 정확도를 보였다. 또한, 기존 연구와 달리 두 개의 별도 판별기 대신 하나의 다중 클래스 판별기를 사용해 모델 복잡도를 낮추고 학습 안정성을 향상시켰다.
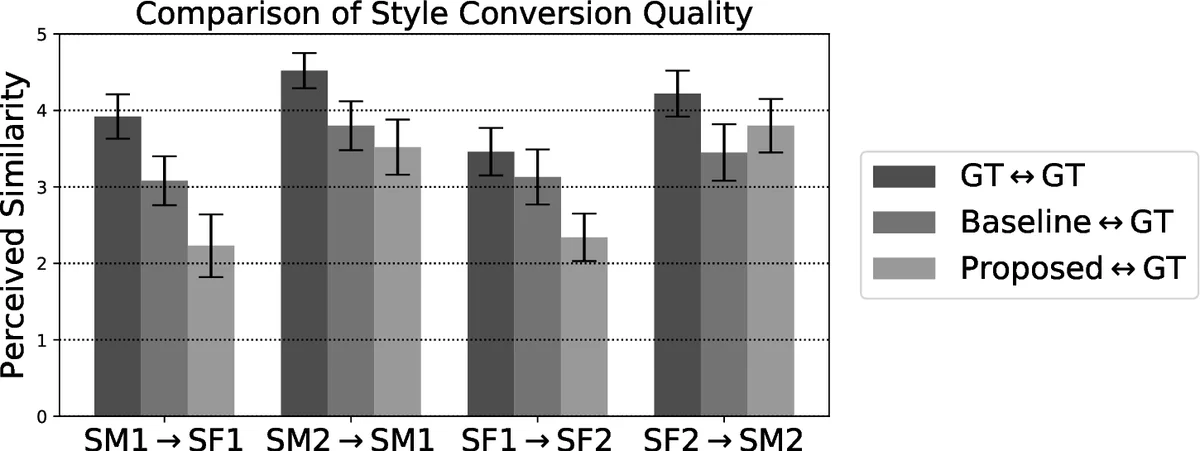
음성 재구성 단계에서는 Griffin‑Lim 알고리즘을 적용했으며, 이는 Vocoder 기반 재구성에 비해 위상 오류와 노이즈가 발생할 수 있어 MOS 점수가 약간 낮게 나타났다. 그러나 인간 청취자 실험에서는 스타일 변환 유사도 측면에서 기존 Cycle‑GAN 기반 베이스라인과 거의 동등한 결과를 얻었다. 특히, 251명의 화자를 대상으로 한 대규모 실험에서 아웃‑오브‑데이터셋 화자 간 변환이 가능한 최초 사례로 평가된다.
전반적으로 본 연구는 화자 임베딩을 통한 일반화 가능성을 입증함으로써, 다수의 화자를 동시에 지원하고 새로운 화자에 대해 재학습 없이 즉시 적용 가능한 실용적인 음성 변환 프레임워크를 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기