음성인식 향상을 위한 주의 기반 시청각 융합
본 논문은 청각 신호와 입술 영상 정보를 동시에 활용하는 새로운 융합 방식을 제안한다. 기존의 단순 특징 결합을 넘어, 두 모달리티를 인코더 단계에서 주의 메커니즘으로 정렬·통합함으로써 잡음이 섞인 환경에서도 인식 정확도를 크게 향상시킨다. TCD‑TIMIT와 LRS2 데이터셋에서 실험한 결과, 특히 저 SNR 상황에서 7%~30% 수준의 CER 감소를 확인하였다.
저자: George Sterpu, Christian Saam, Naomi Harte
본 논문은 인간의 말하기가 시청각 양쪽 정보를 동시에 활용한다는 점에 착안해, 잡음이 섞인 환경에서도 인식 정확도를 높일 수 있는 새로운 오디오‑비주얼 융합 방식을 제안한다. 서론에서는 청정 음성에서는 청각이 주된 정보를 제공하지만, 소음이 심한 상황에서는 입술 움직임 등 시각 정보가 중요한 보완 역할을 한다는 점을 강조한다. 기존 연구들은 주로 특징 결합이나 결정 결합 방식을 사용했으며, 특히 특징 결합은 두 스트림을 단순히 이어 붙이는 수준에 머물러 스트림 간 신뢰도 차이를 반영하지 못한다는 한계를 지적한다.
관련 연구 파트에서는 최신 Seq2seq 기반 ASR 모델이 높은 성능을 보이는 이유와, 이러한 모델이 시청각 융합에 적합한 구조임을 설명한다. 또한, 입술 읽기 분야에서 CNN‑ResNet 기반 비전 프론트엔드가 좋은 성능을 보이며, 기존의 양방향 어텐션이나 게이팅 메커니즘이 시청각 정렬에 충분히 활용되지 못했음을 언급한다.
제안 방법은 크게 네 단계로 구성된다. 첫째, 오디오와 비디오 입력을 각각 전처리한다. 오디오는 22 kHz로 재샘플링 후 로그 멜 스펙트로그램(90 차원)으로 변환하고, 비디오는 OpenFace를 이용해 얼굴을 정렬·크롭한 뒤 36×36 RGB 이미지로 축소한다. 둘째, 비전 프론트엔드로 ResNet‑Residual 블록을 사용해 각 프레임당 128 차원 특징을 추출한다. 셋째, 두 특징 시퀀스를 각각 3층 LSTM(256 유닛)으로 인코딩한다. 여기서 오디오와 비디오의 프레임 레이트 차이(100 FPS vs 30 FPS)를 그대로 유지한다. 넷째, 핵심인 ‘Audio‑Visual Align’ 모듈에서 오디오 인코더 최상위 레이어의 은닉 상태를 쿼리로, 비디오 인코더 메모리를 값(value)으로 삼아 어텐션 가중치를 계산한다. 이 어텐션을 통해 오디오의 각 타임스텝이 비디오 전체 프레임과 연관성을 학습하고, 결과적으로 융합된 오디오‑비주얼 특징을 생성한다.
디코더는 1층 LSTM(256 유닛)와 4개의 어텐션 헤드를 사용해 융합 메모리에서 컨텍스트 벡터를 추출하고, 문자 단위 출력 시퀀스를 생성한다. 학습은 AMSGrad 옵티마이저와 교차 엔트로피 손실을 사용했으며, 평가 지표는 문자 오류율(CER)이다.
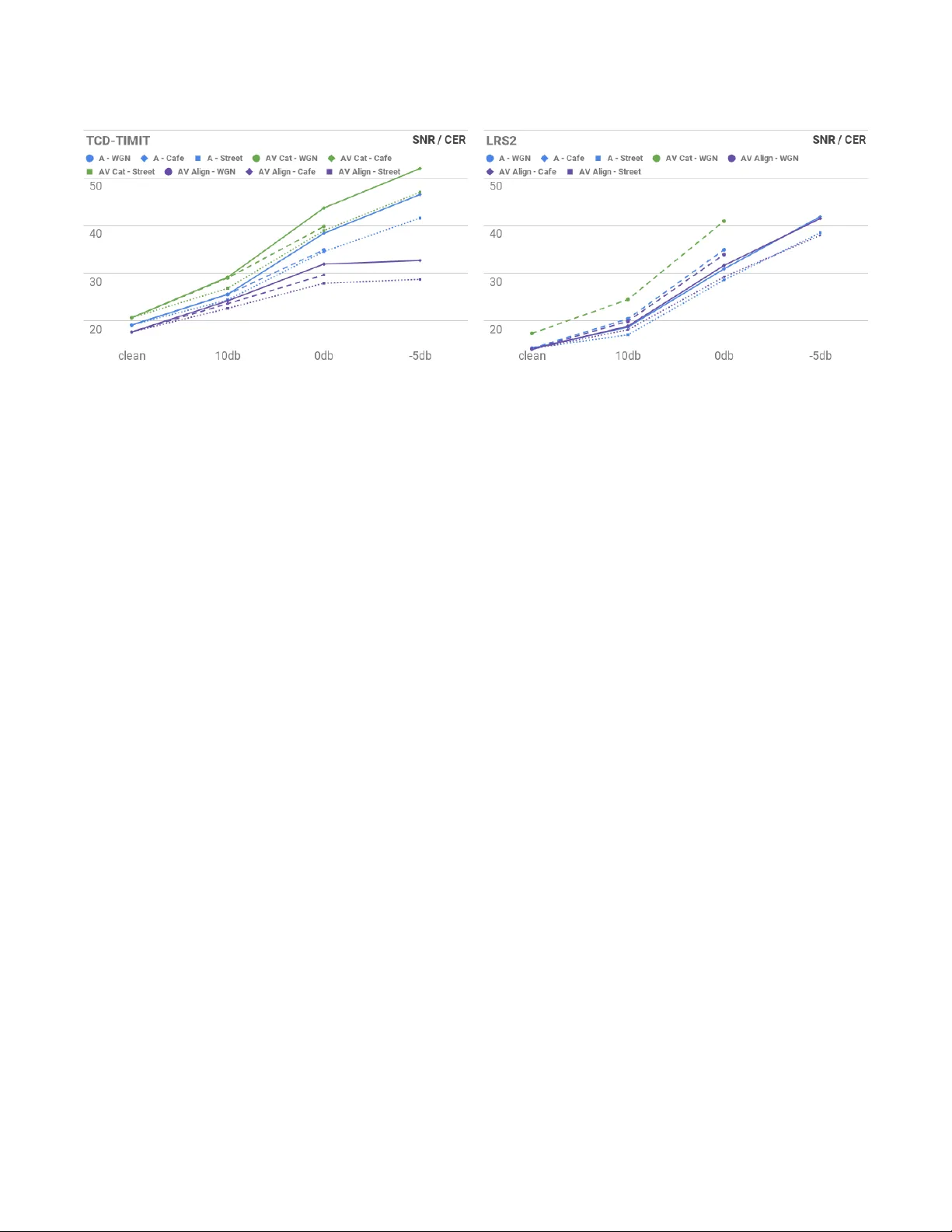
실험은 두 대규모 공개 데이터셋인 TCD‑TIMIT와 LRS2를 대상으로 진행되었다. TCD‑TIMIT는 실험실 환경에서 촬영된 6,000여 개의 읽기 문장을 포함하고, LRS2는 BBC 방송에서 추출한 45,000여 개의 자연스러운 문장을 포함한다. 각 데이터셋에 대해 청정 음성뿐 아니라 화이트 노이즈, 카페 소음, 거리 소음 세 종류를 다양한 SNR(-5 dB~+∞)에서 추가하였다.
결과는 TCD‑TIMIT에서 AV Align이 음성 전용 모델 대비 청정 조건에서 CER 19.16%→17.7%(7% 개선), -5 dB SNR에서 CER 46.52%→32.68%(30% 개선)이라는 큰 이득을 보여준다. 반면, 기존의 특징 연결 방식(AV Cat)은 오히려 성능이 저하되어, 단순 연결이 효과적이지 않음을 확인했다. LRS2에서는 시각 프론트엔드가 낮은 해상도와 다양한 얼굴 포즈에 충분히 대응하지 못해 AV Align이 음성 전용 모델과 큰 차이를 보이지 않았다. 이는 비전 모델의 성능이 전체 시스템에 미치는 영향을 강조한다.
논의 파트에서는 학습 과정에서 디코더가 초기에는 언어 모델링에 집중하고, 이후 음성 디코딩이 강화되면서 문자‑음소 매핑을 학습하는 단계적 변화를 관찰했다. 또한, LRS2와 같은 대규모·다양한 데이터에서는 더 긴 학습이 필요하고, 비전 백본을 강화하거나 사전 학습된 모델을 활용하면 시청각 융합 효과가 더욱 증대될 가능성을 제시한다.
결론적으로, 이 연구는 인코더 단계에서의 주의 기반 시청각 정렬이 잡음이 많은 환경에서 ASR 성능을 크게 향상시킬 수 있음을 실증하였다. 향후 연구에서는 양방향 어텐션, 멀티스케일 비전 모델, 그리고 대규모 사전학습을 통한 전이 학습 등을 통해 더욱 일반화된 시청각 인식 시스템을 구축하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기