스피커 불변 학습을 통한 잡음 환경 자동음성인식 성능 향상
본 논문은 화자 간 변동성을 최소화하고 음소(센논) 구분력을 유지하기 위해, 음성 인식 DNN 모델과 화자 분류기를 동시에 학습시키는 적대적 다중작업 프레임워크인 스피커‑인버턴트 트레이닝(SIT)을 제안한다. 화자 분류 손실을 최대화하고 센논 분류 손실을 최소화함으로써 화자에 무관한 깊은 특징을 추출한다. CHiME‑3 데이터셋에서 기존 SI 모델 대비 4.99%의 WER 개선을 달성했으며, 추가적인 비지도 화자 적응을 적용하면 4.86%의 추…
저자: Zhong Meng, Jinyu Li, Zhuo Chen
본 연구는 화자 간 음성 특성 차이, 즉 인터‑스피커 변동성이 DNN 기반 자동음성인식(ASR) 시스템의 성능을 저해한다는 점에 착안하여, 이러한 변동성을 직접 억제하는 새로운 학습 프레임워크인 스피커‑인버턴트 트레이닝(SIT)을 제안한다. SIT는 두 개의 주요 네트워크, 즉 음성 인식용 DNN 음향 모델과 화자 분류용 DNN을 동시에 학습시키는 적대적 다중작업 구조를 채택한다.
먼저, 전체 DNN을 앞쪽 N_h개의 은닉층(M_f)과 뒤쪽 층(M_y)으로 분리한다. M_f는 입력 프레임을 깊은 특징 F로 변환하고, M_y는 이 특징을 이용해 센논(음소 상태) 확률을 예측한다. 동시에, 별도의 화자 분류기 M_s는 동일한 특징 F를 입력받아 화자 레이블에 대한 확률을 출력한다. 학습 목표는 두 손실을 결합한 총 손실 L_total = L_senone – λ·L_speaker 로 정의한다. 여기서 L_senone은 전통적인 교차 엔트로피 손실이며, L_speaker는 화자 레이블에 대한 교차 엔트로피이다. λ는 두 손실의 상대 중요도를 조절한다.
핵심은 M_f가 화자 분류 손실을 **극대화**하도록 학습되는 점이다. 이를 위해 Gradient Reversal Layer(GRL)를 도입해 역전파 시 M_f에 전달되는 기울기를 –λ배로 반전시킨다. 결과적으로 M_f는 화자 분류기 M_s가 화자를 구분하기 어려운 특징을 생성하도록 압박받으며, 동시에 M_y는 이러한 특징을 사용해 센논을 정확히 구분하도록 학습된다. 이 과정은 미니맥스 게임 형태로 수렴하며, 최종적으로 화자에 무관한, 센논 구분력이 높은 특징이 얻어진다.
실험은 CHiME‑3 데이터셋을 사용해 수행되었다. 데이터는 6채널 마이크로폰 어레이에서 녹음된 실제 및 시뮬레이션 잡음 환경을 포함하며, 훈련에는 9,137개의 잡음 섞인 발화가 사용되었다. 베이스라인은 7층, 각 층 2,048 유닛을 갖는 SI DNN‑HMM 모델이며, 입력은 87차원 로그 멜 필터뱅크와 그 1차·2차 델타, 그리고 5프레임 좌·우 컨텍스트를 포함한 957차원 벡터이다.
SIT 모델은 N_h=2, λ=3.0으로 설정하고, 화자 분류기 M_s는 2층, 각 512 유닛, 출력 87(훈련 화자 수)으로 구성하였다. 결과적으로 SIT 모델은 실험 셋에서 실시간(real)와 시뮬레이션(simulated) 모두에서 각각 16.95%와 16.54%의 WER를 기록했으며, 이는 기존 SI 모델(17.84%/17.72%) 대비 각각 4.99%와 6.66%의 상대 개선을 의미한다.
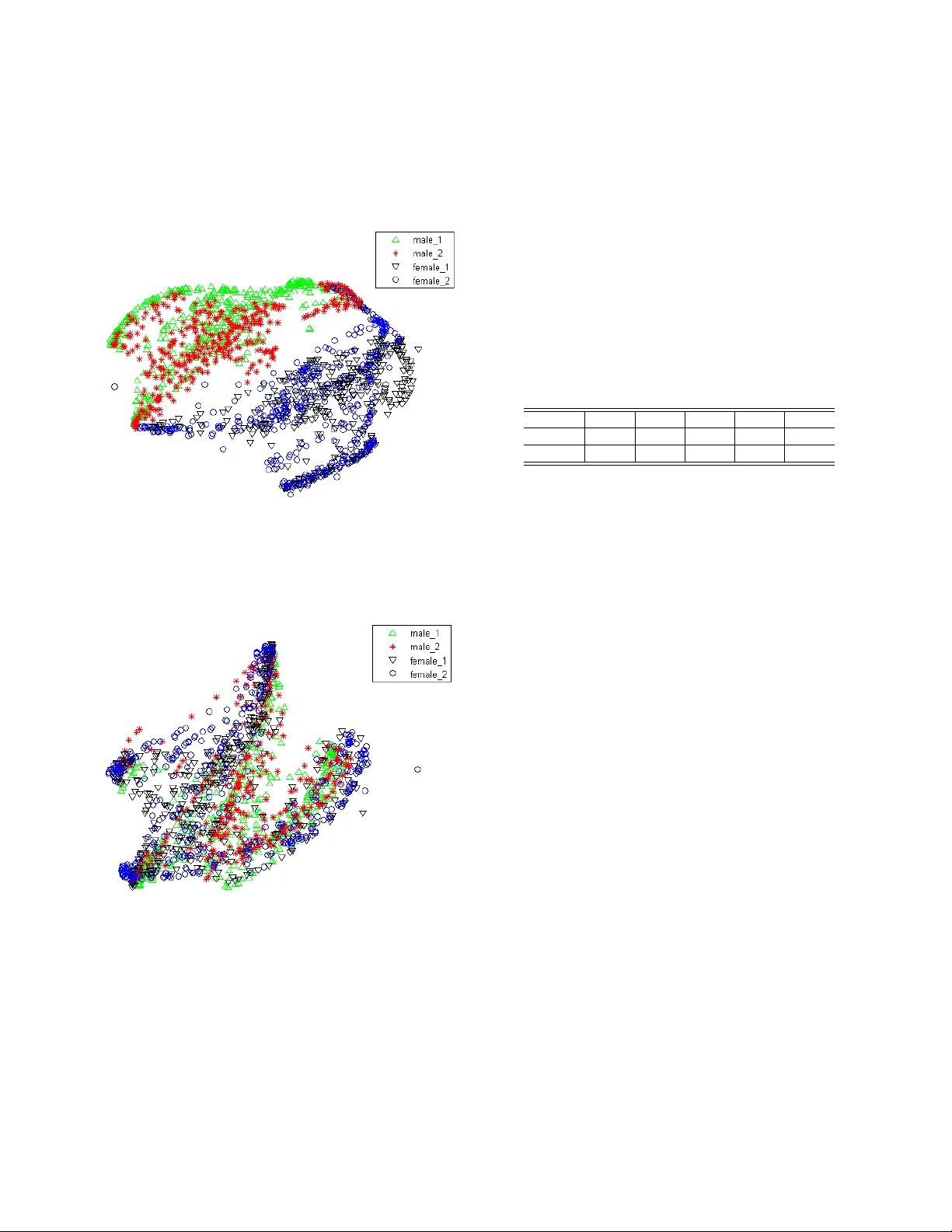
시각적 분석을 위해 t‑SNE를 이용해 “ah” 음소에 대한 깊은 특징을 시각화하였다. SI 모델에서는 남·여 화자 간, 그리고 동일 성별 내에서도 특징이 뚜렷이 구분되었으나, SIT 적용 후에는 모든 화자의 특징이 크게 겹쳐져 화자 불변성이 크게 향상된 것을 확인할 수 있었다.
추가 실험으로 비지도 화자 적응을 수행하였다. 여기서는 Constrained Re‑Training(CRT) 방식을 사용해 하위 2층만 재학습했으며, 1‑best 정렬을 1차 디코딩 결과로 활용하였다. 적응 후 SIT 모델은 15.46%의 WER를 달성했으며, 이는 동일 적응을 적용한 SI 모델 대비 4.86% 더 낮은 오류율을 보였다. 또한, 적응 전후 모두에서 약 8.8%의 상대 WER 감소가 관찰되었다.
이러한 결과는 SIT가 화자 변동성을 사전에 억제함으로써, 모델 자체가 보다 컴팩트하고 일반화 능력이 뛰어나며, 추가 적응 단계에서도 더 큰 이득을 제공한다는 것을 시사한다. 기존 방법들은 i‑vector 추정, 화자‑특정 변환, 다중 패스 디코딩 등 복잡한 절차가 필요했지만, SIT는 이러한 부가 요소 없이도 1패스 온라인 디코딩이 가능하고, 파라미터 수와 연산량이 크게 감소한다. 따라서 실시간 음성 인식 시스템이나 대규모 배포 환경에서 실용적인 장점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기