깊은 학습 가속화, 일시적 서버로 비용 절감과 성능 향상 동시에
초록
본 연구는 클라우드의 저렴한 ‘일시적(Transient) 서버’(예: AWS 스팟 인스턴스, GCE 선점형 VM)를 활용해 딥러닝 분산 학습의 높은 비용 문제를 해결하는 방안을 탐구합니다. 대규모 실험을 통해 일시적 서버를 사용한 분산 학습이 기존 온디맨드 서버 대비 최대 7.7배의 학습 속도 향상과 62.9%의 비용 절감 효과를 거둘 수 있음을 입증했습니다. 또한 서버의 동적 가격 및 가용성, 갑작스러운 회수(Revocation) 등 새로운 도전과제를 식별하고, 이를 해결하기 위한 ‘일시적 서버 인식(Tranisent-aware)’ 분산 학습 프레임워크 재설계의 필요성을 제시합니다.
상세 분석
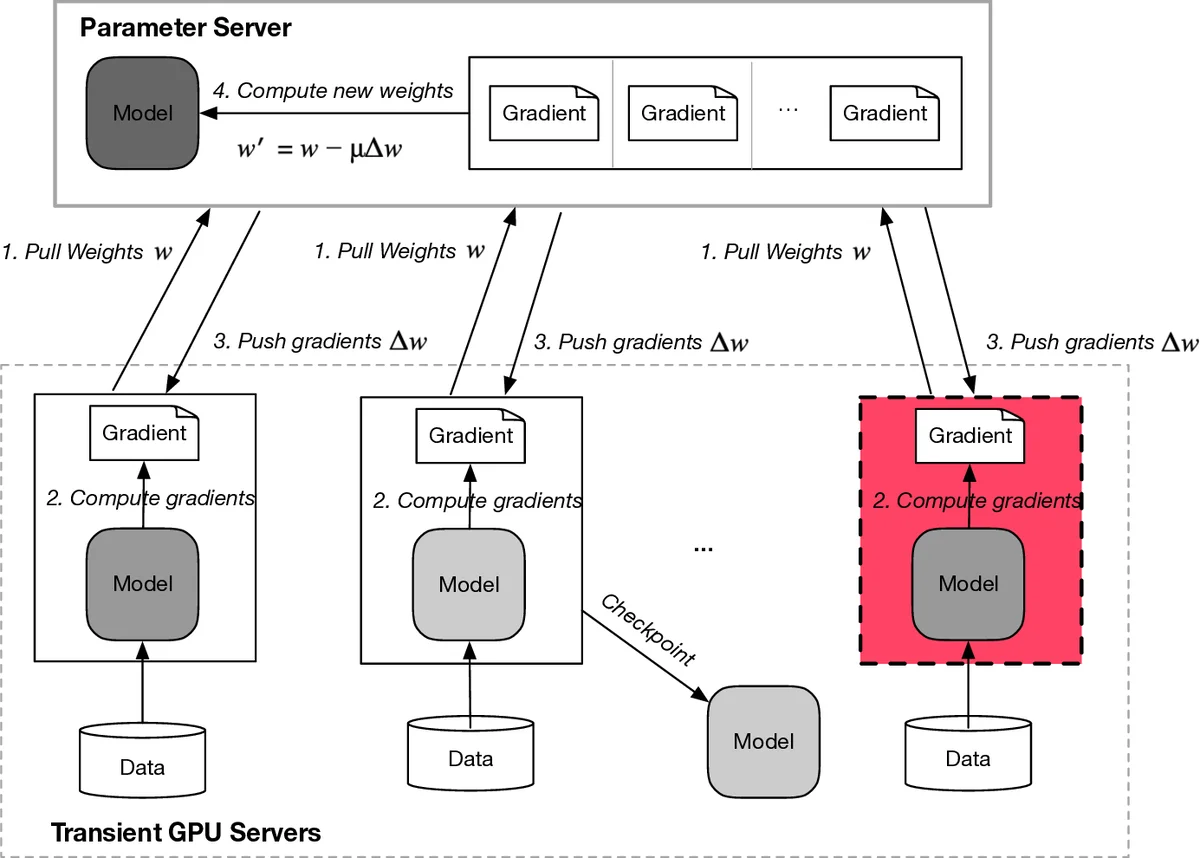
이 논문의 핵심 기술적 통찰은 기존 분산 학습 프레임워크의 안정적인 온디맨드 서버 환경에 대한 가정을 깨고, 훨씬 더 역동적이고 불확실한 리소스 풀을 효율적으로 활용하는 방법론을 제시한다는 점입니다. 연구팀은 Google Compute Engine(GCE)에서 1,000대 이상의 다양한 GPU 서버를 발동시키는 대규모 실증 분석을 수행했습니다.
주요 기술적 분석 포인트는 다음과 같습니다:
-
비용 대 성능 효율성 입증: ResNet-32 모델을 CIFAR-10 데이터셋으로 학습할 때, 단일 K80 온디맨드 GPU 대비 4대의 K80 일시적 서버 클러스터를 사용하면 평균 3.72배의 속도 향상과 62.9%의 비용 절감을 달성했습니다. 이는 ‘저렴한 서버를 더 많이 사용’함으로써 총 비용은 유지하거나 줄이면서도 절대적인 학습 시간을 획기적으로 단축할 수 있는 패러다임 전환을 보여줍니다.
-
서버 회수(Revocation) 영향의 정량화: 일시적 서버의 가장 큰 도전과제인 갑작스런 회수에 대한 영향을 최초로 체계적으로 측정했습니다. 32개 클러스터(총 128개 서버) 실험에서 13개 서버가 학습 중 회수되었습니다. 회수가 발생하더라도 파라미터 서버 기반 비동기 학습 아키텍처 덕분에 학습 자체는 중단되지 않았지만, 학습 시간이 연장되는 영향(0회수: 0.98시간 → 2회수: 1.45시간)을 확인했습니다. 이는 내결함성(Fault Tolerance) 메커니즘의 중요성을 부각시킵니다.
-
이기종 및 동적 클러스터의 가능성 제시: 논문은 일시적 서버의 가용성과 가격 변동성을 극복하기 위한 방안으로 이기종(Heterogeneous) 서버 활용 및 동적 클러스터 크기 조정의 잠재력을 언급합니다. 즉, 가격이 낮거나 가용성이 높은 순간에 다른 지역이나 다른 사양의 서버를 클러스터에 동적으로 추가/제거하는 ‘트랜시언트-인식’ 스케줄링의 필요성을 강조합니다. 이는 클라우드 리소스 관리와 머신러닝 시스템 설계의 경계를 허무는 흥미로운 연구 방향입니다.
이 연구는 단순한 성능 비교를 넘어, 클라우드 경제학과 분산 시스템의 설계 원칙이 현대 AI 모델 학습에 어떻게 깊이 관여하는지를 보여주는 중요한 실증 연구입니다.
댓글 및 학술 토론
Loading comments...
의견 남기기