의료 영상 라벨링의 함정 방사선 보고서와 실제 영상 사이의 격차
초록
이 논문은 1,000개의 흉부 X‑ray와 해당 방사선 보고서를 이용해, 영상에서 직접 확인한 이상과 보고서에 기술된 이상 사이에 큰 불일치가 존재함을 실증한다. 보고서 기반 라벨을 ‘골드 스탠다드’로 삼는 기존 자동 라벨링(NLP) 방법은 실제 영상 라벨과 비교했을 때 정밀도·재현율 모두 낮으며, 특히 비행동성(Non‑actionable) 소견과 경계성 소견에서 오류가 크게 발생한다. 연구는 이러한 라벨링 오류가 AI 모델 학습에 미치는 위험성을 강조하고, 라벨링 과정에서 인간 전문가의 역할과 보고서 작성 정책을 재고할 필요성을 제시한다.
상세 분석
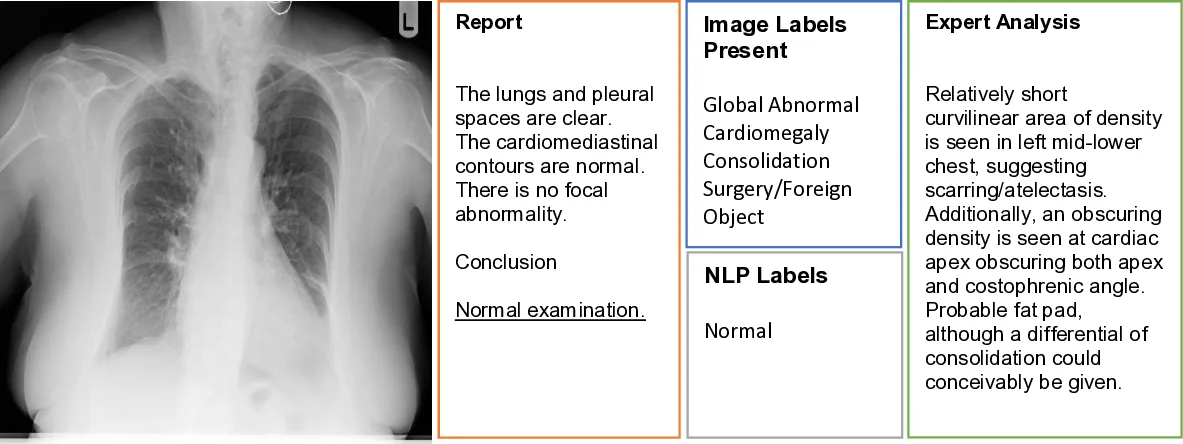
본 연구는 두 단계의 라벨링 프로세스를 설계하였다. 첫 번째 단계는 방사선과 전문의가 직접 흉부 X‑ray 영상을 보고 네 가지 이상(전반적 이상, 심비대, 폐렴, 이물·기기) 여부를 판단한 ‘y_rad_img’ 라벨이며, 두 번째 단계는 동일 전문가가 보고서 텍스트만을 근거로 동일 항목을 판단한 ‘y_rad_txt’ 라벨이다. 두 라벨 간 F1 점수는 전반적 이상(ABN 1)에서 0.69로 비교적 높지만, 심비대(ABN 2)와 폐렴(ABN 3)에서는 각각 0.17, 0.45에 불과해 큰 차이를 보인다. 이는 방사선과가 영상에서 감지했지만 보고서에 포함되지 않은 비행동성 소견(예: 기존 치료 흔적, 연령 관련 퇴행성 변화)과 경계성 소견(예: 경미한 심비대) 때문으로 해석된다.
이어지는 자동 라벨링 단계에서는 최신 의료 NLP 모델(‘y_nlp_txt’)을 적용했으며, 보고서 라벨 대비 정밀도는 전반적 이상에서 0.81, 재현율 0.86으로 비교적 양호했지만, 심비대와 이물·기기 항목에서는 정밀도·재현율 모두 0.13~0.24 수준에 머물렀다. 이는 NLP가 보고서 내 부정어·불확실성 표현을 정확히 파악하더라도, 원본 보고서 자체가 이미 중요한 소견을 누락하고 있기 때문이다.
실패 분석에서는 24%의 보고서가 ‘정상’으로 분류되었으나 영상에서는 이상이 존재했고, 반대로 20%는 ‘비정상’으로 보고되었으나 영상에서는 이상이 없었다는 사실을 밝혀냈다. 주요 원인으로는 (1) 비행동성 소견을 임상적 의사결정에 필요 없다고 판단해 보고서에 생략, (2) 미세하거나 경계성 소견에 대한 해석 차이, (3) 환자 자세·호흡량·기술적 잡음 등 이미지 품질 변동, (4) 피로에 의한 인간 오류 등이 제시되었다.
이러한 결과는 라벨링 오류가 모델 학습에 직접적인 노이즈로 작용함을 의미한다. 특히 흉부 X‑ray와 같이 특이도가 낮은 영상에서는 ‘보고서 라벨 = 진실 라벨’이라는 가정이 크게 깨질 위험이 있다. 따라서 대규모 데이터셋을 구축할 때는 (i) 다중 전문가의 이미지 기반 라벨링을 병행하고, (ii) 비행동성·경계성 소견을 별도 메타라벨로 관리하며, (iii) NLP 모델을 라벨링 전 단계가 아닌 보조 검증 단계로 활용하는 전략이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기