GPU 가속 통계적 듀얼 에너지 X레이 CT 재구성을 위한 분할 기반 반복 알고리즘
초록
본 논문은 듀얼 에너지 CT(DECT)에서 물질 분류 정확도를 높이면서 실시간 요구를 만족하기 위해, ADMM 프레임워크 내에서 재구성 단계와 에너지 분해 단계를 분리하는 새로운 분할 기반 알고리즘을 제안한다. 제안 방법은 GPU 가속을 활용해 전통적인 LM·CG 결합 방식에 비해 연산량을 크게 줄이고, 실험적으로 합성 및 실제 수하물 팬텀에서 수렴 속도와 재구성 품질이 크게 향상됨을 보였다.
상세 분석
이 연구는 듀얼 에너지 CT의 핵심 문제인 ‘컴프턴(Compton)과 광전(PE) 계수의 동시 추정’에 초점을 맞춘다. 기존 방법은 투영 영역에서 직접 분해한 뒤 FBP(Filtration Back Projection)로 재구성하거나, MAP(Maximum A Posteriori) 추정을 위해 전체 비선형 최적화를 수행한다. 전자는 병렬화가 용이하지만 노이즈와 아티팩트에 취약하고, 후자는 높은 정확도를 제공하지만 연산 비용이 prohibitive 하다. 저자들은 이러한 딜레마를 ADMM(Alternating Direction Method of Multipliers) 내부에서 문제 분할이라는 전략으로 해결한다. 구체적으로, 원래의 비선형 최소화 문제(식 4)를 두 개의 서브문제로 나눈다. 첫 번째 서브문제는 선형 시스템 형태의 재구성으로, 이는 전통적인 CG(Conjugate Gradient) 방법과 고역통과 프리컨디셔너(예: ramp filter)를 적용해 빠르게 해결한다. 두 번째 서브문제는 에너지 분해로, 각 레이마다 독립적으로 비선형 최소화를 수행하는 UDM(Unconstrained Decomposition Method)을 적용한다. 여기서 LM(Levenberg‑Marquardt) 알고리즘은 비선형성을 다루지만, 이제는 재구성 연산과 분리돼 전체 파이프라인에서 병렬화가 가능해진다.
핵심적인 이점은 다음과 같다.
- 연산량 감소: 기존 LM·CG 결합 방식은 비선형 최적화 단계마다 전체 투영 행렬을 반복 호출해야 했지만, 제안 방식은 선형 재구성 단계와 비선형 분해 단계를 독립적으로 수행해 각각 최적화된 알고리즘을 적용한다. 표 1에 제시된 연산 복잡도 비교에서, LM·CG는 O(m·(n+1))·2 연산을 요구하는 반면, UDM·PCG는 O(2 n)·2 연산으로 약 10배 이상 효율적이다.
- GPU 친화성: 투영·역투영 연산은 Astra Toolbox와 GPUfit을 이용해 GPU에서 완전 병렬화되고, UDM 단계 역시 레이 별 독립 연산이므로 GPU 코어에 직접 매핑이 가능하다. 실험 환경(Nvidia 1080Ti)에서 평균 반복당 소요 시간이 0.12 s에서 0.04 s로 감소하였다.
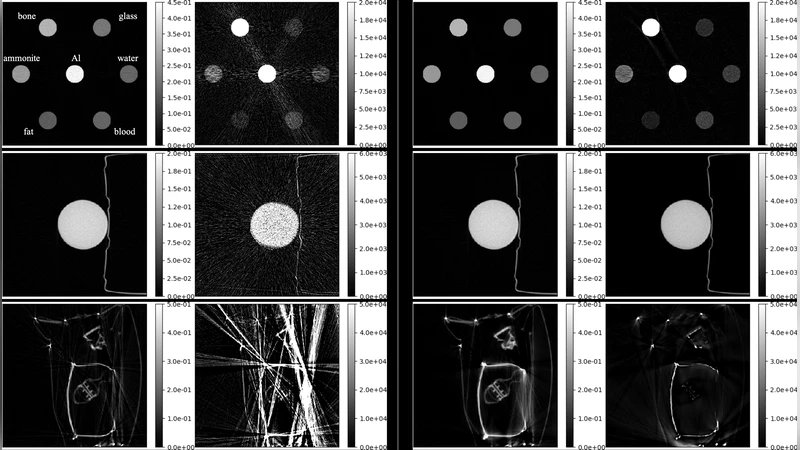
- 수렴 특성 개선: ADMM의 잔차 기반 ρ 자동 조정 메커니즘과 TV(총변량) 정규화가 결합돼, 특히 PE 계수에서 발생하던 스트리킹 아티팩트가 크게 억제되었다. 실험 결과(그림 2)에서 ξ(x) 지표가 20 dB 수준까지 빠르게 수렴했으며, 동일 정확도에 도달하는 데 필요한 전체 시간은 기존 방법 대비 60 % 이상 단축되었다.
또한, 저자들은 실제 수하물 팬텀(‘Water’와 ‘Clutter’)에 대해 정량적 ROI 분석을 수행했으며, 금속 물체가 포함된 ‘Clutter’에서는 CDM‑FBP가 심각한 오버샤도와 스트리킹을 보이는 반면, 제안 알고리즘은 물체 형태를 명확히 복원했다. 이는 통계적 사전 정보와 ADMM 기반 분할이 고대조도·고노이즈 환경에서도 견고함을 입증한다는 의미다.
한계점으로는 2‑D 평면 재구성에 국한되어 있어 3‑D 볼륨 확장 시 메모리·연산 요구가 급증할 수 있다는 점, 그리고 초기화가 CDM‑FBP 결과에 의존한다는 점을 들 수 있다. 향후 연구에서는 3‑D 구현, 더 정교한 초기화 전략(예: 딥러닝 기반 프리‑스캔) 및 다중 에너지(>2) 확장에 대한 탐색이 제안된다.
댓글 및 학술 토론
Loading comments...
의견 남기기