적대적 특징 매핑을 이용한 음성 향상
본 논문은 기존의 MSE 기반 특징 매핑 방식에 적대적 학습을 결합한 AFM(Adversarial Feature‑Mapping) 기법을 제안한다. 강화된 특징 매핑 네트워크와 청음 특징을 구분하는 판별기(D)를 동시에 학습시켜, 향상된 특징의 분포를 실제 청음 특징에 가깝게 만든다. 또한, ASR 성능을 높이기 위해 음소(센노) 정보를 활용하는 SA‑AFM을 설계하고, CHiME‑3 데이터셋에서 청음 모델 대비 16.95 %·5.27 %·9.8…
저자: Zhong Meng, Jinyu Li, Yifan Gong
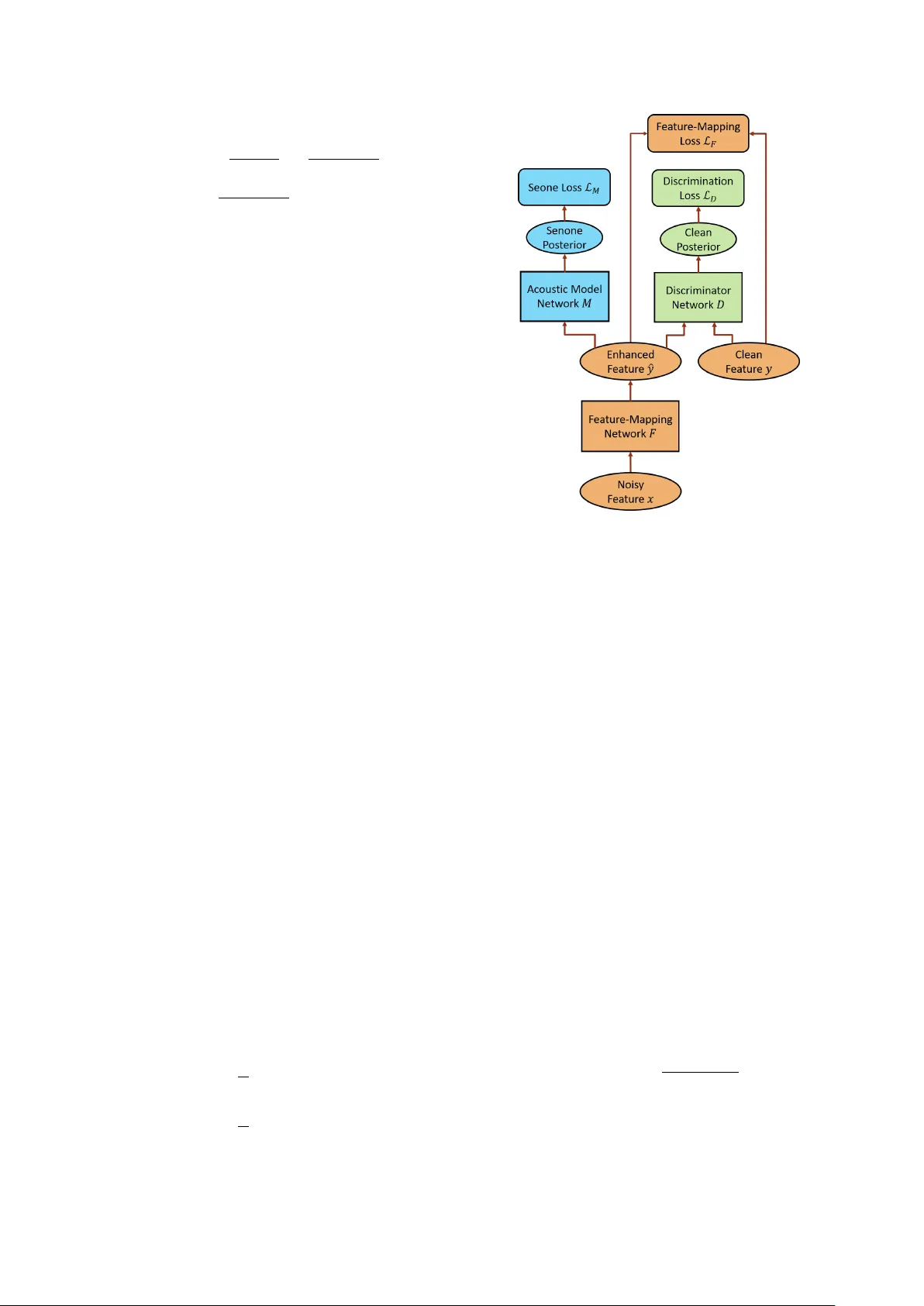
본 논문은 단일 채널 음성 향상에서 널리 사용되는 특징 매핑(feature‑mapping) 기법을 적대적 학습(adversarial learning)과 결합한 새로운 프레임워크인 AFM(Adversarial Feature‑Mapping)을 제안한다. 전통적인 특징 매핑은 노이즈가 섞인 스펙트럼 특징 X와 청음 특징 Y가 프레임 단위로 정렬(parallel)된 데이터를 이용해, LSTM‑RNN 기반 매핑 네트워크 F를 학습시켜 MSE(Mean Square Error) 손실을 최소화한다. 그러나 MSE는 잡음이 동분산(homoscedastic)이며 서로 독립적이라는 가정을 전제로 하며, 실제 환경의 비정상적·비정상성 잡음에서는 이 가정이 크게 위배된다. 따라서 단순히 평균 제곱 오차만을 최소화해도 청음 특징과의 분포 차이가 남아, ASR 등 하위 작업에서 기대 이하의 성능을 보인다.
이를 해결하기 위해 AFM은 추가적인 판별기 D를 도입한다. D는 29차원 청음 특징과 매핑 네트워크가 생성한 향상된 특징 Ŷ를 입력받아, 각각이 ‘청음(Real)’인지 ‘향상(Fake)’인지를 이진 확률로 출력한다. D는 교차 엔트로피 손실 L_D를 최소화하도록 학습되며, 동시에 F는 L_D에 부호가 반전된 그래디언트를 받아 D를 속이는 방향으로 업데이트된다. 즉, F는 MSE 손실 L_F와 –λ·L_D(λ>0) 손실을 동시에 최소화하는 다중 과제 학습을 수행한다. 이 과정은 Gradient Reversal Layer(GRL)를 이용해 구현되며, GRL은 순전파에서는 신호를 그대로 전달하고 역전파 시 그래디언트에 –λ를 곱한다. 결과적으로 F는 청음 특징과 통계적으로 동일한 분포를 갖는 Ŷ를 생성하도록 강제된다. 학습이 수렴하면 D는 실제와 가짜를 구분하기 어려워지며, 이는 향상된 특징이 청음 특징과 거의 구별되지 않음을 의미한다.
AFM만으로도 청음 특징과의 분포 정합성이 크게 개선되었지만, ASR와 같은 최종 목표에서는 여전히 센노(senone) 레벨의 분류 정확도가 중요하다. 따라서 논문은 SA‑AFM(Senone‑Aware AFM)이라는 확장 모델을 제안한다. SA‑AFM은 기존 AFM 구조에 음향 모델 M을 추가한다. M은 LSTM 기반 네트워크로, 향상된 특징 Ŷ를 입력받아 센노 레이블 q에 대한 사후 확률 P(q|Ŷ) 를 출력한다. M은 교차 엔트로피 손실 L_M을 최소화하도록 학습되며, 전체 손실은 L_F − λ₁·L_D + λ₂·L_M 형태로 가중합된다. 여기서 λ₁은 판별 손실의 역전파 강도를, λ₂는 센노 손실의 중요도를 조절한다. 최적화는 세 네트워크가 동시에 업데이트되는 다중 과제 학습으로 진행된다. 학습 단계에서는 청음·노이즈가 정렬된 데이터와 함께 해당 음성의 전사(transcript)가 필요하지만, 테스트 단계에서는 매핑 네트워크 F와 음향 모델 M만 사용한다.
실험은 Microsoft와 Georgia Tech가 제공한 CHiME‑3 데이터셋을 기반으로 수행되었다. 훈련 데이터는 8738개의 청음‑노이즈 쌍으로 구성되며, 테스트는 실제 5번째 마이크 채널의 실시간 잡음 데이터를 사용한다. 특징은 29차원 로그 멜 필터뱅크(LFB)와 1차·2차 델타를 결합한 87차원 벡터이며, F는 2층 LSTM‑RNN(각 층 512유닛, 256차원 프로젝션)으로 구현되었다. D는 2층 피드포워드 DNN(각 층 512유닛)이며, M은 4층 LSTM(각 층 1024유닛, 512차원 프로젝션)으로 구성되었다. 학습률은 5×10⁻⁷, 모멘텀 0.5, λ₁=60, λ₂는 실험적으로 설정하였다.
성능 평가는 사전 훈련된 청음 DNN 음향 모델(7층, 2048유닛, 3012센노) 위에서 WER을 측정하였다. 결과는 다음과 같다. (1) 원본 노이즈 입력에 대한 WER은 29.44 %; (2) 전통적인 MSE 기반 특징 매핑(FM) 적용 시 25.81 % (12.33 % 상대 개선); (3) AFM 적용 시 24.45 % (16.95 % 및 5.27 % 상대 개선); (4) SA‑AFM 적용 시 다중 조건 음향 모델(Multi‑conditional) 대비 19.28 % → 17.44 % (9.85 % 상대 개선) 를 달성하였다. 특히 SA‑AFM은 청음·노이즈 모두를 사용해 훈련된 다중 조건 모델과 비교했을 때도 유의미한 이득을 보여, 센노 레벨의 목표를 직접 반영한 다중 과제 학습이 실제 인식 성능을 크게 향상시킴을 증명한다.
논문은 또한 기존 GAN 기반 음성 향상 연구와 차별점을 명확히 제시한다. 첫째, 판별기의 입력이 향상·청음 특징 자체이며, 노이즈 특징을 함께 사용하지 않는다. 둘째, 기본 손실로 L2(MSE)를 유지하면서 판별 손실을 보조적으로 사용해 학습 안정성을 확보한다. 셋째, GRL을 이용한 단순한 역전파 구조로 복잡한 GAN 훈련 루프를 피한다. 넷째, 매핑 네트워크에 RNN을, 판별기에 DNN을 사용해 각각 시간적 연속성 및 판별 정확도를 최적화한다. 이러한 설계는 비정상적 잡음 환경에서도 강인한 특징 변환을 가능하게 하며, 실시간 처리와 저전력 디바이스 적용을 위한 경량화 가능성도 시사한다.
결론적으로, AFM은 특징 매핑의 분포 정합성을 적대적 학습으로 보강함으로써 기존 MSE 기반 방법보다 뛰어난 음성 향상 효과를 제공한다. SA‑AFM은 이 구조에 센노 인식을 직접 결합해, 최종 ASR 성능까지 크게 향상시킨다. 향후 연구에서는 더 복잡한 잡음 유형, 멀티채널 입력, 그리고 경량화된 모델 설계 등을 통해 실시간 상용 서비스에 적용하는 방안을 탐색할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기